
【opencv學習之四十三】K均值聚類演算法
阿新 • • 發佈:2019-01-03
K均值聚類演算法,在opencv中通過kmeans()函式實現;k均值通俗講:就是從一堆樣本中,隨便挑出幾個,比如3個吧,然後用樣本中的和這挑出來的比較,比較後排序,誰和挑出的那個接近就把他劃到那個類裡,比如樣A和挑1、挑2、挑3中,挑2最接近,則把樣A劃到挑2裡,當然還沒完事,還得再對挑完的3個類群,確定一個類群代表——“均值”,然後以這3個新的代表——“均值”再次與樣本對比,直到“均值”不在變了,則迭代終止,聚類完成了;
用數學解釋如下:

當然上面是在別處截的圖,具體如何用演算法實現,如何用數學表達,感興趣的同學可以看專業資料;K均值聚類演算法,對於簡單的影象處理應用是可以的,比如簡單分割影象什麼的;主要k均值要找到所有可能的分類,然後找到最優解花費時間不是一點點了;甚至你給隨機樣本(沒有意義),k均值也能聚類,劃分的結果並不一定是你想要的,因為劃分規則不同,劃分的結果也是不同的;
下面簡單例項:
1、產生隨機數然後用k均值聚類;
///////////////////////////////////////////// //1.k_means K均值聚類 ///////////////////////////////////////////// #define WINDOW_1 "Before cluster" #define WINDOW_2 "After cluster" Mat dstIamge(500, 500, CV_8UC3); Mat A_dstIamge = dstIamge/*.clone()*/; RNG rng(12345); //隨機數產生器 int clusterCount; int sampleCount; int MIN_SAMPLECOUNT = 400, MIN_SLUSTERCOUNTS = 5; void cluster(int, void*) { Scalar colorTab[] = //最多顯示7類有顏色的,所以最多也就給7個顏色 { Scalar(0, 0, 255), Scalar(0, 255, 0), Scalar(0, 255, 255), Scalar(255, 0, 0), Scalar(255, 255, 0), Scalar(255, 0, 255), Scalar(255, 255, 255), Scalar(200, 200, 255), }; clusterCount = rng.uniform(2, MIN_SLUSTERCOUNTS + 1);//產生之間的整數個類別! sampleCount = rng.uniform(1, MIN_SAMPLECOUNT + 1);//產生1到1001個整數樣本數,也就是一千個樣本 Mat points(sampleCount, 1, CV_32FC2), labels; //產生的樣本數,實際上為2通道的列向量,元素型別為Point2f clusterCount = MIN(clusterCount, sampleCount); Mat centers(clusterCount, 1, points.type()); //用來儲存聚類後的中心點 /* generate random sample from multigaussian distribution */ for (int k = 0; k < clusterCount; k++) // Generate random points { Point center;// Random point coordinate center.x = rng.uniform(0, dstIamge.cols); center.y = rng.uniform(0, dstIamge.rows); Mat pointChunk = points.rowRange(k*sampleCount / clusterCount, k == clusterCount - 1 ? sampleCount : (k + 1)*sampleCount / clusterCount); //最後一個類的樣本數不一定是平分的, //剩下的一份都給最後一類 // Each of the classes is the same variance, but the mean is different. rng.fill(pointChunk, CV_RAND_NORMAL, Scalar(center.x, center.y),//the mean Scalar(dstIamge.cols*0.05, dstIamge.rows*0.05)); //the same variance } randShuffle(points, 1, &rng); //因為要聚類,所以先隨機打亂points裡面的點,注意points和pointChunk是共用資料的。 dstIamge = Scalar::all(0); for (int i = 0; i < sampleCount; i++) { Point p = points.at<Point2f>(i);// Coordinates of corresponding points circle(A_dstIamge, p, 1, Scalar::all(255), CV_FILLED, CV_AA); } imshow(WINDOW_1, A_dstIamge); kmeans(points, clusterCount, labels,//labels表示每一個樣本的類的標籤,是一個整數,從0開始的索引整數,是簇數. TermCriteria(CV_TERMCRIT_EPS + CV_TERMCRIT_ITER, 10, 1.0),//用最大迭代次數或者精度作為迭代條件,看哪個條件先滿足 3, //聚類3次,取結果最好的那次, KMEANS_PP_CENTERS,//則表示為隨機選取初始化中心點,聚類的初始化採用PP特定的隨機演算法。 centers); //引數centers表示的是聚類後的中心點存放矩陣。 // Traverse each point for (int i = 0; i < sampleCount; i++) { int clusterIdx = labels.at<int>(i);// A label has been completed by clustering Point p = points.at<Point2f>(i);// Coordinates of corresponding points circle(dstIamge, p, 1, colorTab[clusterIdx], CV_FILLED, CV_AA); } imshow(WINDOW_2, dstIamge); } void Ml_Kmeans()//39.k_means K均值聚類 { while (1) { namedWindow(WINDOW_1, WINDOW_AUTOSIZE); createTrackbar("samleCounts: ", WINDOW_1, &MIN_SAMPLECOUNT, 1000, cluster); cluster(0, 0); createTrackbar("clusterCounts: ", WINDOW_1, &MIN_SLUSTERCOUNTS, 10, cluster); cluster(0, 0); char key = (char)waitKey(); //wait forever if (key == 27 || key == 'q' || key == 'Q') break; } }
執行結果如下:
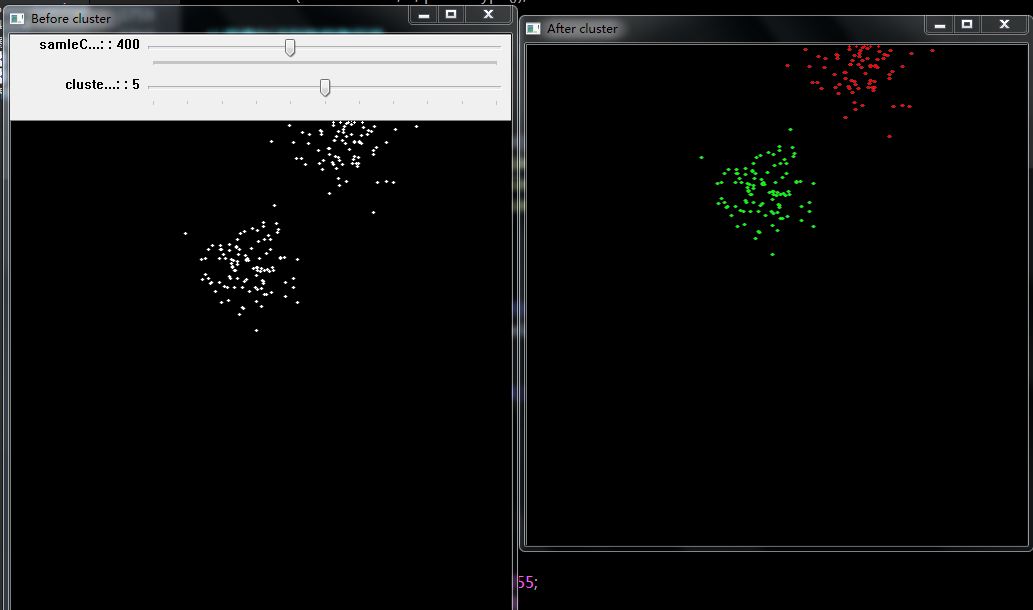
2、對影象進行K均值聚類:
/////////////////////////////////// //k均值主要是一種聚類演算法,簡單說就是將一個樣本里的內容進行分類處理; //在影象處理時候經常要主動定義和查詢特徵,比如閾值分割什麼的,但是 //k均值不用定義特徵,而是把特徵相似的分類了; //所以我們不用關心特徵是什麼,因為k均值已經區分特徵;但是說來很理想, //事實上分類出來或者分割出來的並不一定是理想中的樣子 //////////////////////////////////// void Ml_Kmeans2()//39.k_means K均值聚類2 { Mat src = imread("D:/ImageTest/test2.jpg"); imshow("input", src); int width = src.cols; int height = src.rows; int dims = src.channels(); // 初始化定義 int sampleCount = width*height; int clusterCount = 4; Mat points(sampleCount, dims, CV_32F, Scalar(10)); Mat labels; Mat centers(clusterCount, 1, points.type()); // 影象RGB到資料集轉換 int index = 0; for (int row = 0; row < height; row++) { for (int col = 0; col < width; col++) { index = row*width + col; Vec3b rgb = src.at<Vec3b>(row, col); points.at<float>(index, 0) = static_cast<int>(rgb[0]); points.at<float>(index, 1) = static_cast<int>(rgb[1]); points.at<float>(index, 2) = static_cast<int>(rgb[2]); } } // 執行K-Means資料分類 TermCriteria criteria = TermCriteria(CV_TERMCRIT_EPS + CV_TERMCRIT_ITER, 10, 1.0); kmeans(points, clusterCount, labels, criteria, 3, KMEANS_PP_CENTERS, centers); // 顯示影象分割結果 Mat result = Mat::zeros(src.size(), CV_8UC3); for (int row = 0; row < height; row++) { for (int col = 0; col < width; col++) { index = row*width + col; int label = labels.at<int>(index, 0); if (label == 1) { result.at<Vec3b>(row, col)[0] = 255; result.at<Vec3b>(row, col)[1] = 0; result.at<Vec3b>(row, col)[2] = 0; } else if (label == 2) { result.at<Vec3b>(row, col)[0] = 0; result.at<Vec3b>(row, col)[1] = 255; result.at<Vec3b>(row, col)[2] = 0; } else if (label == 3) { result.at<Vec3b>(row, col)[0] = 0; result.at<Vec3b>(row, col)[1] = 0; result.at<Vec3b>(row, col)[2] = 255; } else if (label == 0) { result.at<Vec3b>(row, col)[0] = 0; result.at<Vec3b>(row, col)[1] = 255; result.at<Vec3b>(row, col)[2] = 255; } } } imshow("kmeans-demo", result); waitKey(0); }
執行結果:
