
從零開始學貪心演算法
貪心演算法的定義:
貪心演算法是指在對問題求解時,總是做出在當前看來是最好的選擇。也就是說,不從整體最優上加以考慮,只做出在某種意義上的區域性最優解。貪心演算法不是對所有問題都能得到整體最優解,關鍵是貪心策略的選擇,選擇的貪心策略必須具備無後效性,即某個狀態以前的過程不會影響以後的狀態,只與當前狀態有關。
解題的一般步驟是:
1.建立數學模型來描述問題;
2.把求解的問題分成若干個子問題;
3.對每一子問題求解,得到子問題的區域性最優解;
4.把子問題的區域性最優解合成原來問題的一個解。
如果大家比較瞭解動態規劃,就會發現它們之間的相似之處。最優解問題大部分都可以拆分成一個個的子問題,把解空間的遍歷視作對子問題樹的遍歷,則以某種形式對樹整個的遍歷一遍就可以求出最優解,大部分情況下這是不可行的。貪心演算法和動態規劃本質上是對子問題樹的一種修剪,兩種演算法要求問題都具有的一個性質就是子問題最優性(組成最優解的每一個子問題的解,對於這個子問題本身肯定也是最優的)。動態規劃方法代表了這一類問題的一般解法,我們自底向上構造子問題的解,對每一個子樹的根,求出下面每一個葉子的值,並且以其中的最優值作為自身的值,其它的值捨棄。而貪心演算法是動態規劃方法的一個特例,可以證明每一個子樹的根的值不取決於下面葉子的值,而只取決於當前問題的狀況。換句話說,不需要知道一個節點所有子樹的情況,就可以求出這個節點的值。由於貪心演算法的這個特性,它對解空間樹的遍歷不需要自底向上,而只需要自根開始,選擇最優的路,一直走到底就可以了。
話不多說,我們來看幾個具體的例子慢慢理解它:
1.活動選擇問題
這是《演算法導論》上的例子,也是一個非常經典的問題。有n個需要在同一天使用同一個教室的活動a1,a2,…,an,教室同一時刻只能由一個活動使用。每個活動ai都有一個開始時間si和結束時間fi 。一旦被選擇後,活動ai就佔據半開時間區間[si,fi)。如果[si,fi]和[sj,fj]互不重疊,ai和aj兩個活動就可以被安排在這一天。該問題就是要安排這些活動使得儘量多的活動能不衝突的舉行。例如下圖所示的活動集合S,其中各項活動按照結束時間單調遞增排序。
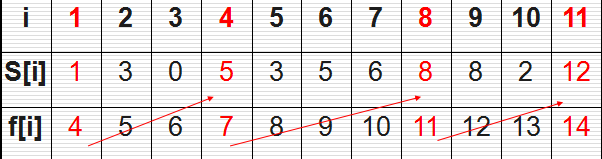
考慮使用貪心演算法的解法。為了方便,我們用不同顏色的線條代表每個活動,線條的長度就是活動所佔據的時間段,藍色的線條表示我們已經選擇的活動;紅色的線條表示我們沒有選擇的活動。
如果我們每次都選擇開始時間最早的活動,不能得到最優解:

如果我們每次都選擇持續時間最短的活動,不能得到最優解:

可以用數學歸納法證明,我們的貪心策略應該是每次選取結束時間最早的活動。直觀上也很好理解,按這種方法選擇相容活動為未安排活動留下儘可能多的時間。這也是把各項活動按照結束時間單調遞增排序的原因。
2.錢幣找零問題#include<cstdio> #include<iostream> #include<algorithm> using namespace std; int N; struct Act { int start; int end; }act[100010]; bool cmp(Act a,Act b) { return a.end<b.end; } int greedy_activity_selector() { int num=1,i=1; for(int j=2;j<=N;j++) { if(act[j].start>=act[i].end) { i=j; num++; } } return num; } int main() { int t; scanf("%d",&t); while(t--) { scanf("%d",&N); for(int i=1;i<=N;i++) { scanf("%lld %lld",&act[i].start,&act[i].end); } act[0].start=-1; act[0].end=-1; sort(act+1,act+N+1,cmp); int res=greedy_activity_selector(); cout<<res<<endl; } }
這個問題在我們的日常生活中就更加普遍了。假設1元、2元、5元、10元、20元、50元、100元的紙幣分別有c0, c1, c2, c3, c4, c5, c6張。現在要用這些錢來支付K元,至少要用多少張紙幣?用貪心演算法的思想,很顯然,每一步儘可能用面值大的紙幣即可。在日常生活中我們自然而然也是這麼做的。在程式中已經事先將Value按照從小到大的順序排好。
3.再論揹包問題#include<iostream> #include<algorithm> using namespace std; const int N=7; int Count[N]={3,0,2,1,0,3,5}; int Value[N]={1,2,5,10,20,50,100}; int solve(int money) { int num=0; for(int i=N-1;i>=0;i--) { int c=min(money/Value[i],Count[i]); money=money-c*Value[i]; num+=c; } if(money>0) num=-1; return num; } int main() { int money; cin>>money; int res=solve(money); if(res!=-1) cout<<res<<endl; else cout<<"NO"<<endl; }
在從零開始學動態規劃中我們已經談過三種最基本的揹包問題:零一揹包,部分揹包,完全揹包。很容易證明,揹包問題不能使用貪心演算法。然而我們考慮這樣一種揹包問題:在選擇物品i裝入揹包時,可以選擇物品的一部分,而不一定要全部裝入揹包。這時便可以使用貪心演算法求解了。計算每種物品的單位重量價值作為貪心選擇的依據指標,選擇單位重量價值最高的物品,將盡可能多的該物品裝入揹包,依此策略一直地進行下去,直到揹包裝滿為止。在零一揹包問題中貪心選擇之所以不能得到最優解原因是貪心選擇無法保證最終能將揹包裝滿,部分閒置的揹包空間使每公斤揹包空間的價值降低了。在程式中已經事先將單位重量價值按照從大到小的順序排好。
#include<iostream>
using namespace std;
const int N=4;
void knapsack(float M,float v[],float w[],float x[]);
int main()
{
float M=50;
//揹包所能容納的重量
float w[]={0,10,30,20,5};
//每種物品的重量
float v[]={0,200,400,100,10};
//每種物品的價值
float x[N+1]={0};
//記錄結果的陣列
knapsack(M,v,w,x);
cout<<"選擇裝下的物品比例:"<<endl;
for(int i=1;i<=N;i++) cout<<"["<<i<<"]:"<<x[i]<<endl;
}
void knapsack(float M,float v[],float w[],float x[])
{
int i;
//物品整件被裝下
for(i=1;i<=N;i++)
{
if(w[i]>M) break;
x[i]=1;
M-=w[i];
}
//物品部分被裝下
if(i<=N) x[i]=M/w[i];
} 4.多機排程問題
n個作業組成的作業集,可由m臺相同機器加工處理。要求給出一種作業排程方案,使所給的n個作業在儘可能短的時間內由m臺機器加工處理完成。作業不能拆分成更小的子作業;每個作業均可在任何一臺機器上加工處理。這個問題是NP完全問題,還沒有有效的解法(求最優解),但是可以用貪心選擇策略設計出較好的近似演算法(求次優解)。當n<=m時,只要將作業時間區間分配給作業即可;當n>m時,首先將n個作業從大到小排序,然後依此順序將作業分配給空閒的處理機。也就是說從剩下的作業中,選擇需要處理時間最長的,然後依次選擇處理時間次長的,直到所有的作業全部處理完畢,或者機器不能再處理其他作業為止。如果我們每次是將需要處理時間最短的作業分配給空閒的機器,那麼可能就會出現其它所有作業都處理完了只剩所需時間最長的作業在處理的情況,這樣勢必效率較低。在下面的程式碼中沒有討論n和m的大小關係,把這兩種情況合二為一了。
#include<iostream>
#include<algorithm>
using namespace std;
int speed[10010];
int mintime[110];
bool cmp( const int &x,const int &y)
{
return x>y;
}
int main()
{
int n,m;
memset(speed,0,sizeof(speed));
memset(mintime,0,sizeof(mintime));
cin>>n>>m;
for(int i=0;i<n;++i) cin>>speed[i];
sort(speed,speed+n,cmp);
for(int i=0;i<n;++i)
{
*min_element(mintime,mintime+m)+=speed[i];
}
cout<<*max_element(mintime,mintime+m)<<endl;
}5.小船過河問題
POJ1700是一道經典的貪心演算法例題。題目大意是隻有一艘船,能乘2人,船的執行速度為2人中較慢一人的速度,過去後還需一個人把船劃回來,問把n個人運到對岸,最少需要多久。先將所有人過河所需的時間按照升序排序,我們考慮把單獨過河所需要時間最多的兩個旅行者送到對岸去,有兩種方式:
1.最快的和次快的過河,然後最快的將船劃回來;次慢的和最慢的過河,然後次快的將船劃回來,所需時間為:t[0]+2*t[1]+t[n-1];
2.最快的和最慢的過河,然後最快的將船劃回來,最快的和次慢的過河,然後最快的將船劃回來,所需時間為:2*t[0]+t[n-2]+t[n-1]。
算一下就知道,除此之外的其它情況用的時間一定更多。每次都運送耗時最長的兩人而不影響其它人,問題具有貪心子結構的性質。
AC程式碼:
#include<iostream>
#include<algorithm>
using namespace std;
int main()
{
int a[1000],t,n,sum;
scanf("%d",&t);
while(t--)
{
scanf("%d",&n);
sum=0;
for(int i=0;i<n;i++) scanf("%d",&a[i]);
while(n>3)
{
sum=min(sum+a[1]+a[0]+a[n-1]+a[1],sum+a[n-1]+a[0]+a[n-2]+a[0]);
n-=2;
}
if(n==3) sum+=a[0]+a[1]+a[2];
else if(n==2) sum+=a[1];
else sum+=a[0];
printf("%d\n",sum);
}
}6.區間覆蓋問題
POJ1328是一道經典的貪心演算法例題。題目大意是假設海岸線是一條無限延伸的直線。陸地在海岸線的一側,而海洋在另一側。每一個小的島嶼是海洋上的一個點。雷達坐落於海岸線上,只能覆蓋d距離,所以如果小島能夠被覆蓋到的話,它們之間的距離最多為d。題目要求計算出能夠覆蓋給出的所有島嶼的最少雷達數目。對於每個小島,我們可以計算出一個雷達所在位置的區間。
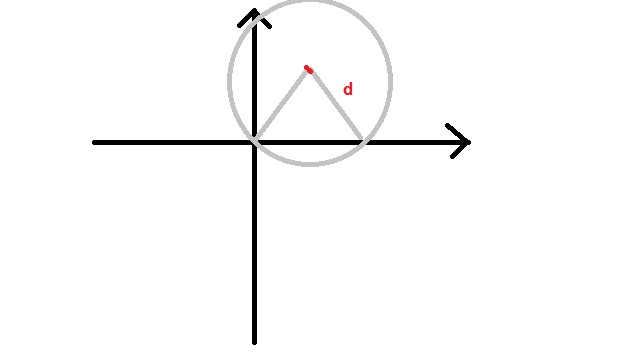
問題轉化為如何用盡可能少的點覆蓋這些區間。先將所有區間按照左端點大小排序,初始時需要一個點。如果兩個區間相交而不重合,我們什麼都不需要做;如果一個區間完全包含於另外一個區間,我們需要更新區間的右端點;如果兩個區間不相交,我們需要增加點並更新右端點。
AC程式碼:
#include<cmath>
#include<iostream>
#include<algorithm>
using namespace std;
struct Point
{
double x;
double y;
}point[1000];
int cmp(const void *a, const void *b)
{
return (*(Point *)a).x>(*(Point *)b).x?1:-1;
}
int main()
{
int n,d;
int num=1;
while(cin>>n>>d)
{
int counting=1;
if(n==0&&d==0) break;
for(int i=0;i<n;i++)
{
int x,y;
cin>>x>>y;
if(y>d)
{
counting=-1;
}
double t=sqrt(d*d-y*y);
//轉化為最少區間的問題
point[i].x=x-t;
//區間左端點
point[i].y=x+t;
//區間右端點
}
if(counting!=-1)
{
qsort(point,n,sizeof(point[0]),cmp);
//按區間左端點排序
double s=point[0].y;
//區間右端點
for(int i=1;i<n;i++)
{
if(point[i].x>s)
//如果兩個區間沒有重合,增加雷達數目並更新右端點
{
counting++;
s=point[i].y;
}
else if(point[i].y<s)
//如果第二個區間被完全包含於第一個區間,更新右端點
{
s=point[i].y;
}
}
}
cout<<"Case "<<num<<':'<<' '<<counting<<endl;
num++;
}
} 7.銷售比賽
在學校OJ上做的一道比較好的題,這裡碼一下。假設有偶數天,要求每天必須買一件物品或者賣一件物品,只能選擇一種操作並且不能不選,開始手上沒有這種物品。現在給你每天的物品價格表,要求計算最大收益。首先要明白,第一天必須買,最後一天必須賣,並且最後手上沒有物品。那麼除了第一天和最後一天之外我們每次取兩天,小的買大的賣,並且把賣的價格放進一個最小堆。如果買的價格比堆頂還大,就交換。這樣我們保證了賣的價格總是大於買的價格,一定能取得最大收益。
#include<queue>
#include<vector>
#include<cstdio>
#include<cstdlib>
#include<cstring>
#include<iostream>
#include<algorithm>
using namespace std;
long long int price[100010],t,n,res;
int main()
{
ios::sync_with_stdio(false);
cin>>t;
while(t--)
{
cin>>n;
priority_queue<long long int, vector<long long int>, greater<long long int> > q;
res=0;
for(int i=1;i<=n;i++)
{
cin>>price[i];
}
res-=price[1];
res+=price[n];
for(int i=2;i<=n-1;i=i+2)
{
long long int buy=min(price[i],price[i+1]);
long long int sell=max(price[i],price[i+1]);
if(!q.empty())
{
if(buy>q.top())
{
res=res-2*q.top()+buy+sell;
q.pop();
q.push(buy);
q.push(sell);
}
else
{
res=res-buy+sell;
q.push(sell);
}
}
else
{
res=res-buy+sell;
q.push(sell);
}
}
cout<<res<<endl;
}
}下面我們結合資料結構中的知識講解幾個例子。
8.Huffman編碼
這同樣是《演算法導論》上的例子。Huffman編碼是廣泛用於資料檔案壓縮的十分有效的編碼方法。我們可以有多種方式表示檔案中的資訊,如果用01串表示字元,採用定長編碼表示,則需要3位表示一個字元,整個檔案編碼需要300000位;採用變長編碼表示,給頻率高的字元較短的編碼,頻率低的字元較長的編碼,達到整體編碼減少的目的,則整個檔案編碼需要(45×1+13×3+12×3+16×3+9×4+5×4)×1000=224000位,由此可見,變長碼比定長碼方案好,總碼長減小約25%。

對每一個字元規定一個01串作為其程式碼,並要求任一字元的程式碼都不是其他字元程式碼的字首,這種編碼稱為字首碼。可能無字首碼是一個更好的名字,但是字首碼是一致認可的標準術語。編碼的字首性質可以使譯碼非常簡單:例如001011101可以唯一的分解為0,0,101,1101,因而其譯碼為aabe。譯碼過程需要方便的取出編碼的字首,為此可以用二叉樹作為字首碼的資料結構:樹葉表示給定字元;從樹根到樹葉的路徑當作該字元的字首碼;程式碼中每一位的0或1分別作為指示某節點到左兒子或右兒子的路標。

從上圖可以看出,最優字首編碼碼的二叉樹總是一棵完全二叉樹,而定長編碼的二叉樹不是一棵完全二叉樹。 給定編碼字符集C及頻率分佈f,C的一個字首碼編碼方案對應於一棵二叉樹T。字元c在樹T中的深度記為dT(c),dT(c)也是字元c的字首碼長。則平均碼長定義為:

使平均碼長達到最小的字首碼編碼方案稱為C的最優字首碼。
Huffman編碼的構造方法:先合併最小頻率的2個字元對應的子樹,計算合併後的子樹的頻率;重新排序各個子樹;對上述排序後的子樹序列進行合併;重複上述過程,將全部結點合併成1棵完整的二叉樹;對二叉樹中的邊賦予0、1,得到各字元的變長編碼。

POJ3253一道就是利用這一思想的典型例題。題目大意是有把一塊無限長的木板鋸成幾塊給定長度的小木板,每次鋸都需要一定費用,費用就是當前鋸的木板的長度。給定各個要求的小木板的長度以及小木板的個數,求最小的費用。以要求3塊長度分別為5,8,5的木板為例:先從無限長的木板上鋸下長度為21的木板,花費21;再從長度為21的木板上鋸下長度為5的木板,花費5;再從長度為16的木板上鋸下長度為8的木板,花費8;總花費=21+5+8=34。利用Huffman思想,要使總費用最小,那麼每次只選取最小長度的兩塊木板相加,再把這些和累加到總費用中即可。為了提高效率,使用優先佇列優化,並且還要注意使用long
long int儲存結果。
AC程式碼:
#include<queue>
#include<cstdio>
#include<iostream>
using namespace std;
int main()
{
long long int sum;
int i,n,t,a,b;
while(~scanf("%d",&n))
{
priority_queue<int,vector<int>,greater<int> >q;
for(i=0;i<n;i++)
{
scanf("%d",&t);
q.push(t);
}
sum=0;
if(q.size()==1)
{
a=q.top();
sum+=a;
q.pop();
}
while(q.size()>1)
{
a=q.top();
q.pop();
b=q.top();
q.pop();
t=a+b;
sum+=t;
q.push(t);
}
printf("%lld\n",sum);
}
}9.Dijkstra演算法
Dijkstra演算法是由E.W.Dijkstra於1959年提出,是目前公認的最好的求解最短路徑的方法,使用的條件是圖中不能存在負邊。演算法解決的是單個源點到其他頂點的最短路徑問題,其主要特點是每次迭代時選擇的下一個頂點是標記點之外距離源點最近的頂點,簡單的說就是bfs+貪心演算法的思想。
#include<iostream>
#include<algorithm>
#define INF 1000
#define MAX_V 100
using namespace std;
int main()
{
int V,E;
int i,j,m,n;
int cost[MAX_V][MAX_V];
int d[MAX_V];
bool used[MAX_V];
cin>>V>>E;
fill(d,d+V+1,INF);
fill(used,used+V,false);
for(i=0;i<V;i++)
{
for(j=0;j<V;j++)
{
if(i==j) cost[i][j]=0;
else cost[i][j]=INF;
}
}
for(m=0;m<E;m++)
{
cin>>i>>j>>cost[i][j];
cost[j][i]=cost[i][j];
}
cin>>n;
d[n]=0;
//源點
while(true)
{
int v=V;
for(m=0;m<V;m++)
{
if((!used[m])&&(d[m]<d[v])) v=m;
}
if(v==V) break;
used[v]=true;
for(m=0;m<V;m++)
{
d[m]=min(d[m],d[v]+cost[v][m]);
}
}
for(i=0;i<V;i++)
{
cout<<"the shortest distance between "<<n<<" and "<<i<<" is "<<d[i]<<endl;
}
}
設一個網路表示為無向連通帶權圖G =(V, E) , E中每條邊(v,w)的權為c[v][w]。如果G的子圖G’是一棵包含G的所有頂點的樹,則稱G’為G的生成樹。生成樹的代價是指生成樹上各邊權的總和,在G的所有生成樹中,耗費最小的生成樹稱為G的最小生成樹。例如在設計通訊網路時,用圖的頂點表示城市,用邊(v,w)的權c[v][w]表示建立城市v和城市w之間的通訊線路所需的費用,最小生成樹給出建立通訊網路的最經濟方案。
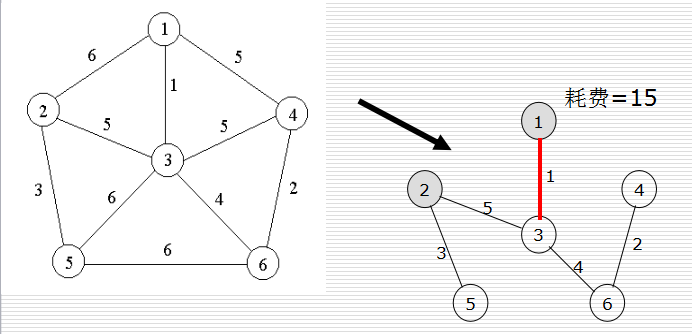
構造最小生成樹的Kruskal演算法和Prim演算法都利用了MST(最小生成樹)性質:設頂點集U是V的真子集(可以任意選取),如果(u,v)∈E為橫跨點集U和V—U的邊,即u∈U,v∈V- U,並且在所有這樣的邊中,(u,v)的權c[u][v]最小,則一定存在G的一棵最小生成樹,它以(u,v)為其中一條邊。
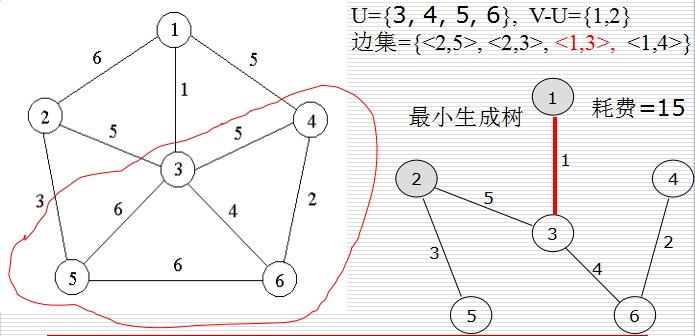
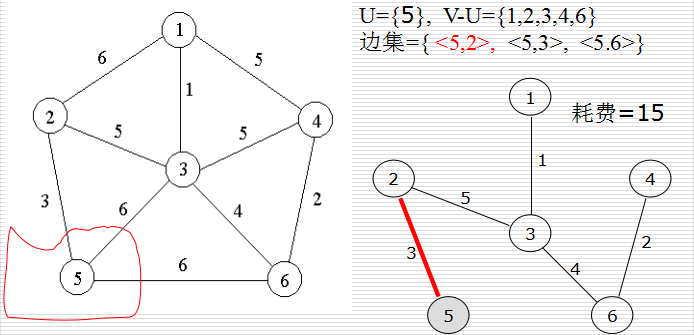
使用反證法可以很簡單的證明此性質。假設對G的任意一個最小生成樹T,針對點集U和V—U,(u,v)∈E為橫跨這2個點集的最小權邊,T不包含該最小權邊<u, v>,但T包括節點u和v。將<u,v>新增到樹T中,樹T將變為含迴路的子圖,並且該回路上有一條不同於<u,v>的邊<u’,v’>,u’∈U,v’∈V-U。將<u’,v’>刪去,得到另一個樹T’,即樹T’是通過將T中的邊<u’,v’>替換為<u,v>得到的。由於這2條邊的耗費滿足c[u][v]≤c[u’][v’],故即T’耗費≤T的耗費,這與T是任意最小生成樹的假設相矛盾,從而得證。
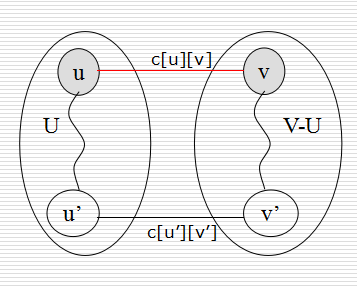
Prim演算法每一步都選擇連線U和V-U的權值最小的邊加入生成樹。
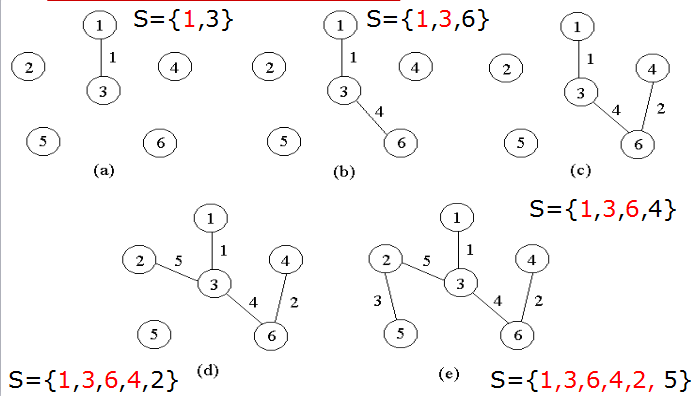
#include<iostream>
#include<algorithm>
#define MAX_V 100
#define INF 1000
using namespace std;
int main()
{
int V,E;
int i,j,m,n;
int cost[MAX_V][MAX_V];
int mincost[MAX_V];
bool used[MAX_V];
cin>>V>>E;
fill(mincost,mincost+V+1,INF);
fill(used,used+V,false);
for(i=0;i<V;i++)
{
for(j=0;j<V;j++)
{
if(i==j) cost[i][j]=0;
else cost[i][j]=INF;
}
}
for(m=0;m<E;m++)
{
cin>>i>>j>>cost[i][j];
cost[j][i]=cost[i][j];
}
mincost[0]=0;
int res=0;
while(true)
{
int v=V;
for(m=0;m<V;m++)
{
if((!used[m])&&(mincost[m]<mincost[v]))
v=m;
}
if(v==V) break;
used[v]=true;
res+=mincost[v];
for(m=0;m<V;m++)
{
mincost[m]=min(mincost[m],cost[v][m]);
}
}
cout<<res<<endl;
}
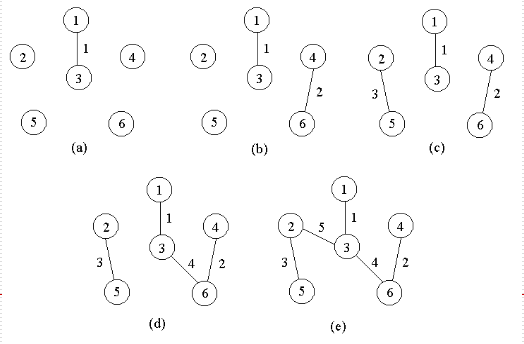
#include<iostream>
#include<algorithm>
#define MAX_E 100
using namespace std;
struct edge
{
int u,v,cost;
};
int pre[MAX_E];
edge es[MAX_E];
int find(int x);
void initvalue(int x);
bool same(int x,int y);
void unite(int x,int y);
bool comp(const edge& e1,const edge& e2);
int main()
{
int V,E;
int i,j,m,n;
cin>>V>>E;
initvalue(V);
for(i=0;i<E;i++) cin>>es[i].u>>es[i].v>>es[i].cost;
sort(es,es+E,comp);
int res=0;
for(i=0;i<E;i++)
{
edge e=es[i];
if(!same(e.u,e.v))
{
unite(e.u,e.v);
res+=e.cost;
}
}
cout<<res<<endl;
}
bool comp(const edge& e1,const edge& e2)
{
return e1.cost<e2.cost;
}
void initvalue(int x)
{
for(int i=0;i<x;i++) pre[i]=i;
}
int find(int x)
{
int r=x;
while(pre[r]!=r) r=pre[r];
int i=x,j;
while(pre[i]!=r)
{
j=pre[i];
pre[i]=r;
i=j;
}
return r;
}
bool same(int x,int y)
{
if(find(x)==find(y)) return true;
else return false;
}
void unite(int x,int y)
{
int fx=find(x);
int fy=find(y);
if(fx!=fy) pre[fx]=fy;
}