
協同過濾推薦之slope one演算法
1.示例引入
比如說你在京東選購手機iphone和note7:
消費者用過後,會有相關的評分。
假設評分如下:
評分 iphone note7
小a 4 5
小b 4 3
小c 2 3
小d 3 ?
問題:請猜測一下小d可能會給“note7”打多少分?
思路:把兩個手機的平均差值求出來,iphone減去note7的平均偏差:[(4-5)+(4-3)+(2-3)]/3=-0.333。一個新客戶比如小d,只吃了iphone評分為3分,那麼可以猜測她對note7的評分為:3-(-0.333)=3.333
這就是slope one 演算法的基本思路,非常非常的簡單。
2.slope one 演算法思想
Slope One 演算法是由 Daniel Lemire 教授在 2005 年提出的一個Item-Based 的協同過濾推薦演算法。和其它類似演算法相比, 它的最大優點在於演算法很簡單, 易於實現, 執行效率高, 同時推薦的準確性相對較高。
Slope One演算法是基於不同物品之間的評分差的線性演算法,預測使用者對物品評分的個性化演算法。主要兩步:
Step1:計算物品之間的評分差的均值,記為物品間的評分偏差(兩物品同時被評分);

Step2:根據物品間的評分偏差和使用者的歷史評分,預測使用者對未評分的物品的評分。
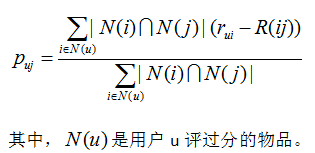
Step3:將預測評分排序,取topN對應的物品推薦給使用者。
舉例:
假設有100個人對物品A和物品B打分了,R(AB)表示這100個人對A和B打分的平均偏差;有1000個人對物品B和物品C打分了, R(CB)表示這1000個人對C和B打分的平均偏差;

3.1資料
def loadData(): items={'A':{1:5,2:3}, 'B':{1:3,2:4,3:2}, 'C':{1:2,3:5}} users={1:{'A':5,'B':3,'C':2}, 2:{'A':3,'B':4}, 3:{'B':2,'C':5}} return items,users
3.2物品間評分偏差
#***計算物品之間的評分差
#items:從物品角度,考慮評分
#users:從使用者角度,考慮評分
def buildAverageDiffs(items,users,averages):
#遍歷每條物品-使用者評分資料
for itemId in items:
for otherItemId in items:
average=0.0 #物品間的評分偏差均值
userRatingPairCount=0 #兩件物品均評過分的使用者數
if itemId!=otherItemId: #若無不同的物品項
for userId in users: #遍歷使用者-物品評分數
userRatings=users[userId] #每條資料為使用者對物品的評分
#當前物品項在使用者的評分資料中,且使用者也對其他物品由評分
if itemId in userRatings and otherItemId in userRatings:
#兩件物品均評過分的使用者數加1
userRatingPairCount+=1
#評分偏差為每項當前物品評分-其他物品評分求和
average+=(userRatings[otherItemId]-userRatings[itemId])
averages[(itemId,otherItemId)]=average/userRatingPairCount3.3預估評分
#***預測評分
#users:使用者對物品的評分資料
#items:物品由哪些使用者評分的資料
#averages:計算的評分偏差
#targetUserId:被推薦的使用者
#targetItemId:被推薦的物品
def suggestedRating(users,items,averages,targetUserId,targetItemId):
runningRatingCount=0 #預測評分的分母
weightedRatingTotal=0.0 #分子
for i in users[targetUserId]:
#物品i和物品targetItemId共同評分的使用者數
ratingCount=userWhoRatedBoth(users,i,targetItemId)
#分子
weightedRatingTotal+=(users[targetUserId][i]-averages[(targetItemId,i)])\
*ratingCount
#分母
runningRatingCount+=ratingCount
#返回預測評分
return weightedRatingTotal/runningRatingCount統計兩物品共同評分的使用者數
# 物品itemId1與itemId2共同有多少使用者評分
def userWhoRatedBoth(users,itemId1,itemId2):
count=0
#使用者-物品評分資料
for userId in users:
#使用者對物品itemId1與itemId2都評過分則計數加1
if itemId1 in users[userId] and itemId2 in users[userId]:
count+=1
return count3.4測試結果:
if __name__=='__main__':
items,users=loadData()
averages={}
#計算物品之間的評分差
buildAverageDiffs(items,users,averages)
#預測評分:使用者2對物品C的評分
predictRating=suggestedRating(users,items,averages,2,'C')
print 'Guess the user will rate the score :',predictRating
結果:使用者2對物品C的預測分值為
Guess the user will rate the score : 3.33333333333
4.slopeOne使用場景
該演算法適用於物品更新不頻繁,數量相對較穩定並且物品數目明顯小於使用者數的場景。依賴使用者的使用者行為日誌和物品偏好的相關內容。
優點:
1.演算法簡單,易於實現,執行效率高;
2.可以發現使用者潛在的興趣愛好;
缺點:
依賴使用者行為,存在冷啟動問題和稀疏性問題。