
java初試爬蟲jsoup爬取縱橫小說免費模組
java初試爬蟲jsoup爬取縱橫小說免費模組
之前一直學習java ee,上個月到深圳工作,被招去做java爬蟲,於是自己學著jsoup,寫了個簡單的爬蟲
因為平時喜歡看小說就爬了縱橫。
將整個過程分為了
1. 獲取當前頁小說列表的詳細資料
2. 切換到下一分頁的列表
3. 獲取當前章的內容
4. 切換到下一章再重複 3
獲取當前頁小說列表的詳細資料 與切換到下一分頁的列表
先上程式碼
public class Book { private String name;//書名 private String author;//作者 private String classify;//書分類 private String url;//書的url private String path;//儲存路徑

開啟縱橫免費已完結的頁碼,第一頁,然後發現點選第二頁後 URL變化的
由 http://book.zongheng.com/store/c0/c0/b0/u0/p1/v0/s1/t0/u0/i1/ALL.html
變為http://book.zongheng.com/store/c0/c0/b0/u0/p2/v0/s1/t0/u0/i1/ALL.html
於是用佔位符 替換了
http://book.zongheng.com/store/c0/c0/b0/u0/p/v0/s1/t0/u0/i1/ALL.html
再從爬取的分頁元件中獲取到對應的最大頁數,遍歷頁數進行全部爬取
在換頁之前,先將本頁的小說爬取下來,我獲得了點選書名的跳轉連結與書名,作者,分類,將其儲存到Book實體中,再放入BlockingQueue中,開啟多執行緒去爬取每一個小說
import org.jsoup.Connection; import org.jsoup.Jsoup; import org.jsoup.nodes.Document; import org.jsoup.nodes.Element; import org.jsoup.select.Elements; import java.io.IOException; import java.util.Iterator; import java.util.concurrent.BlockingQueue; import java.util.concurrent.ExecutorService; import java.util.concurrent.Executors; import java.util.concurrent.LinkedBlockingDeque; public class ZhongHeng { private final String listUrl = "http://book.zongheng.com/store/c0/c0/b0/u0/p<number>/v0/s1/t0/u0/i1/ALL.html"; private BlockingQueue<Book> books = new LinkedBlockingDeque<>(); private String path; private int num; private void getList(int page,int total) throws IOException { String url = listUrl.replaceAll("<number>",String.valueOf(page)); Connection con = Jsoup.connect(url); Document dom = con.header("Accept","text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8") .header("Accept-Encoding"," gzip, deflate") .header("Accept-Language","zh-CN,zh;q=0.9") .header("Cache-Control","max-age=0") .header("Connection","keep-alive") .header("Upgrade-Insecure-Requests","1") .header("User-Agent","Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.110 Safari/537.36").get(); Elements bookbox = dom.getElementsByClass("bookbox"); Iterator<Element> iterator = bookbox.iterator(); while (iterator.hasNext()){ Element element = iterator.next(); //獲取書名和Url Elements bookNameA = element.select(".bookname").select("a"); String boolUrl = bookNameA.attr("href"); String bookName = bookNameA.text(); //獲取作者和分類 Elements bookilnkA = element.select(".bookilnk").select("a"); String author = bookilnkA.get(0).text(); String classify = bookilnkA.get(1).text(); Book book = new Book(bookName,author,classify,boolUrl,path); books.add(book); } if (total == -1){ //獲取頁碼 Elements tota = dom.getElementsByClass("pagenumber"); String totalStr = tota.attr("count"); total = Integer.valueOf(totalStr); if (num != 0 && total>num){ total = num; } } if (page >= total){ getBook(); return; } page++; url = listUrl.replaceAll("[number]",String.valueOf(page)); getList(page,total); } private void getBook(){ BookCrawl c1 = new BookCrawl(books); ~ BookCrawl c10 = new BookCrawl(books); ExecutorService service = Executors.newCachedThreadPool(); service.execute(c1); ~ service.execute(c10); } public int getNum() { return num; } public void setNum(int num) { this.num = num; } public String getPath() { return path; } public void setPath(String path) { this.path = path; } public static void main(String[] args) { ZhongHeng z = new ZhongHeng(); z.setNum(100);//爬取多少頁 z.setPath("D:\\縱橫中文網爬取小說");//儲存位置 try { z.getList(1,-1); } catch (IOException e) { e.printStackTrace(); } } }
獲取當前章的內容

通過圖片所示,這是之前列表獲取的url連結,點選開始閱讀後進入小說第一章
進入第一章後

發現章節名都存在class=title_txtbox 的div內,內容放在class=content的div內,且根據p標籤換行,我們獲取下來,遍歷content內的p標籤,放入stringBuilder中,並每行加入換行符。
獲取完本章內容後,存入text檔案中。
切換到下一章再重複 獲取小說的步驟

通過下一章按鈕可以獲取到下一章的網址,通過遞迴跳入下一章進行爬取,
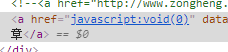
當下一章的href地址為 javascript:void(0) 說明已經到了小說最後一章跳出本小說爬取,獲取佇列內的另一小說進行爬取
小說的儲存地址根據填寫的地址加上小說分類進行儲存,已經存在相同小說時停止本小說爬取
import org.jsoup.Connection;
import org.jsoup.helper.StringUtil;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
import org.jsoup.select.Elements;
import java.io.BufferedWriter;
import java.io.File;
import java.io.FileWriter;
import java.io.IOException;
import java.util.HashMap;
import java.util.Iterator;
import java.util.Map;
import java.util.concurrent.BlockingQueue;
public class BookCrawl implements Runnable{
private String firstUrl ;
private BlockingQueue<Book> books ;
private Map<String, String> cookieMap = new HashMap<>();
private String filePath;
public BookCrawl(BlockingQueue<Book> books) {
this.books = books;
}
public void controller() {
if (books.isEmpty()){
return;
}
Book book = null;
try {
book = books.take();
} catch (InterruptedException e) {
e.printStackTrace();
}
if (StringUtil.isBlank(book.getPath())){
System.out.println("檔案地址不可為空");
return;
}
this.filePath = book.getPath()+"\\"+book.getClassify() +"\\"+book.getName()+".txt";
String filePaths = book.getPath()+"\\"+book.getClassify();
if (StringUtil.isBlank(book.getUrl())){
System.out.println("小說url不可為空");
return;
}
try {
File file = new File(filePath);
if (file.exists()) {
System.out.println("---- 已存在"+filePath+" ----");
return;
}else {
File file1 = new File(filePaths);
file1.mkdirs();
file.createNewFile();
}
index(book.getUrl());
} catch (IOException e) {
e.printStackTrace();
}
}
//縱橫中文網首頁
private void index(String url) throws IOException {
System.out.println("---- 進入小說主頁 ----");
Connection con = org.jsoup.Jsoup.connect(url);
Connection.Response response = con.header("Upgrade-Insecure-Requests", "1")
.header("User-Agent", "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.110 Safari/537.36")
.header("Accept", "text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8")
.header("Accept-Language", "zh-CN,zh;q=0.9").method(Connection.Method.GET).execute();
Map<String, String> cookies = response.cookies();
cookieMap.putAll(cookies);
firstUrl = response.parse().getElementsByClass("read-btn").attr("href");
System.out.println("---- 開始爬取小說 ----");
crawl(firstUrl);
}
//爬取小說
private void crawl(String url) throws IOException {
Connection con = org.jsoup.Jsoup.connect(url);
Connection.Response response = con.header("Upgrade-Insecure-Requests", "1")
.header("User-Agent", "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.110 Safari/537.36")
.header("Accept", "text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8")
.header("Accept-Language", "zh-CN,zh;q=0.9")
.header("Accept-Encoding", "gzip,deflate")
.cookies(cookieMap)
.method(Connection.Method.GET).execute();
if (response.statusCode() != 200) {
throw new RuntimeException("返回失敗");
}
Map<String, String> cookies = response.cookies();
cookieMap.putAll(cookies);
StringBuilder builder = new StringBuilder();
Document dom = response.parse();
String title = dom.getElementsByClass("title_txtbox").html();
builder.append(title);
builder.append(System.getProperty("line.separator"));
builder.append(System.getProperty("line.separator"));
Elements content = dom.getElementsByClass("content");
Iterator<Element> iterator = content.select("p").iterator();
while (iterator.hasNext()) {
String text = iterator.next().text();
builder.append(text);
builder.append(System.getProperty("line.separator"));
}
save(builder.toString(),title);
String nextUrl = dom.getElementsByClass("nextchapter").attr("href");
if (nextUrl.equals("javascript:void(0)")){
System.out.println("---- 小說爬取完畢 ----");
return;
}
crawl(nextUrl);
}
//儲存小說
private void save(String text,String title) throws IOException {
FileWriter fw=new FileWriter(filePath,true);
BufferedWriter bw = new BufferedWriter(fw);
bw.append(text);
bw.close();
fw.close();
}
public String getFirstUrl() {
return firstUrl;
}
public void setFirstUrl(String firstUrl) {
this.firstUrl = firstUrl;
}
public String getFilePath() {
return filePath;
}
public void setFilePath(String filePath) {
this.filePath = filePath;
}
@Override
public void run() {
controller();
}
}
//GET / HTTP/1.1
// Host: www.zongheng.com
// Connection: keep-alive
// Cache-Control: max-age=0
// Upgrade-Insecure-Requests: 1
// User-Agent: Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.110 Safari/537.36
// Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8
/*
gzipAccept-Encoding: gzip, deflate
Accept-Language: zh-CN,zh;q=0.9
Cookie: ZHID=5462A809F0C59C25793CD34E1E890C5B; ver=2018; zh_visitTime=1546409556362; zhffr=www.baidu.com; v_user=https%3A%2F%2Fwww.baidu.com%2Flink%3Furl%3D-vpjW5-L5AhYC60PBUteUaj2YUi8kPMl6GZfG-EdFpkSKP-sDZqFtF_OvJPKmQT1%26wd%3D%26eqid%3Dac37315a00017d8e000000055c2c564e%7Chttp%3A%2F%2Fwww.zongheng.com%2F%7C2933297; UM_distinctid=1680d3139de16-0c7dbc28aefbb9-424e0b28-1fa400-1680d3139df819; CNZZDATA30037065=cnzz_eid%3D1886041116-1546408366-null%26ntime%3D1546408366; Hm_lvt_c202865d524849216eea846069349eb9=1546409557; Hm_lpvt_c202865d524849216eea846069349eb9=1546409557
*/

執行後,想爬取17頁的縮影小說,被發現異常訪問,要輸入驗證碼,之前只爬取2頁小說的時候沒有這種問題,遇到反爬機制了,接下來,想接著嘗試嫩不嫩識別驗證碼,但識別驗證碼的程式碼剛獲得許可權,看完之後得看看會不會牽扯到公司的保密,不會的話再更新使用驗證碼的程式碼,希望填了驗證碼後,不要再出來個ip限制反爬,第一次寫爬蟲,有什麼能改進的歡迎大神指出
完整程式碼:javaJsoup初試爬取縱橫中文網