
深入理解yield(二):yield與協程
- 本文地址:http://beginman.github.io
- 轉載請註明出處
協程概念
1.併發程式設計的種類:多程序,多執行緒,非同步,協程
2.程序,執行緒,協程的概念區別:
程序:擁有自己獨立的堆和棧,既不共享堆也不共享棧,程序由作業系統排程。
執行緒:執行緒擁有自己獨立的棧和共享的堆,共享堆,不共享棧,執行緒亦由作業系統排程(標準執行緒是的)。
協程:協程和執行緒一樣共享堆,不共享棧,協程由程式設計師在協程的程式碼裡顯式排程
3.協程:
協程可以認為是一種使用者態的執行緒,與系統提供的執行緒不同點是,它需要主動讓出CPU時間,而不是由系統進行排程,即控制權在程式設計師手上。
4.程序,執行緒,協程在python中的表現
關於程序,python有multiprocessing模組進行處理;關於執行緒,python的Thread和Threading處理;關於非同步,有各種python框架如Tornado等呼叫linux下的select,poll,epoll等非同步實現;關於協程,由yield來實現。
5.協程與yield
1).子程式呼叫通過棧實現,一個執行緒執行一個子程式,有明確的執行順序,而協程不同於此,協程看上去也是子程式,但執行過程中,在子程式內部可中斷,然後轉而執行別的子程式,在適當的時候再返回來接著執行。注意的一點是:如A,B兩個子程式, A執行過程中可以去執行B,並不是呼叫B,B可以中斷(掛起)轉而回到A.
所以可以看到執行過程在A,B兩個子程式中切換,但是A並沒有呼叫B,B的中斷可以通過yield來儲存,A,B的執行過程像多執行緒,但是協程的特點在於一個執行緒執行。
2).協程的優勢:
最大的優勢就是協程極高的執行效率。因為子程式切換不是執行緒切換,而是由程式自身控制,因此,沒有執行緒切換的開銷,和多執行緒比,執行緒數量越多,協程的效能優勢就越明顯。
第二大優勢就是不需要多執行緒的鎖機制,因為只有一個執行緒,也不存在同時寫變數衝突,在協程中控制共享資源不加鎖,只需要判斷狀態就好了,所以執行效率比多執行緒高很多。
因為協程是一個執行緒執行,那怎麼利用多核CPU呢?最簡單的方法是多程序+協程,既充分利用多核,又充分發揮協程的高效率,可獲得極高的效能。
下面通過多執行緒的生產者消費者與協程的生產者消費者例項進行演示:
# 多執行緒# coding=utf-8from threading importThreadfrom threading importConditionimport time
import random
#為了達到理解效果,這裡沒有使用簡便的Queue
queue =[]
condition =Condition()
MAX_LENGTH =20#程式碼例項:http://blog.jobbole.com/52412/#生產者的工作是產生一塊資料,放到buffer中,如此迴圈。#與此同時,消費者在消耗這些資料(例如從buffer中把它們移除),每次一塊。#這裡的關鍵詞是“同時”。所以生產者和消費者是併發執行的,我們需要對生產者和消費者做執行緒分離。#這個為描述了兩個共享固定大小緩衝佇列的程序,即生產者和消費者。classProducerThread(Thread):def run(self):
nums = range(5)global queue
whileTrue:
num = random.choice(nums)
condition.acquire()# 鎖定以生成資料if len(queue)== MAX_LENGTH:print u'佇列已滿,等待消費中...'
condition.wait()# 執行緒等待
queue.append(num)# 往佇列中生成資料print"Produced", num
condition.notify()# 通知執行緒等待的消費者消費資料
condition.release()# 釋放執行緒鎖
time.sleep(random.random())classConsumerThread(Thread):def run(self):global queue
whileTrue:
condition.acquire()#執行緒鎖ifnot queue:print u"佇列為空,等待生產者生成資料...."
condition.wait()# 執行緒等待
num = queue.pop(0)# 消費資料print"Consumed", num
condition.notify()# 通知執行緒等待的生產者繼續生成資料(生產者執行緒等待條件是佇列已滿)
condition.release()# 釋放執行緒鎖
time.sleep(2)#執行時間長點,讓生產者生成更多資料來測試ProducerThread().start()ConsumerThread().start()傳統的生產者-消費者模型是一個執行緒寫訊息,一個執行緒取訊息,通過鎖機制控制佇列和等待,但一不小心就可能死鎖。
下面改用協程的方式:
# 協程#生產者生產訊息後,直接通過yield跳轉到消費者開始執行,待消費者執行完畢後,切換回生產者繼續生產,效率極高:def consumer():
v =Nonewhile1:
m =yield v
ifnot m:returnprint"[C]CLine:%s, CProduce:%s"%(m, v)
v ='range'def producter():
i =0
c = consumer()
c.next()# To avoid sending a non-None value to a just-started generator, you need to call next or send(None) first.while i <5:try:
i +=1print(u'[P]producing...%s'% i)
v = c.send(i)print(u'[P]CReturn: %s'% v)exceptStopIteration:print'Done!'break
c.close()if __name__ =='__main__':
producter()執行結果如下:
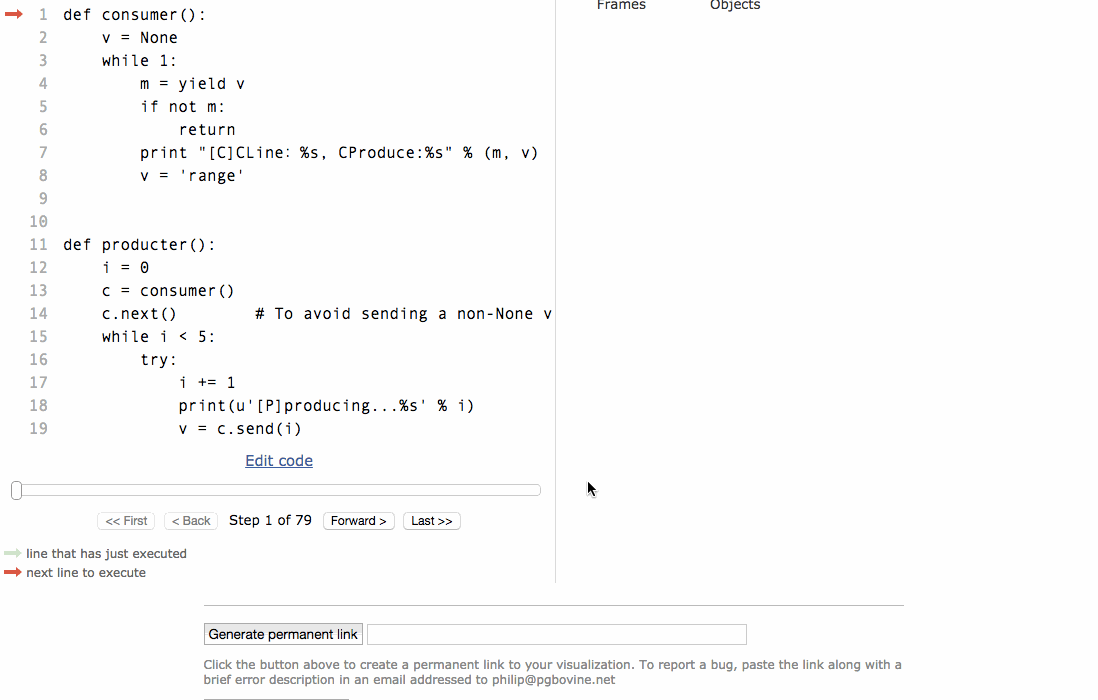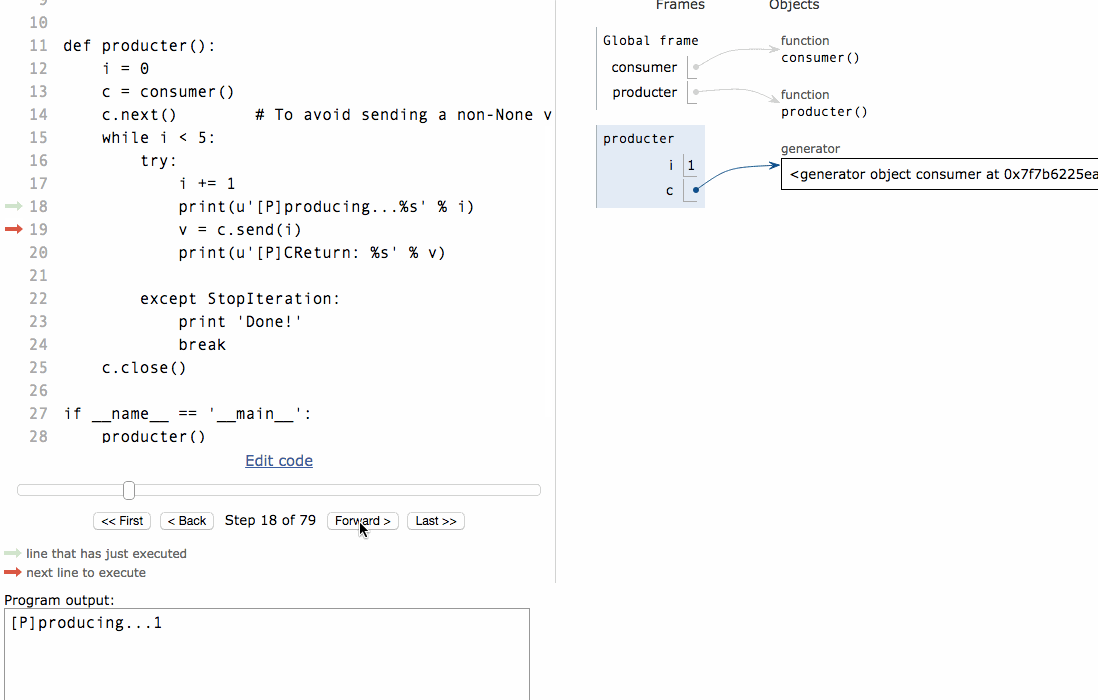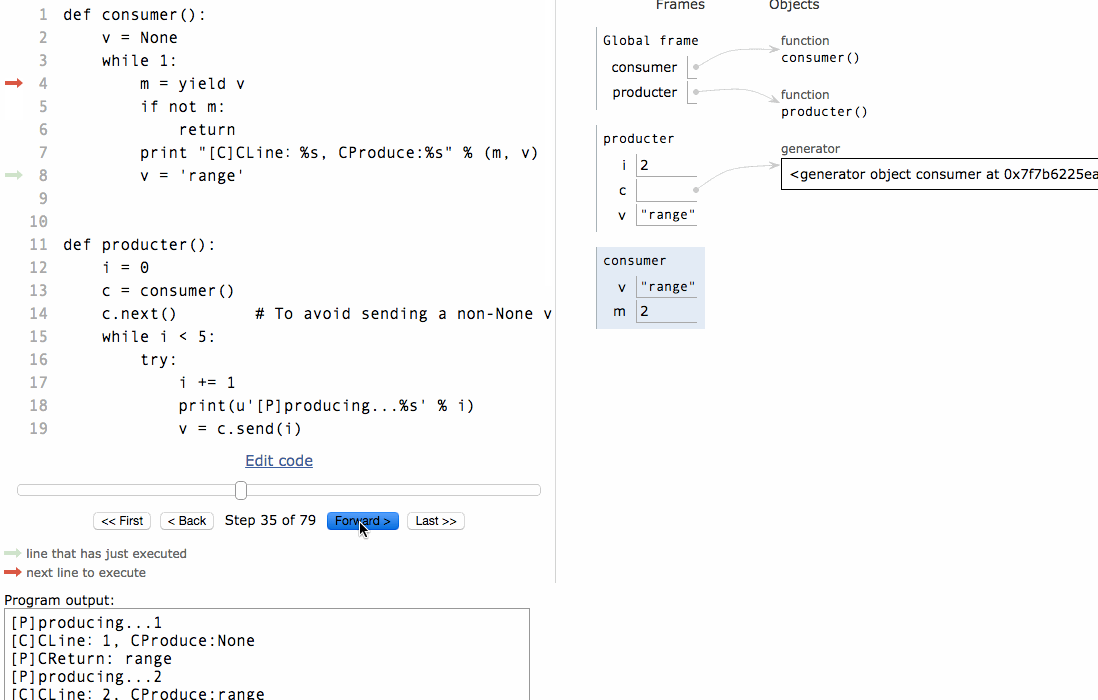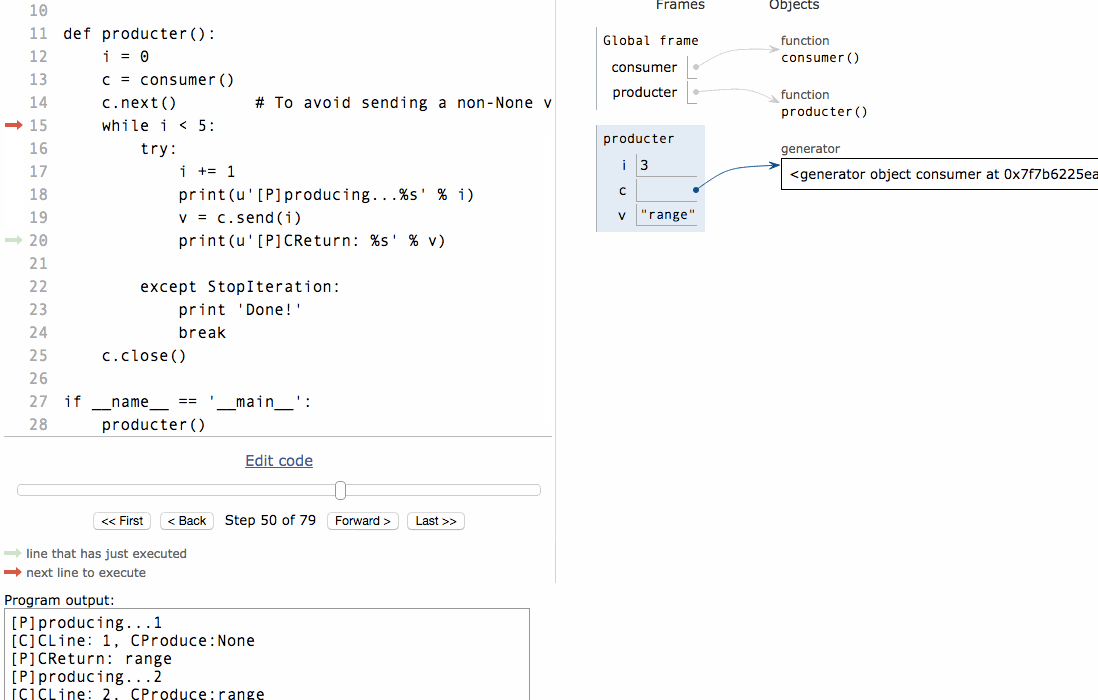
[P]producing...1[C]CLine:1,CProduce:None[P]CReturn: range
[P]producing...2[C]CLine:2,CProduce:range
[P]CReturn: range
[P]producing...3[C]CLine:3,CProduce:range
[P]CReturn: range
[P]producing...4[C]CLine:4,CProduce:range
[P]CReturn: range
[P]producing...5[C]CLine:5,CProduce:range
[P]CReturn: range引用廖雪峰python協程的理解:
注意到consumer函式是一個generator(生成器),把一個consumer傳入produce後:
首先呼叫c.next()啟動生成器;
然後,一旦生產了東西,通過c.send(n)切換到consumer執行;
consumer通過yield拿到訊息,處理,又通過yield把結果傳回;
produce拿到consumer處理的結果,繼續生產下一條訊息;
produce決定不生產了,通過c.close()關閉consumer,整個過程結束。
整個流程無鎖,由一個執行緒執行,produce和consumer協作完成任務,所以稱為“協程”,而非執行緒的搶佔式多工。
最後套用Donald Knuth的一句話總結協程的特點:
“子程式就是協程的一種特例。”
執行動態圖如下:
下節要點:
1.Python非同步與yield的總結
2.Tornado非同步非阻塞例項與yield的總結