
神經網路中Epoch、Iteration、Batchsize相關理解和說明
阿新 • • 發佈:2019-01-04
看了半年論文,對這三個概念總是模稜兩可,不是很清楚。所以呢!我就花了半天時間,收集網上寫的很好的關於這三個概念的介紹,把他們總結到一起,希望能對大家有幫助!
batchsize:中文翻譯為批大小(批尺寸)。
簡單點說,批量大小將決定我們一次訓練的樣本數目。
batch_size將影響到模型的優化程度和速度。
為什麼需要有Batch_Size:
batchsize的正確選擇是為了在記憶體效率和記憶體容量之間尋找最佳平衡。
Batch_Size的取值:
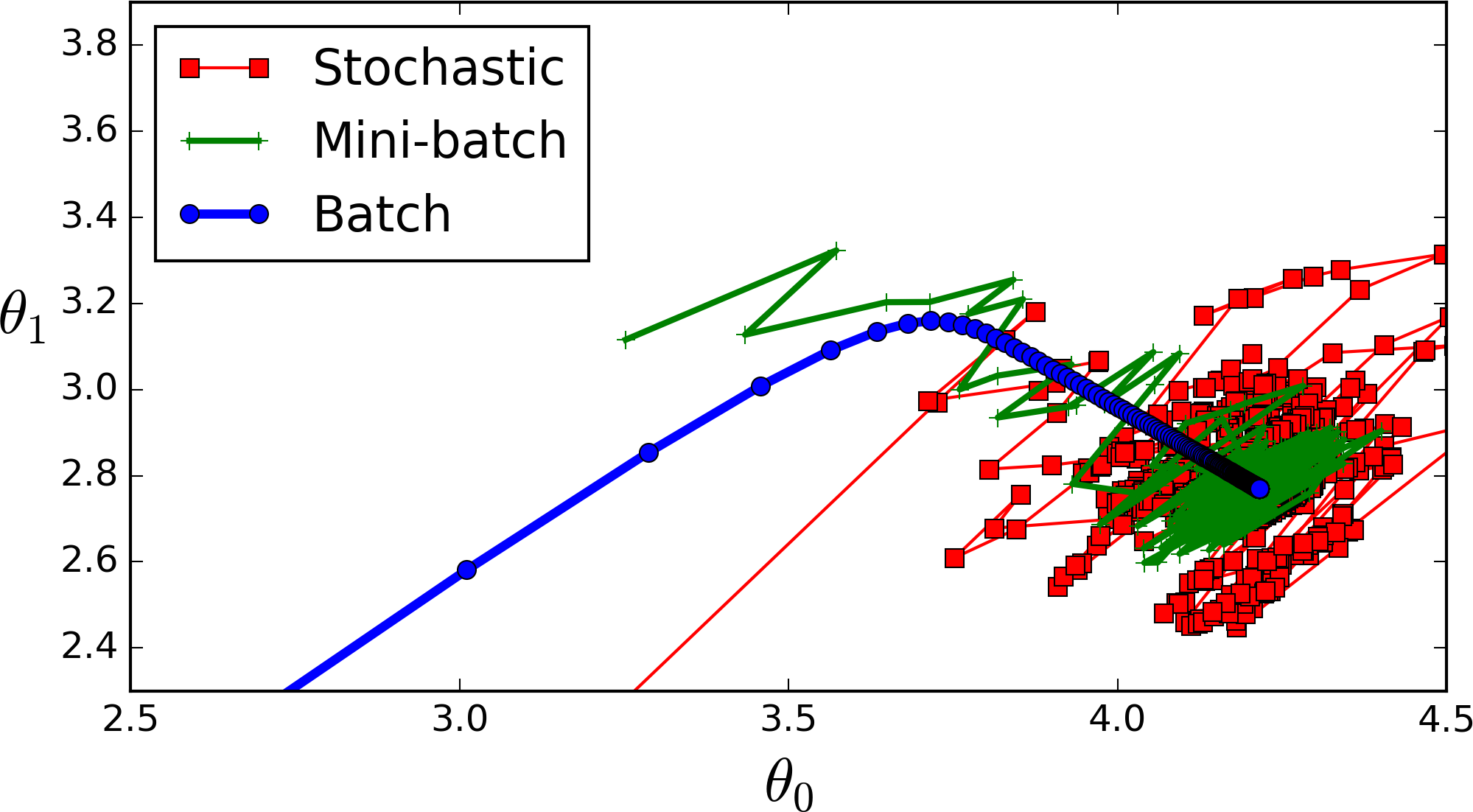
全批次(藍色)
如果資料集比較小,我們就採用全資料集。全資料集確定的方向能夠更好的代表樣本總體,從而更準確的朝向極值所在的方向。
注:對於大的資料集,我們不能使用全批次,因為會得到更差的結果。
迷你批次(綠色)
選擇一個適中的Batch_Size值。就是說我們選定一個batch的大小後,將會以batch的大小將資料輸入深度學習的網路中,然後計算這個batch的所有樣本的平均損失,即代價函式是所有樣本的平均。
隨機(Batch_Size等於1的情況)(紅色)
每次修正方向以各自樣本的梯度方向修正,橫衝直撞各自為政,難以達到收斂。
適當的增加Batch_Size的優點:
1.通過並行化提高記憶體利用率。2.單次epoch的迭代次數減少,提高執行速度。(單次epoch=(全部訓練樣本/batchsize)/iteration=1)3.適當的增加Batch_Size,梯度下降方向準確度增加,訓練震動的幅度減小。(看上圖便可知曉)經驗總結:
相對於正常資料集,如果Batch_Size過小,訓練資料就會非常難收斂,從而導致underfitting。增大Batch_Size,相對處理速度加快。增大Batch_Size,所需記憶體容量增加(epoch的次數需要增加以達到最好的結果)這裡我們發現上面兩個矛盾的問題,因為當epoch增加以後同樣也會導致耗時增加從而速度下降。因此我們需要尋找最好的Batch_Size。再次重申:Batch_Size的正確選擇是為了在記憶體效率和記憶體容量之間尋找最佳平衡。iteration:中文翻譯為迭代。迭代是重複反饋的動作,神經網路中我們希望通過迭代進行多次的訓練以達到所需的目標或結果。每一次迭代得到的結果都會被作為下一次迭代的初始值。(2)iteration:1個iteration等於使用batchsize個樣本訓練一次;
(3)epoch:1個epoch等於使用訓練集中的全部樣本訓練一次;
舉個例子,訓練集有1000個樣本,batchsize=10,那麼:
訓練完整個樣本集需要:
100次iteration,1次epoch。
參考連結:http://blog.csdn.net/anshiquanshu/article/details/72630012
------------------------------------------------------華麗的分割線----------------------------------------------------
神經網路訓練中,Epoch、Batch Size、和迭代傻傻的分不清?
為了理解這些術語有什麼不同,我們需要了解一些關於機器學習的術語,比如梯度下降,幫助我們理解。這裡簡單的總結梯度下降的含義:梯度下降是一個在機器學習中用於尋找較佳結果(曲線的最小值)的迭代優化演算法。梯度的含義是斜率或者斜坡的傾斜度。下降的含義是代價函式的下降。演算法是迭代的,意思是需要多次使用演算法獲取結果,以得到最優化結果。梯度下降的迭代性質能使欠擬合演變成獲得對資料的較佳擬合。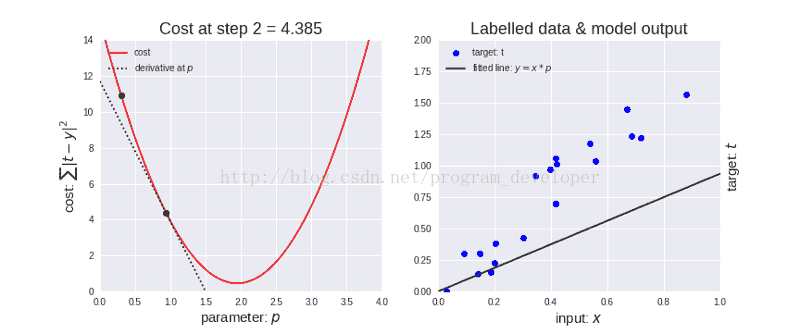
梯度下降中有一個稱為學習率的參量。如上圖左所示,剛開始學習率較大,因此下降步長更大。隨著點的下降,學習率變得越來越小,從而下降步長也變小。同時,代價函式也在減小,或者說代價在減小,有時候也稱為損失函式或者損失,兩者是一樣的。(損失/代價的減小是一個概念)。只有在資料很龐大的時候(在機器學習中,資料一般情況下都會很大),我們才需要使用epochs,batch size,iteration這些術語,在這種情況下,一次性將資料輸入計算機是不可能的。因此,為了解決這個問題,我們需要把資料分成小塊,一塊一塊的傳遞給計算機,在每一步的末端更新神經網路的權重,擬合給定的資料。
epoch
當一個完整的資料集通過了神經網路一次並且返回了一次,這個過程稱為一次epoch。然而,當一個epoch對於計算機而言太龐大的時候,就需要把它分成多個小塊。
為什麼要使用多於一個epoch?
在神經網路中傳遞完整的資料集一次是不夠的,而且我們需要將完整的資料集在同樣的神經網路中傳遞多次。但請記住,我們使用的是有限的資料集,並且我們使用一個迭代過程即梯度下降來優化學習過程。如下圖所示。因此僅僅更新一次或者說使用一個epoch是不夠的。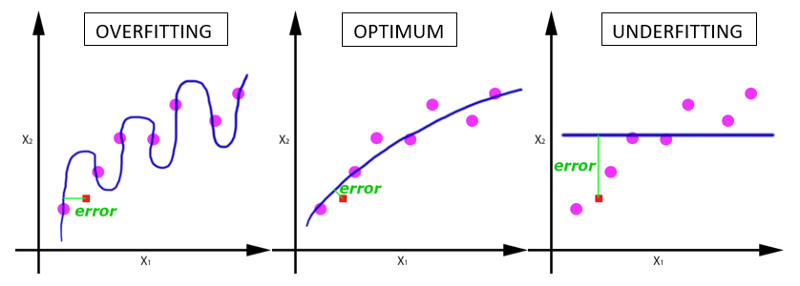 隨著epoch數量增加,神經網路中的權重的更新次數也在增加,曲線從欠擬合變得過擬合。
隨著epoch數量增加,神經網路中的權重的更新次數也在增加,曲線從欠擬合變得過擬合。那麼,問題來了,幾個epoch才是合適的呢?
不幸的是,這個問題並沒有正確的答案。對於不同的資料集,答案是不一樣的。但是資料的多樣性會影響合適的epoch的數量。比如,只有黑色的貓的資料集,以及有各種顏色的貓的資料集。Batch Size
batch size將決定我們一次訓練的樣本數目。注意:batch size 和 number of batches是不同的。Batch是什麼?
在不能將資料一次性通過神經網路的時候,就需要將資料集分成幾個batch。Iteration
Iteration是batch需要完成一個epoch的次數。舉個例子:
有一個2000個訓練樣本的資料集。將2000個樣本分成大小為500的batch,那麼完成一個epoch需要4個iteration。參考地址:http://www.dataguru.cn/article-12193-1.htmlhttps://towardsdatascience.com/epoch-vs-iterations-vs-batch-size-4dfb9c7ce9c9