
二 unicode字型檔製作(智源GM813X多國語言OSD開發)
字型檔的製作關鍵是需要軟體,文章最後會提供一種字型檔製作軟體,此文將詳細介紹怎麼提取字型檔方法。
一 製作字型檔格式。
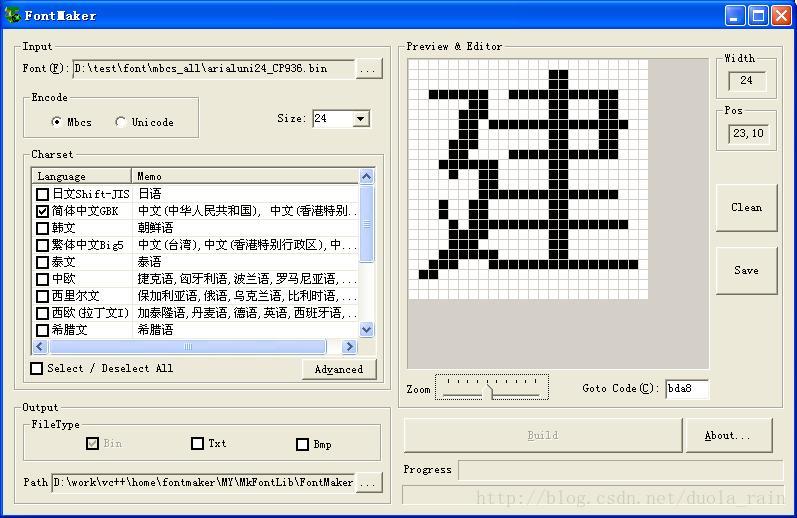
(該圖就是字型檔軟體主頁面,ENCODE 編碼選擇UNICODE ,size 可以選擇小一點的16x16的這樣字型檔空間大概是1.3M多一點,FileType 選擇BIN就好)
1. 轉換字型檔,操作步驟如下:
1). 選擇一個您要轉換的向量字型檔案(*.ttf)。
先將c:\windows\fonts 目錄下的字型檔案拷貝(ctrl+c)出來,然後本軟體即可選擇。
建議去網上找一個ArialUni.ttf字型檔(可找本人提供),目前linux系統用的就是這個,字元非常全面。
2). 選擇編碼型別(MBCS or Unicode),根據需求而定。
3). 選擇字型大小,根據需求而定,目前只支援16,24,32,40,48,56,本軟體可根據需求而改成大字型 ( > 56 )。
4). 選擇需要轉換的字符集(支援多選),根據需求而定。比如:我要用到簡體中文,則必須選簡體中文,同時還可選其它。
5). 選擇輸出檔案。(BIN 檔案始終預設輸出,其它可選)
6). 選擇輸出目錄,即將您生成的檔案存放到您選擇的這個目錄中。
7). 點選 build 按鈕,稍等片刻,即可生成您所想要的字型檔檔案。
注意: 如果您選擇的是MBCS 編碼方式,又有選擇多個字符集,則會輸出多份上述檔案。
如果您選擇的是NICODE編碼方式,不論你選多少個字符集,都只會輸出一份上述檔案。
如果生成字型檔失敗,則有可能你選擇的字型檔案(*.TTF)原本就不包含該字符集的字元資訊。 比如:宋體中不存在韓文字元,即用宋體生成的字型檔無法支援韓文顯示。
參考辦法: 對照系統自帶的字元對映表,裡面就可以選擇不同的字型,字符集(開啟“高階檢視”)進行參照。
開啟字元對映表的方法:
1. 以命令方式執行開啟,直接鍵入 "charmap"即可。
2. 程式-->附件-->系統工具--->字元對映表
2. 字型檔預覽,操作步驟如下:
1). 選擇一個您要預覽的字型檔檔案(*.bin)。將會自動開啟分析出其編碼型別,點陣大小,包含的字符集。
2). 在 goto code:後面的編輯框中,輸入您要檢視字元的編碼(如果當前選擇的字型檔*.BIN 是unicode編碼,則輸入unicode碼,否則輸入mbcs 編碼),回車後即可看到其顯示效果,還可得知其字元實際顯示寬度。
二 字型檔資訊資料。
1.支援所有 windows 字符集,詳情如下:
CP932, 日文Shift-JIS, 如:日語
CP936, 簡體中文GBK, 如:中文(中華人民共和國), 中文(香港特別行政區), 中文(新加坡)
CP949, 韓文, 如:朝鮮語
CP950, 繁體中文Big5, 如;中文(臺灣), 中文(澳門特別行政區)
CP874, 泰文, 如:泰語
CP1250, 中歐, 如:捷克語,匈牙利語,波蘭語,羅馬尼亞語,克羅埃西亞語,斯洛伐克語,阿爾巴尼亞語,斯洛維尼亞語,塞爾維亞語(拉丁文)
CP1251, 西里爾文, 如:保加利亞語,俄語,烏克蘭語,比利時語,馬其頓語(FYROM),哈薩克語,吉爾吉斯語,韃靼語,蒙古語,亞塞拜然語,烏茲別克語,塞爾維亞語
CP1252, 西歐(拉丁文I), 如:加泰隆語,丹麥語,德語,英語,西班牙語,芬蘭語,法語,冰島語,義大利語,荷蘭語,挪威語,葡萄牙語,印度尼西亞語,巴士克語,南非語,法羅語,馬來語,斯瓦希里語,加里西亞語,瑞典語
CP1253, 希臘文, 如:希臘語
CP1254, 土耳其文, 如:土耳其語,亞塞拜然語,烏茲別克語
CP1255, 希伯來文, 如:希伯來語
CP1256, 阿拉伯文, 如:烏都語,波斯語,阿拉伯語(伊拉克,埃及,利比亞,阿爾及利亞,摩洛哥,突尼西亞,阿曼,葉門,敘利亞,約旦,黎巴嫩,科威特,阿聯酋,巴林,卡達)
CP1257, 波羅的海文, 如:愛沙尼亞語,拉脫維亞語,立陶宛語,
CP1258, 越南, 如:越南語
unicode 可以由上述字符集根據需求自由合成。
2. 支援 BIN(*.bin), TXT(*.txt), BMP(*.bmp) 檔案輸出。
A. BIN 檔案,即字型檔檔案(必生成):儲存的是我們最終需要用到的點陣字型檔資訊。其檔案結構由四大部分組成:檔案頭、段資訊、檢索表、點陣資訊。
1). 檔案頭,指的是檔案的前十六個位元組(BYTE),描述資訊如下結構:
typedef struct tagFontLibHeader{
BYTE magic[4]; //'U'(or 'M'), 'F', 'L', X 'U'(or 'M')---Unicode(or MBCS) Font Library, X: 表示版本號. 分高低4位。如 0x12表示 Ver 1.2
DWORD Size; /* File total size */
BYTE nSection; //MBCS:是否包含檢索表。 Unicode:共分幾段資料
BYTE YSize; /* height of font */
WORD wCpFlag; // codepageflag: bit0~bit13 每個bit分別代表一個CodePage 標誌,如果是1,則表示當前CodePage 被選定,否則為非選定。
char reserved[4]; // 預留位元組
} FL_Header;
2). 段資訊,只針對 UNICODE 編碼有效,佔位元組數:nSection*sizeof(FL_SECTION_INF)。結構如下:
typedef struct tagFlSectionInfo{
WORD First; /* first character */
WORD Last; /* last character */
DWORD OffAddr; /* 指向的是當前SECTION包含的 UFL_CHAR_INFO第一個字元資訊的起始地址 */
} FL_SECTION_INF, *PFL_SECTION_INF;
3). 檢索表,只針對非等寬的MBCS(不包含簡中、繁中、日文、韓文,因這些都將等寬處理,故無需檢索表)和 UNICODE 字型檔有效。
typedef struct tagUflCharInfo{
#ifdef SUPPORT_MAX_FONT // 如採用大字型結構,最大可支援248點陣
DWORD OffAddr; // 當前字元點陣資料的起始地址
BYTE Width; // 字元點陣的畫素的寬度
#else
DWORD OffAddr : 26; // 當前字元點陣資料的起始地址
DWORD Width : 6; // 字元點陣的畫素的寬度( 目前最大支援 56 點陣)
#endif
} UFL_CHAR_INDEX;
如果是非等寬的MBCS字型檔,則佔位元組數為:0xff * sizeof(UFL_CHAR_INDEX);
如果是Unicode字型檔,則佔位元組數為:((xxx[0].Last - xxx[0].First + 1)+...+(xxx[nSection-1].Last - xxx[nSection-1].First + 1)) * sizeof(UFL_CHAR_INDEX);
4). 點陣資訊,即當前所有包含字符集中字元的點陣資訊集合。資料儲存方式為:橫向高到底位儲存。如: 10110011 00011010 即為 B3. 1A
例如:顯示編碼 code = xxxx 的字元。分為以下三種情況,分別操作步驟如下:
(1). 非等寬的MBCS字型檔
a. 先讀出FL_Header資訊;
b. 根據這個sizeof(FL_Header) + code * 2找到code的 UFL_CHAR_INDEX資訊;
c. 根據UFL_CHAR_INDEX的OffAddr再找到當前code的點陣資訊;
d. 最後根據FL_Header.Ysize、UFL_CHAR_INDEX.Width、以及點陣資訊即可show出當前字元。
(2). 等寬的 MBCS字型檔 (包括簡中、繁中、日文、韓文)
a. 先讀出FL_Header資訊;
b. 計算出code在當前字符集中的索引值(index),然後根據這個sizeof(FL_Header) + index * (FL_Header.Ysize/8*FL_Header.Ysize)找到code的點陣資訊;
c. 然後根據FL_Header.Ysize與點陣資訊即可show當前字元。
計算出當前code在你當前字符集(codepage)中位置,即索引值。此函式主要針對MBCS編碼中的簡中,繁中,日文,韓文,
static long GetPosWithMbcs(UINT code, UINT codepage)
{
long lIdx = -1;
BYTE R = (code >> 8) & 0xFF; //區碼
BYTE C = code & 0xFF; //位碼
switch(codepage)
{
case CP932: // 日文
if(R >= 0x81 && R <= 0x9F)
{
if(C >= 0x40 && C <= 0x7E)
lIdx = (R-0x81)*188 + (C-0x40); //188 = (0x7E-0x40+1)+(0xFC-0x80+1);
else if(C >= 0x80 && C <= 0xFC)
lIdx = (R-0x81)*188 + (C-0x80)+63; // 63 = 0x7E-0x40+1;
}
else if(R >= 0xE0 && R <= 0xFC)
{
if(C >= 0x40 && C <= 0x7E)
lIdx = 5828 + (R-0xE0)*188 + (C-0x40); // 5828 = 188 * (0x9F-0x81+1);
else if(C >= 0x80 && C <= 0xFC)
lIdx = 5828 + (R-0xE0)*188 + (C-0x80)+63;
}
break;
case CP936: // 簡中
if((R >= 0xA1 && R <= 0xFE) && (C >= 0xA1 && C <= 0xFE))
lIdx = (R-0xa1)*94 + (C-0xa1); //94 = (0xFE-0xA1+1);
break;
case CP949: // 韓文
if(R >= 0x81)
{
if(C >= 0x41 && C <= 0x7E)
lIdx = ((R-0x81) * 188 + (C - 0x41)); // 188 = (0x7E-0x41+1)+(0xFE-0x81+1);
else if(C >= 0x81 && C <= 0xFE)
lIdx = ((R-0x81) * 188 + (C - 0x81) + 62); // 62 = (0x7E-0x41+1);
}
break;
case CP950: // 繁中
if(R >= 0xA1 && R <= 0xFE)
{
if(C >= 0x40 && C <= 0x7E)
lIdx = ((R-0xa1)*157+(C-0x40)); // 157 = (0x7E-0x40+1)+(0xFE-0xA1+1);
else if(C >= 0xA1 && C <= 0xFE)
lIdx = ((R-0xa1)*157+(C-0xa1)+63); // 63 = (0x7E-0x40+1);
}
break;
default:
break;
}
return lIdx;
} (3). Unicode字型檔 (可以包括所有字符集)
a. 先讀出FL_Header資訊;
b. 分析當前字元在第幾段,比如在第n段,就可根據這個xxx[n].OffAddr+(code - xxx[n].First)* sizeof(UFL_CHAR_INDEX)找到字元索引資訊(UFL_CHAR_INDEX);
c. 根據UFL_CHAR_INDEX的OffAddr再找到當前code的點陣資訊;
d. 最後根據FL_Header.Ysize、UFL_CHAR_INDEX.Width、以及點陣資訊即可show出當前字元。
B. TXT 檔案(可選擇生成): 儲存的是當前字型檔包含字元的字模顯示效果。詳見轉換後結果。
C. BMP 檔案(可選擇生成): 是將當前字型檔中所有字元點陣資訊整合成的一個位圖檔案。(只針對 MBCS 編碼有效)詳見轉換後結果。
四、如何從字型檔檔案(*.bin)中獲取點陣資訊?
由於選擇的編碼型別(MBCS 或 Unicode)以及字符集不同,則輸出的字型檔檔案所包含的資料段也會不同。如下例表:
資料段 MBCS-CJK MBCS-非等寬 Unicode
-------------------------------------------------------------------
檔案頭 Y Y Y
段資訊 N N Y
檢索表 N Y Y
點陣資訊 Y Y Y
Y: 包含
N: 不包含
註釋:
MBCS: MultiByteCharset,即多位元組字符集(本地字符集)。
CJK: China,Japan,Korea,即中(簡體,繁體)日韓字符集。
非等寬: 每個字元的顯示寬度不等。 如字元'i','M'。 除了 CJK 外,其它都預設為非等寬字符集。
Unicode: 即統一編碼(寬位元組字符集)
具體舉例解析如下:
注意:
a. 資料都是低位在前,高位在後;
b. 寬高都以畫素為單位;
c. 字符集從低到高順序分別為:日文,簡中,韓文,繁中,泰文,中歐,西里爾,西歐,希臘,土耳其文,希伯來文,阿拉伯文,波羅的海文,越南文;
A. MBCS-CJK (等寬)
00000000h: 4D 46 4C 10 50 FE 03 00 00 10 02 00 00 00 00 00
00000010h: 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00
00000020h: 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00
00000030h: 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00
00000040h: 00 00 00 00 30 00 18 00 0C 00 04 00 00 00 00 00
...
解析如下:
1). 檔案頭 ( 前 16 Byte )
4D 46 4C 10 -- 標識頭,判斷是否為合法的字型檔檔案。
4D = 'M', 表示該檔案為 MBCS 編碼格式的字型檔檔案。
46 = 'F', 4C = 'L'
10 表示該字型檔檔案版本資訊為: Version 1.0
50 FE 03 00 -- 檔案總長度
00 -- 是否包含檢索表。 0-標識無檢索表
10 -- 字型高度 (寬高都以畫素為單位) 0x10 == 16
02 00 -- 選擇的字符集標誌位。 1-標識選擇, 0-標識未選擇. 故得出當前選擇為: 簡中字符集。
00 00 00 00 -- 預留位元組
2). 點陣資訊
因為GB2312 的首個字元:0xA1A1, 它的點陣資料起始地址為 0x10,資料長度為:((字型高度+7)/8)* 字型高度 = ((16+7)/8)*16 = 32.
故取如下 16 位元組,即為字元0xA1A1的點陣資訊。
00000010h: 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00
00000020h: 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00
同理如下即為字元0xA1A2的點陣資訊。
00000030h: 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00
00000040h: 00 00 00 00 30 00 18 00 0C 00 04 00 00 00 00 00
由於等寬,所以所有字元的點陣資料長度都為:((字型高度+7)/8)* 字型高度 = ?
B. MBCS-非等寬
Sample 子目錄下的檔案arialuni16_CP1252.bin, 檔案內容如下:
00000000h: 4D 46 4C 10 90 1A 00 00 01 10 80 00 00 00 00 00
00000010h: 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00
00000020h: 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00
00000030h: 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00
00000040h: 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00
00000050h: 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00
00000060h: 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00
00000070h: 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00
00000080h: 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00
00000090h: 10 04 00 10 20 04 00 10 30 04 00 18 40 04 00 24
...
00000410h: 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00
00000420h: 00 00 40 40 40 40 40 40 40 40 00 40 40 00 00 00
....
解析如下:
1). 檔案頭 ( 前 16 Byte )
4D 46 4C 10 -- 標識頭,判斷是否為合法的字型檔檔案。
4D = 'M', 表示該檔案為 MBCS 編碼格式的字型檔檔案。
46 = 'F', 4C = 'L'
10 表示該字型檔檔案版本資訊為: Version 1.0
90 1A 00 00 -- 檔案總長度
01 -- 是否包含檢索表。 1-標識有檢索表
10 -- 字型高度 0x10 == 16
80 00 -- 選擇的字符集標誌位。 1-標識選擇, 0-標識未選擇. 故得出當前選擇為: 西歐字符集。
00 00 00 00 -- 預留位元組
2). 檢索表
從 00000010h 開始,每 4 個位元組表示一個字元的檢索資訊, 且從字元 0x0 開始。故空格字元(' ')的檢索資訊(00000090h)為:10 04 00 10
即得出一個 32 位數為: 0x10000410(十六進位制) --- (00010000 00000000 00000100 00010000).
高 6 位,表示當前字元的寬度。 故得出 000100 -- 4 (字型檔寬度為 4 )
低 26 位, 表示當期字元的點陣資訊的偏移地址。故得出 00 00000000 00000100 00010000 -- 0x410 (點陣資訊的起始地址為 0x410)
3). 點陣資訊
由於空格字元的起始地址為 0x410,且資料長度為:((字型寬度+7)/8)* 字型高度 = ((4+7)/8)*16 = 16.
故取如下 16 位元組,即為空格字元的點陣資訊。
00000410h: 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00
同理如下即為字元'!' 的點陣資訊。
00000420h: 00 00 40 40 40 40 40 40 40 40 00 40 40 00 00 00
C. Unicode (具體請參閱檔案 .\Demo\ReadUnicode.c)
00000000h: 55 46 4C 10 28 AB 07 00 01 10 81 00 00 00 00 00
00000010h: 20 00 FF FF 18 00 00 00 98 FF 03 10 A8 FF 03 10
...
0003ff90h: 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00
0003ffa0h: 00 00 00 00 00 00 00 00 00 00 40 40 40 40 40 40
0003ffb0h: 40 40 00 40 40 00 00 00 00 00 48 48 48 48 00 00
...
解析如下:
1). 檔案頭 ( 前 16 Byte )
55 46 4C 10 -- 標識頭,判斷是否為合法的字型檔檔案。
55 = 'U', 表示該檔案為 UNICODE 編碼格式的字型檔檔案。
46 = 'F', 4C = 'L'
10 表示該字型檔檔案版本資訊為: Version 1.0
28 AB 07 00 -- 檔案總長度
01 -- 包含幾個Section。 1- 1 Section ( 在不包括CJK時,會分成3 Section)
10 -- 字型高度 0x10 == 16
81 00 -- 選擇的字符集標誌位。 1-標識選擇, 0-標識未選擇. 故得出當前選擇為: 日文+西歐字符集。
00 00 00 00 -- 預留位元組
2). 段資訊 (n section * sizeof(FL_SECTION_INF) = 1 * 8 = 8))
20 00 -- First character
FF FF -- Last character
18 00 00 00 -- OffAddr; /* 指向的是當前SECTION中First character對應的 UFL_CHAR_INDEX資訊的起始地址 */
3). 檢索表 ((Section[0].Last - Section[0].First + 1) * 4 + (Section[n-1].Last - Section[n-1].First + 1) * 4)
每 4 個位元組表示一個字元的檢索資訊, 且從字元Section[0].First 開始。故字元0x20的檢索資訊(起始地址 =
(字元的unicode碼 - Section[x].First) × 4 + Section[x].OffAddr, x 為當前字元處在的section索引值,可判斷得出。)為:98 FF 03 10
即得出一個 32 位數為: 0x1003FF98(十六進位制) --- (00010000 00000011 11111111 10011000).
高 6 位,表示當前字元的寬度。 故得出 000100 -- 4 (字型檔寬度為 4 )
低 26 位, 表示當期字元的點陣資訊的偏移地址。故得出 00 00000011 11111111 10011000 -- 0x3FF98 (點陣資訊的起始地址為 0x3FF98)
3). 點陣資訊
由於空格字元的起始地址為 0x3FF98,且資料長度為:((字型寬度+7)/8)* 字型高度 = ((4+7)/8)*16 = 16.
故取如下 16 位元組,即為空格字元的點陣資訊。
0003ff98h: 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00
同理如下即為字元0x21 的點陣資訊。
0003ffA8h: 00 00 40 40 40 40 40 40 40 40 00 40 40 00 00 00