
資料預處理之資料標準化
阿新 • • 發佈:2019-01-04
資料標準化的意義
在對資料集建模前,常常要對資料的某一特徵或幾個特徵進行規範化處理,其目的在於將特徵值歸一到同一個維度,消除比重不平衡的問題。
常用的標準化方法有 最大-最小標準化、零-均值標準化 和 小數定標標準化。
最大-最小標準化
最大-最小標準化又稱為離差標準化,將原始資料進行線性變換,對映到[0,1]區間。
轉換公式如下:
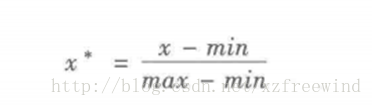
其中,max為特徵中最大的值,min為特徵中最小的值。max-min表示極差。
這種標準化的優點是實現簡單、保留了原始資料之間的關係。
缺點也很明顯,即:
1.當樣本中的max過大時,會使得標準化後各值之間相差不大,無法準確表示樣本間的差異;
2.當新加入的樣本的值大於max或小於min,會使標準化產生混亂,即每當有新樣本匯入時,必須重新計算max和min。
零-均值標準化
零-均值標準化也稱標準差標準化,經過該標準化處理後的資料的均值為0,標準差為1。轉化公式如下:
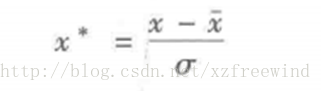
其中,x ̅表示樣本的均值,σ表示樣本的標準差,是目前使用最多的標準化方法。
優點:
1.將屬性值轉換為標準的正態分佈模型,便於某些演算法的實施
2.轉換後的屬性值離中心點的距離表示了它的概率值。
小數定標標準化
小數定標標準化即是通過移動屬性值的小數位數來將屬性值圈定在[0,1]之間,移動小數的位數決定於屬性值絕對值的最大值,轉化公式為:
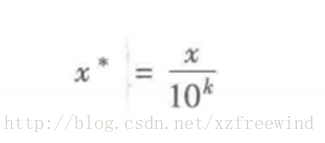
其中,k為屬性值絕對值的最大值的位數。
參考
《python資料分析與挖掘實戰》