
梯度消失、梯度爆炸及其解決方法
前言
本文主要深入介紹深度學習中的梯度消失和梯度爆炸的問題以及解決方案。本文分為三部分,第一部分主要直觀的介紹深度學習中為什麼使用梯度更新,第二部分主要介紹深度學習中梯度消失及爆炸的原因,第三部分對提出梯度消失及爆炸的解決方案。有基礎的同鞋可以跳著閱讀。
其中,梯度消失爆炸的解決方案主要包括以下幾個部分。
- 預訓練加微調
- 梯度剪下、權重正則(針對梯度爆炸)
- 使用不同的啟用函式
- 使用batchnorm
- 使用殘差結構
- 使用LSTM網路第一部分:為什麼要使用梯度更新規則

第二部分:梯度消失、爆炸
梯度消失與梯度爆炸其實是一種情況,看接下來的文章就知道了。兩種情況下梯度消失經常出現,一是在深層網路
1.深層網路角度
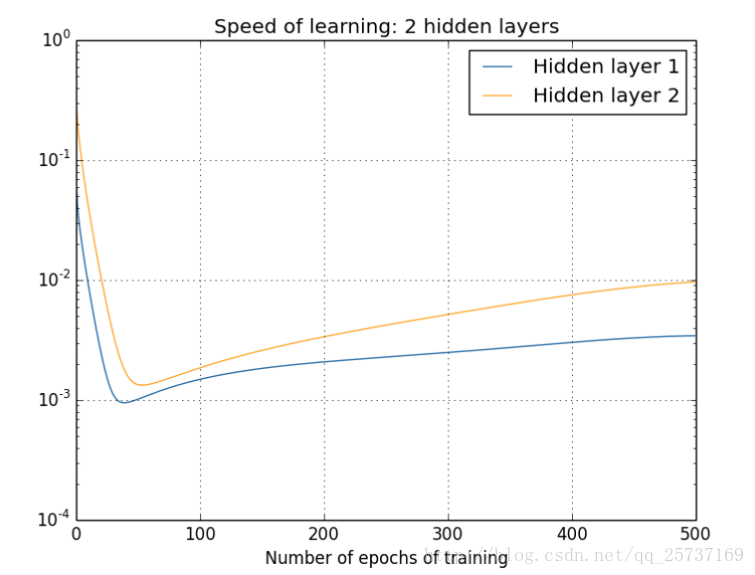
比較簡單的深層網路如下: 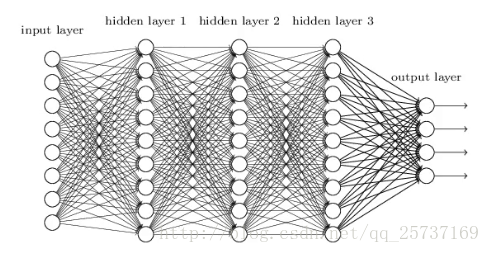

那麼對於四個隱層的網路來說,就更明顯了,第四隱藏層比第一隱藏層的更新速度慢了兩個數量級: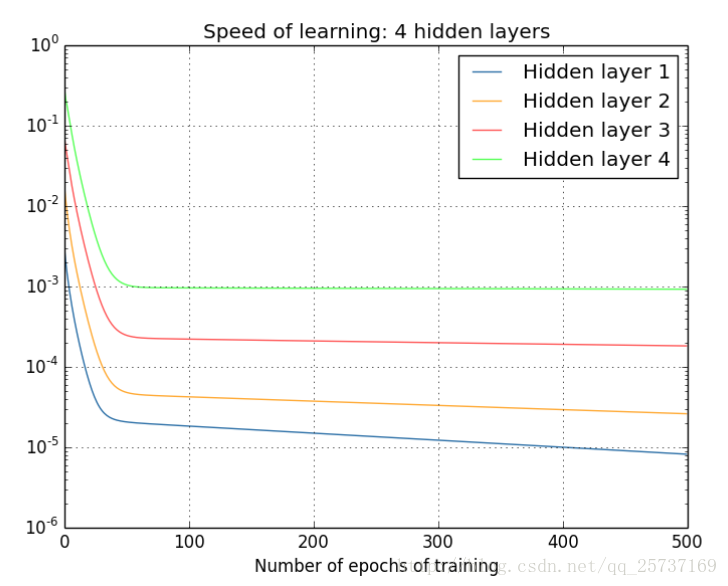
總結:從深層網路角度來講,不同的層學習的速度差異很大,表現為網路中靠近輸出的層學習的情況很好,靠近輸入的層學習的很慢,有時甚至訓練了很久,前幾層的權值和剛開始隨機初始化的值差不多。因此,梯度消失、爆炸,其根本原因在於反向傳播訓練法則,屬於先天不足,另外多說一句,Hinton提出capsule的原因就是為了徹底拋棄反向傳播,如果真能大範圍普及,那真是一個革命。
2.啟用函式角度
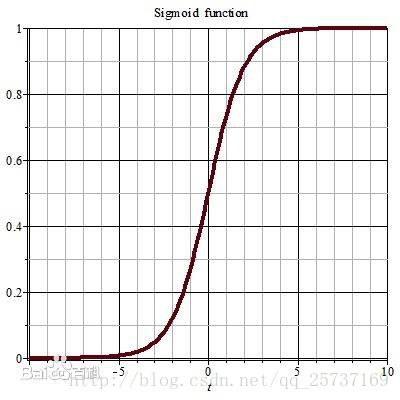

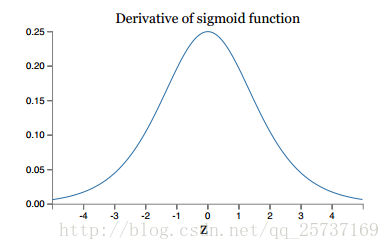
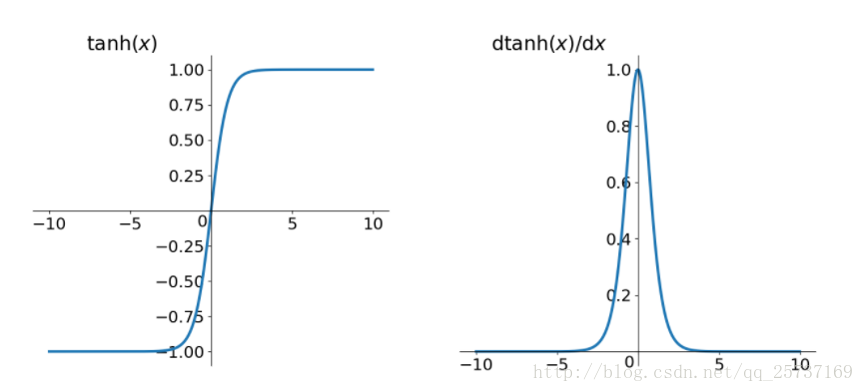
同理,tanh作為損失函式,它的導數圖如下,可以看出,tanh比sigmoid要好一些,但是它的倒數仍然是小於1的。tanh數學表達為:

第三部分:梯度消失、爆炸的解決方案
2.1 方案1-預訓練加微調
此方法來自Hinton在2006年發表的一篇論文,Hinton為了解決梯度的問題,提出採取無監督逐層訓練方法,其基本思想是每次訓練一層隱節點,訓練時將上一層隱節點的輸出作為輸入,而本層隱節點的輸出作為下一層隱節點的輸入,此過程就是逐層“預訓練”(pre-training);在預訓練完成後,再對整個網路進行“微調”(fine-tunning)。Hinton在訓練深度信念網路(Deep Belief Networks中,使用了這個方法,在各層預訓練完成後,再利用BP演算法對整個網路進行訓練。此思想相當於是先尋找區域性最優,然後整合起來尋找全域性最優,此方法有一定的好處,但是目前應用的不是很多了。
2.2 方案2-梯度剪下、正則
梯度剪下這個方案主要是針對梯度爆炸提出的,其思想是設定一個梯度剪下閾值,然後更新梯度的時候,如果梯度超過這個閾值,那麼就將其強制限制在這個範圍之內。這可以防止梯度爆炸。
注:在WGAN中也有梯度剪下限制操作,但是和這個是不一樣的,WGAN限制梯度更新資訊是為了保證lipchitz條件。另外一種解決梯度爆炸的手段是採用權重正則化(weithts regularization)比較常見的是l1l1正則,和l2l2正則,在各個深度框架中都有相應的API可以使用正則化,比如在tensorflowtensorflow中,若搭建網路的時候已經設定了正則化引數,則呼叫以下程式碼可以直接計算出正則損失:
regularization_loss = tf.add_n(tf.losses.get_regularization_losses(scope='my_resnet_50'))如果沒有設定初始化引數,也可以使用以下程式碼計算l2l2正則損失:
l2_loss = tf.add_n([tf.nn.l2_loss(var) forvarin tf.trainable_variables() if'weights'invar.name])
正則化是通過對網路權重做正則限制過擬合,仔細看正則項在損失函式的形式:
其中,αα是指正則項係數,因此,如果發生梯度爆炸,權值的範數就會變的非常大,通過正則化項,可以部分限制梯度爆炸的發生。

注:事實上,在深度神經網路中,往往是梯度消失出現的更多一些。2.3 方案3-relu、leakrelu、elu等啟用函式
Relu:思想也很簡單,如果啟用函式的導數為1,那麼就不存在梯度消失爆炸的問題了,每層的網路都可以得到相同的更新速度,relu就這樣應運而生。先看一下relu的數學表示式:
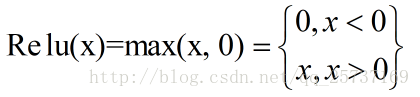
其函式影象:
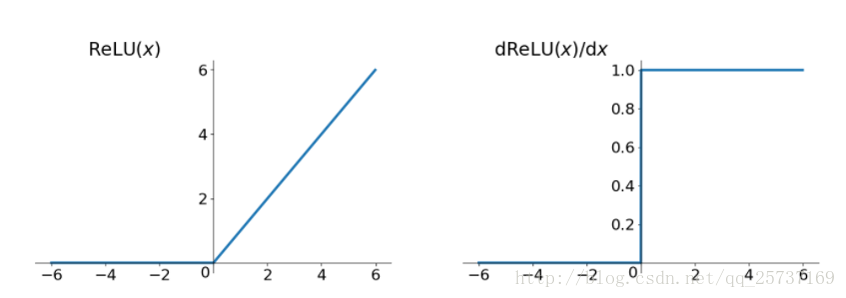
從上圖中,我們可以很容易看出,relu函式的導數在正數部分是恆等於1的,因此在深層網路中使用relu啟用函式就不會導致梯度消失和爆炸的問題。
relu的主要貢獻在於:
-- 解決了梯度消失、爆炸的問題
-- 計算方便,計算速度快
-- 加速了網路的訓練同時也存在一些缺點:
-- 由於負數部分恆為0,會導致一些神經元無法啟用(可通過設定小學習率部分解決)
-- 輸出不是以0為中心的儘管relu也有缺點,但是仍然是目前使用最多的啟用函式
leakrelu
leakrelu就是為了解決relu的0區間帶來的影響,其數學表達為:leakrelu=max(k∗x,0)其中k是leak係數,一般選擇0.01或者0.02,或者通過學習而來
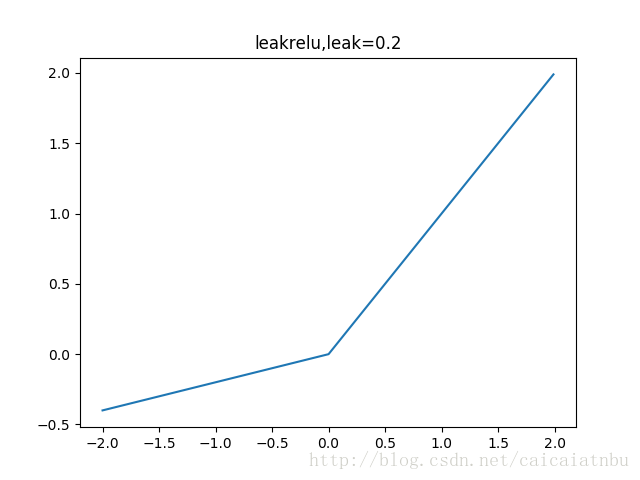
leakrelu解決了0區間帶來的影響,而且包含了relu的所有優點
elu
elu啟用函式也是為了解決relu的0區間帶來的影響,其數學表達為: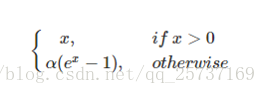
其函式及其導數數學形式為:
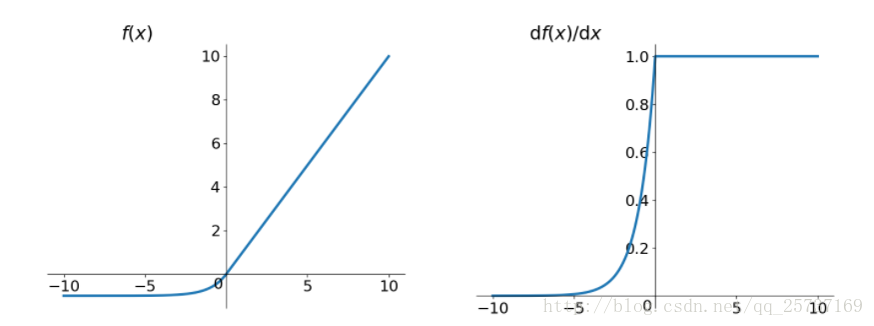
但是elu相對於leakrelu來說,計算要更耗時間一些
2.4 解決方案4-batchnorm
2.5 解決方案5-殘差結構
殘差結構說起殘差的話,不得不提這篇論文了:Deep Residual Learning for Image Recognition,關於這篇論文的解讀,可以參考知乎連結:https://zhuanlan.zhihu.com/p/31852747這裡只簡單介紹殘差如何解決梯度的問題。
事實上,就是殘差網路的出現導致了image net比賽的終結,自從殘差提出後,幾乎所有的深度網路都離不開殘差的身影,相比較之前的幾層,幾十層的深度網路,在殘差網路面前都不值一提,殘差可以很輕鬆的構建幾百層,一千多層的網路而不用擔心梯度消失過快的問題,原因就在於殘差的捷徑(shortcut)部分,其中殘差單元如下圖所示: 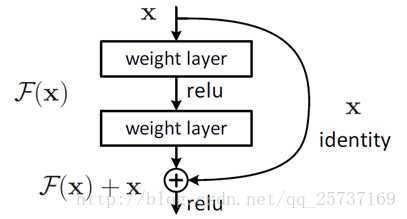

2.6 解決方案6-LSTM
LSTM全稱是長短期記憶網路(long-short term memory networks),是不那麼容易發生梯度消失的,主要原因在於LSTM內部複雜的“門”(gates),如下圖,LSTM通過它內部的“門”可以接下來更新的時候“記住”前幾次訓練的”殘留記憶“,因此,經常用於生成文字中。目前也有基於CNN的LSTM,感興趣的可以嘗試一下。

參考資料:
原文地址: https://blog.csdn.net/qq_25737169/article/details/78847691