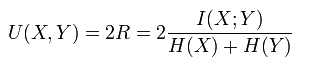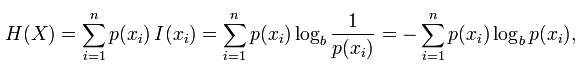聚類演算法評價指標
一、Not Given Label:
1、Compactness(緊密性)(CP)
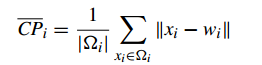
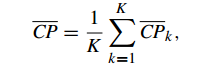
CP計算 每一個類 各點到聚類中心的平均距離
CP越低意味著類內聚類距離越近
缺點:沒有考慮類間效果
2、Separation(間隔性)(SP)
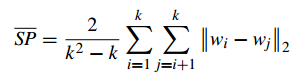
SP計算 各聚類中心兩兩之間平均距離
SP越高意味類間聚類距離越遠
缺點:沒有考慮類內效果
3、Davies-Bouldin Index(戴維森堡丁指數)(分類適確性指標)(DB)(DBI)
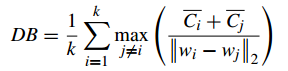
DB計算 任意兩類別的類內距離平均距離(CP)之和除以兩聚類中心距離 求最大值
DB越小意味著類內距離越小 同時類間距離越大
缺點:因使用歐式距離 所以對於環狀分佈 聚類評測很差
4、Dunn Validity Index (鄧恩指數)(DVI)
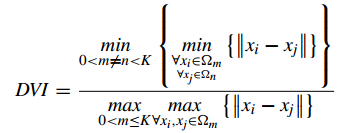
DVI計算 任意兩個簇元素的最短距離(類間)除以任意簇中的最大距離(類內)
DVI越大意味著類間距離越大 同時類內距離越小
缺點:對離散點的聚類測評很高、對環狀分佈測評效果差
二、Given Label:
1、Cluster Accuracy (準確性)(CA)
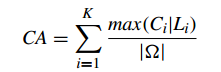
CA計算 聚類正確的百分比
CA越大證明聚類效果越好
2、Rand index(蘭德指數)(RI) 、Adjusted Rand index(調整蘭德指數)(ARI)
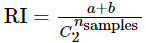
其中C表示實際類別資訊,K表示聚類結果,a表示在C與K中都是同類別的元素對數,b表示在C與K中都是不同類別的元素對數
其中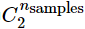
RI越大表示聚類效果準確性越高 同時每個類內的純度越高
為了實現“在聚類結果隨機產生的情況下,指標應該接近零”,調整蘭德係數(Adjusted rand index)被提出,它具有更高的區分度:
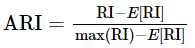
ARI取值範圍為[−1,1],值越大意味著聚類結果與真實情況越吻合。從廣義的角度來講,ARI衡量的是兩個資料分佈的吻合程度。
3、Normalized Mutual Information (標準互資訊)(NMI)、Mutual Information(互資訊)(MI)
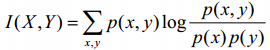
標準化互聚類資訊都是用熵做分母將MI值調整到0與1之間,一個比較多見的實現是下面所示: