
神經網路中Epoch、Iteration、Batchsize相關理解
batch
深度學習的優化演算法,說白了就是梯度下降。每次的引數更新有兩種方式。
第一種,遍歷全部資料集算一次損失函式,然後算函式對各個引數的梯度,更新梯度。這種方法每更新一次引數都要把資料集裡的所有樣本都看一遍,計算量開銷大,計算速度慢,不支援線上學習,這稱為Batch gradient descent,批梯度下降。
另一種,每看一個數據就算一下損失函式,然後求梯度更新引數,這個稱為隨機梯度下降,stochastic gradient descent。這個方法速度比較快,但是收斂效能不太好,可能在最優點附近晃來晃去,hit不到最優點。兩次引數的更新也有可能互相抵消掉,造成目標函式震盪的比較劇烈。
為了克服兩種方法的缺點,現在一般採用的是一種折中手段,mini-batch gradient decent,小批的梯度下降,這種方法把資料分為若干個批,按批來更新引數,這樣,一個批中的一組資料共同決定了本次梯度的方向,下降起來就不容易跑偏,減少了隨機性。另一方面因為批的樣本數與整個資料集相比小了很多,計算量也不是很大。
基本上現在的梯度下降都是基於mini-batch的,所以深度學習框架的函式中經常會出現batch_size,就是指這個。
關於如何將訓練樣本轉換從batch_size的格式可以參考訓練樣本的batch_size資料的準備。
iterations
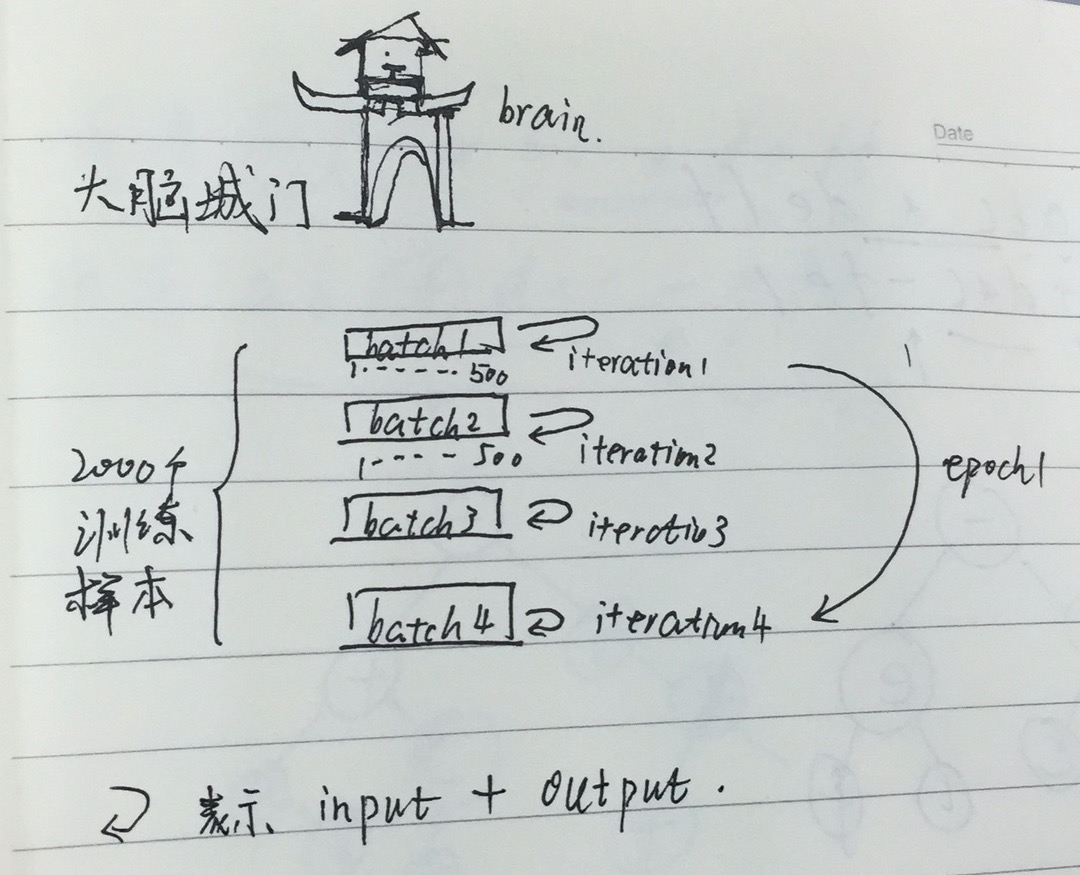
iterations(迭代):每一次迭代都是一次權重更新,每一次權重更新需要batch_size個數據進行Forward運算得到損失函式,再BP演算法更新引數。1個iteration等於使用batchsize個樣本訓練一次。
epochs
epochs被定義為向前和向後傳播中所有批次的單次訓練迭代。這意味著1個週期是整個輸入資料的單次向前和向後傳遞。簡單說,epochs指的就是訓練過程中資料將被“輪”多少次,就這樣。
舉個例子
batchsize:中文翻譯為批大小(批尺寸)。
簡單點說,批量大小將決定我們一次訓練的樣本數目。
batch_size將影響到模型的優化程度和速度。
為什麼需要有Batch_Size:
batchsize的正確選擇是為了在記憶體效率和記憶體容量之間尋找最佳平衡。
Batch_Size的取值:
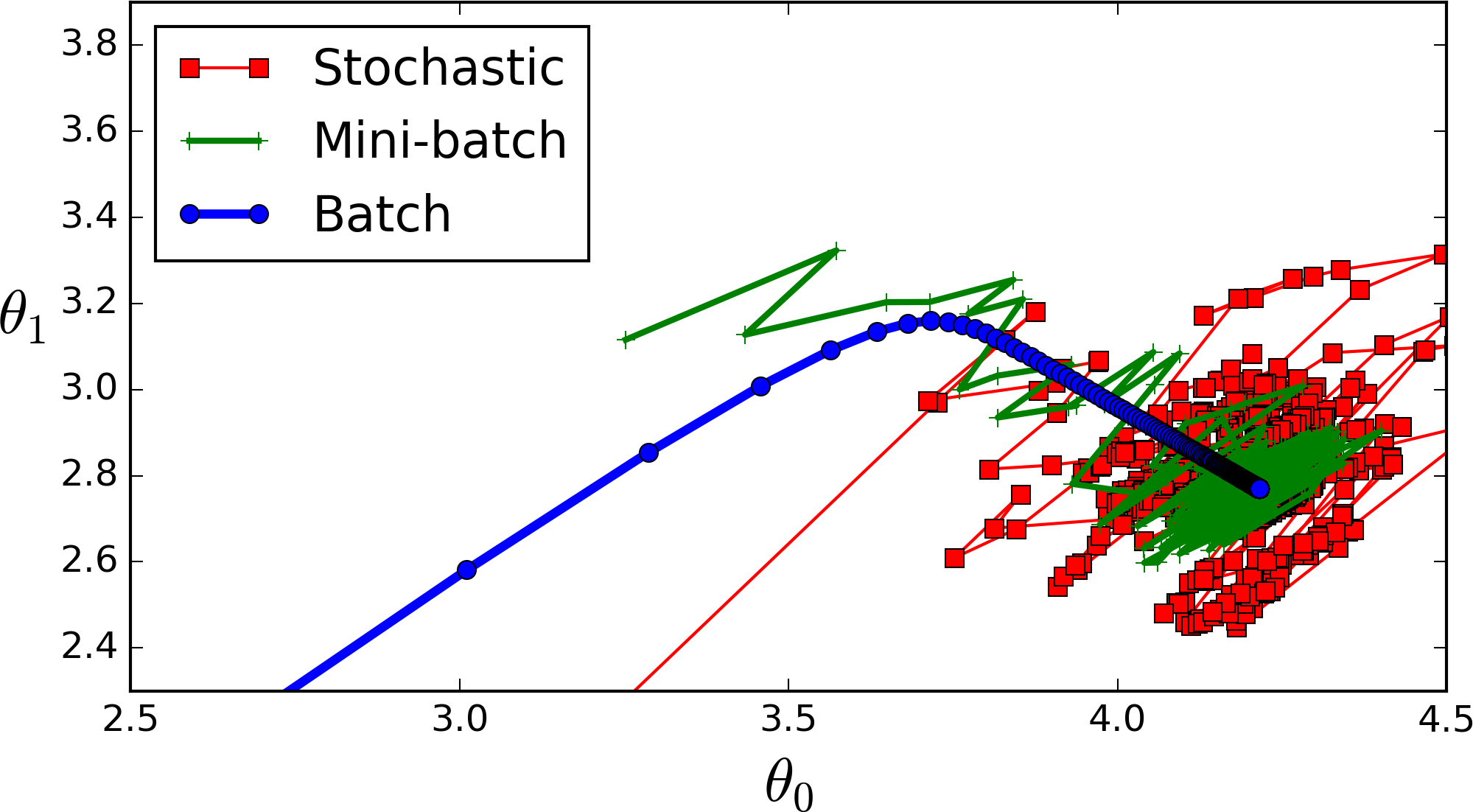
全批次(藍色)
如果資料集比較小,我們就採用全資料集。全資料集確定的方向能夠更好的代表樣本總體,從而更準確的朝向極值所在的方向。
注:對於大的資料集,我們不能使用全批次,因為會得到更差的結果。
迷你批次(綠色)
選擇一個適中的Batch_Size值。就是說我們選定一個batch的大小後,將會以batch的大小將資料輸入深度學習的網路中,然後計算這個batch的所有樣本的平均損失,即代價函式是所有樣本的平均。
隨機(Batch_Size等於1的情況)(紅色)
每次修正方向以各自樣本的梯度方向修正,橫衝直撞各自為政,難以達到收斂。
適當的增加Batch_Size的優點:
1.通過並行化提高記憶體利用率。
2.單次epoch的迭代次數減少,提高執行速度。(單次epoch=(全部訓練樣本/batchsize)/iteration=1)
3.適當的增加Batch_Size,梯度下降方向準確度增加,訓練震動的幅度減小。(看上圖便可知曉)
經驗總結:
相對於正常資料集,如果Batch_Size過小,訓練資料就會非常難收斂,從而導致underfitting。
增大Batch_Size,相對處理速度加快。
增大Batch_Size,所需記憶體容量增加(epoch的次數需要增加以達到最好的結果)
這裡我們發現上面兩個矛盾的問題,因為當epoch增加以後同樣也會導致耗時增加從而速度下降。因此我們需要尋找最好的Batch_Size。
再次重申:Batch_Size的正確選擇是為了在記憶體效率和記憶體容量之間尋找最佳平衡。
iteration:中文翻譯為迭代。
迭代是重複反饋的動作,神經網路中我們希望通過迭代進行多次的訓練以達到所需的目標或結果。
每一次迭代得到的結果都會被作為下一次迭代的初始值。
一個迭代=一個正向通過+一個反向通過。
epoch:中文翻譯為時期。
一個時期=所有訓練樣本的一個正向傳遞和一個反向傳遞。
深度學習中經常看到epoch、iteration和batchsize,下面按照自己的理解說說這三個區別:
(1)batchsize:批大小。在深度學習中,一般採用SGD訓練,即每次訓練在訓練集中取batchsize個樣本訓練;
(2)iteration:1個iteration等於使用batchsize個樣本訓練一次;
(3)epoch:1個epoch等於使用訓練集中的全部樣本訓練一次;
舉個例子,訓練集有1000個樣本,batchsize=10,那麼:
訓練完整個樣本集需要:
100次iteration,1次epoch。