opencv3.3 級聯分類器生成xml以及遇到的一些問題
opencv3.3 訓練級聯分類器訓練成功 來分享一波
今天遇到一位群友 對於級聯分類器有點問題 於是我決定把訓練的過程分享出來,並且和大家說說訓練過程中可能會出現的問題。
建立樣本步驟:
準備訓練集
首先 準備好訓練集 正樣本和負樣本 (我做的是車牌識別 所以選取的正樣本是車牌),
正樣本放在positive資料夾下的img資料夾裡(positive上面那個img資料夾存放的負樣本,大家不要混淆了)
正樣本的話 不需要相同大小 ,但是一定要相同比例 ,怕出問題的的就把正樣本變成相同大小吧。
我用的60*17的車牌圖片
負樣本的話,是指不包含正樣本的其他任意圖片,最好能有各種不同大小的不同場景的圖片。
我將負樣本放在img目錄下
這個負樣本是網上下的 相同大小 20*20 有點粗糙 大家不要學我 。。(最好是能有各種不同大小不同場景的!!)
樣本準備好了 接下來生成路徑
為正負樣本生成描述檔案:
將資料夾下的圖片遍歷一遍 儲存到txt檔案裡,可以用程式碼,也可以手動的複製貼上路徑寫入txt。。
我用的java將資料夾下的圖片遍歷出來的 ,java程式碼在下面連結
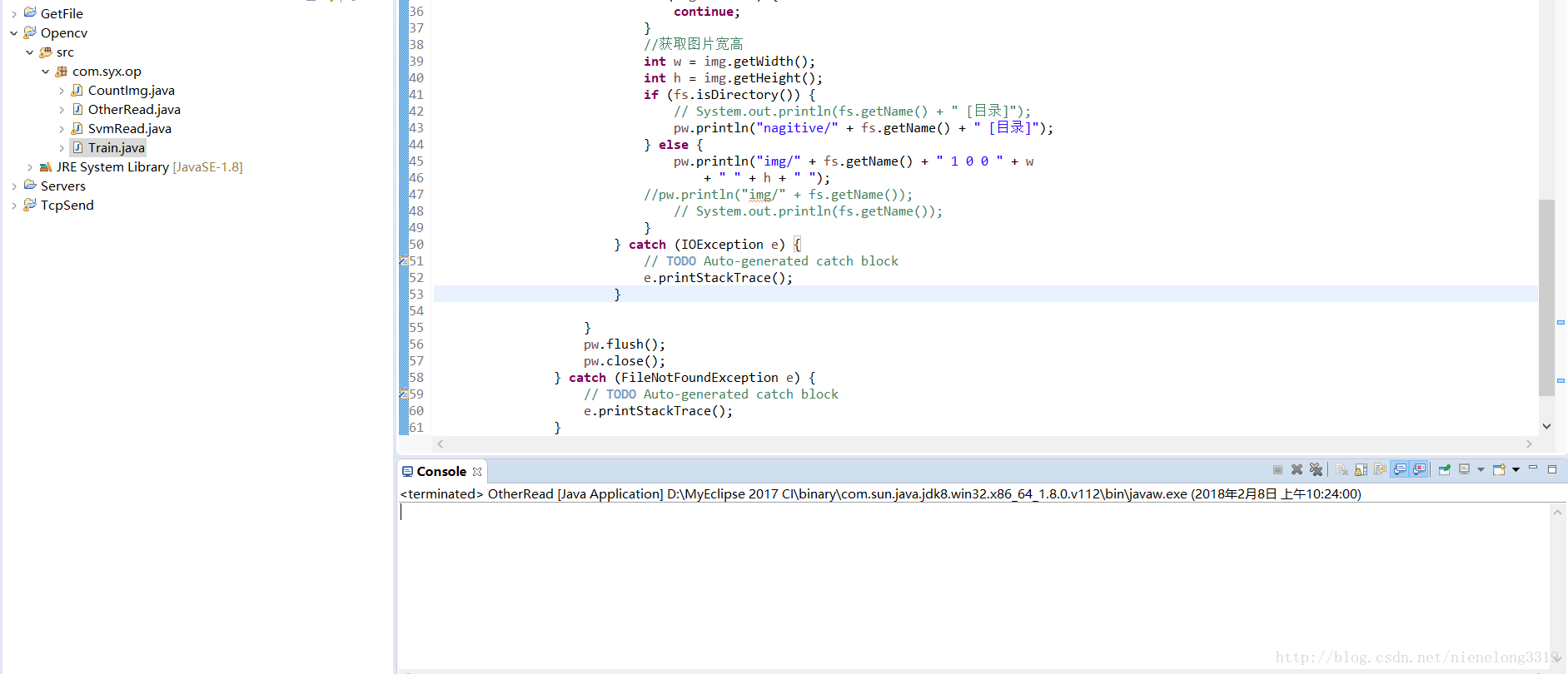
接下來展示一下存放正樣本路徑的txt的內容
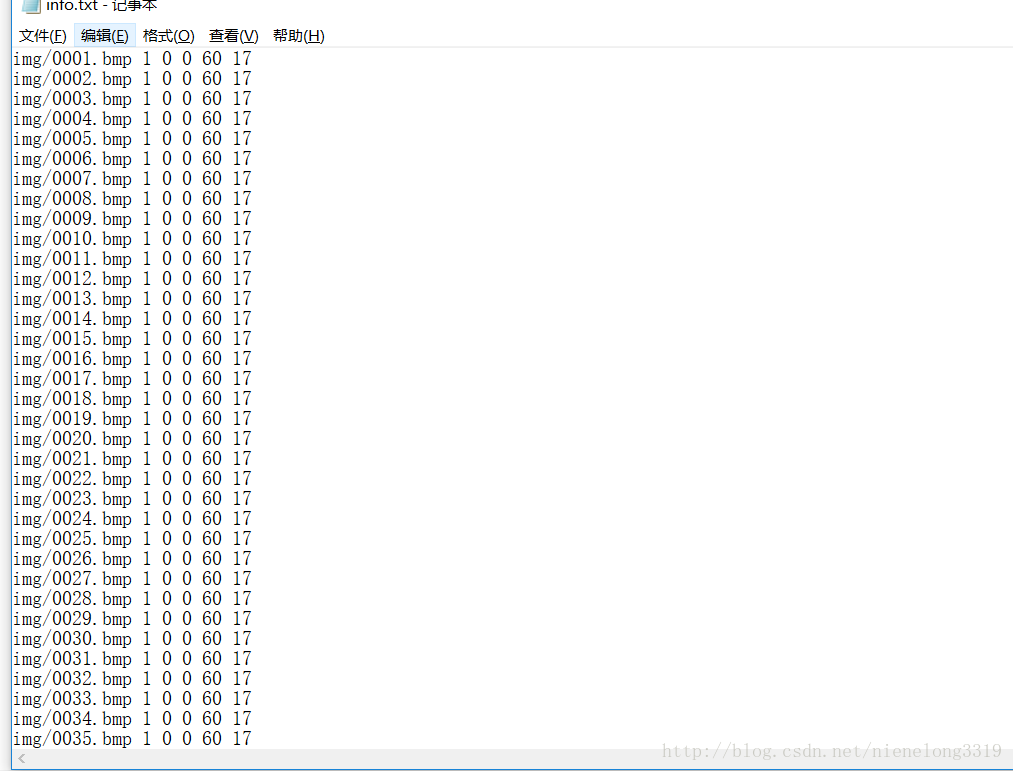
正樣本用描述檔案格式描述 如下
[filename] [# of objects] [[x y width height] [... 2nd object] ...]
x y指的是圖片左上角座標 width height指的是圖片寬高
舉個例子:
img/0001.bmp 1 0 0 60 17
1代表一個檔案 0 0 代表左上角x y座標 60 17 表示寬高
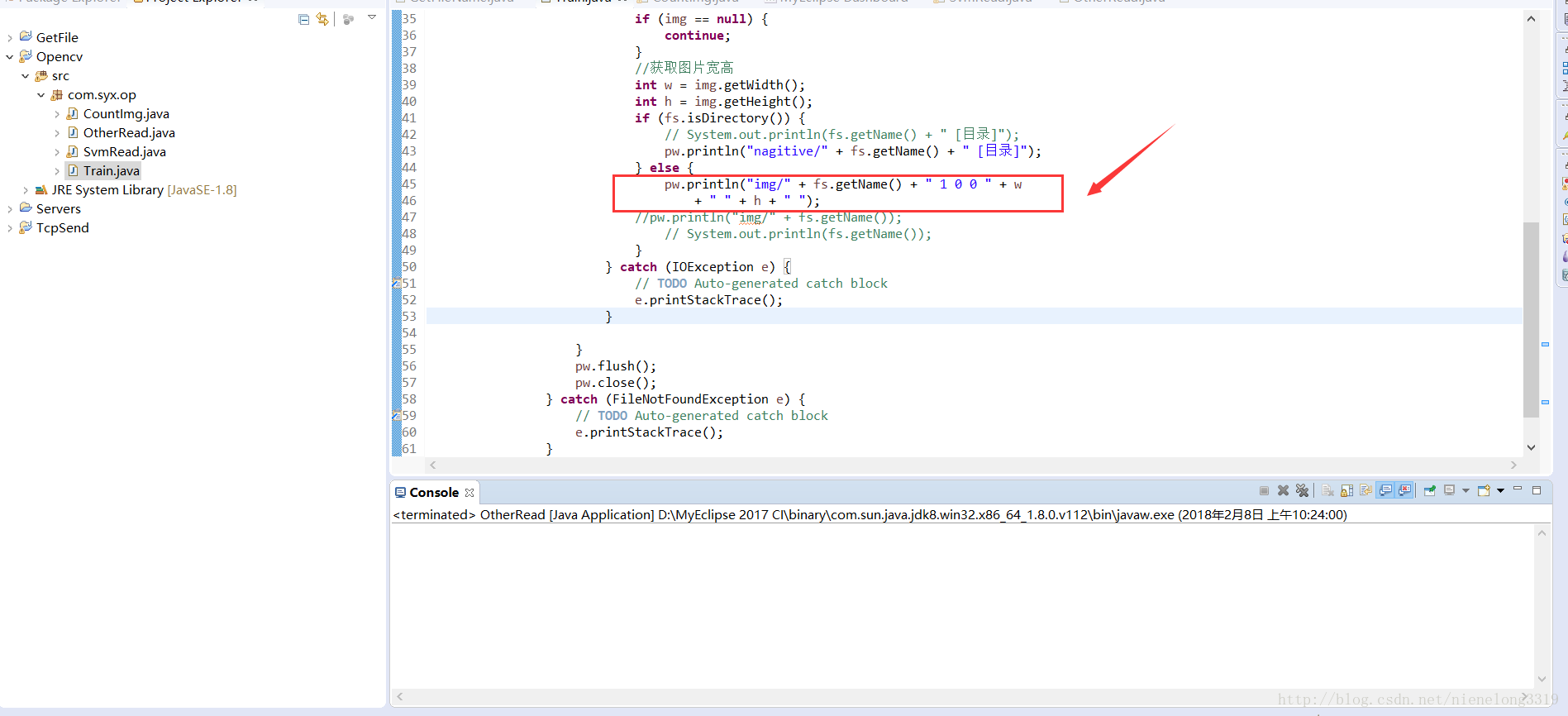
看這個紅框程式碼 自己領悟
然後就是負樣本的txt檔案 負樣本用集合檔案格式描述
集合檔案格式(collection file format)就是如下形的描述檔案:
[filename]
我將負樣本放在bg.txt檔案下

建立樣本 直接上圖
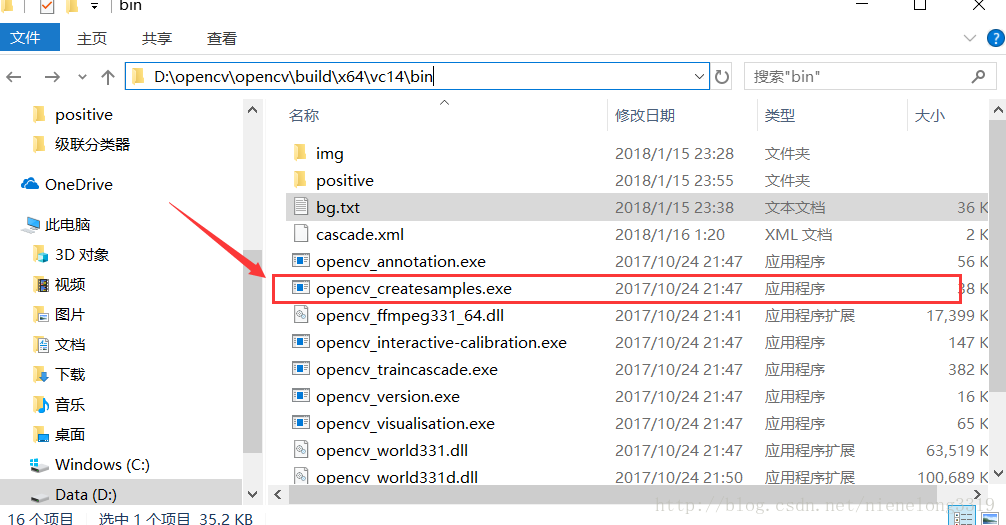
這就是生成樣本的exe,win+R 輸入cmd 進入該路徑
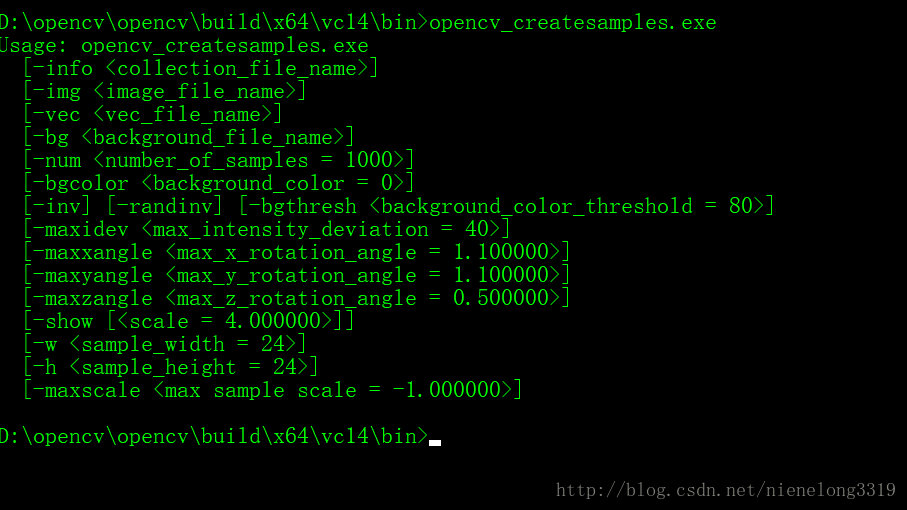
可以看到相關的一些引數 -vec 後面跟著要存放的路徑 -num指的是正樣本數量 -w是輸出樣本的寬 -h是輸出樣本的高 這就上面提到的 為什麼可以大小不相同 一定要相同比例的問題
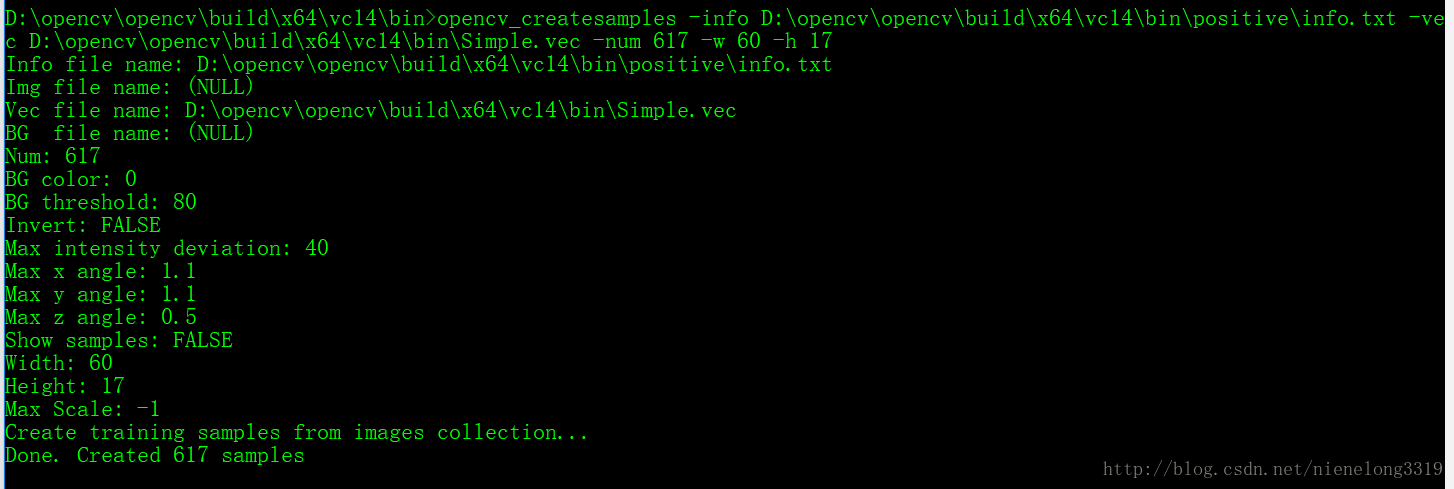
.vec檔案生成 。
在此注意 正樣本.txt需要ANSI編碼,那位群友使用的C#遍歷資料夾圖片 使用UNICODE編碼,會出現如下內容:parse errorDone. Created 0 samples 據說-num數量不對也會出現該情況
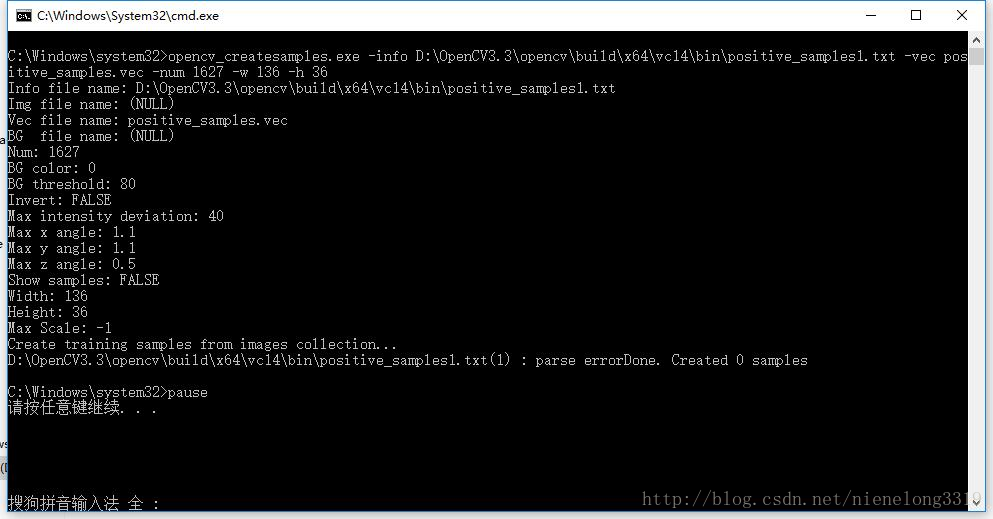
經測試 使用utf-8編碼 會出現如下情況
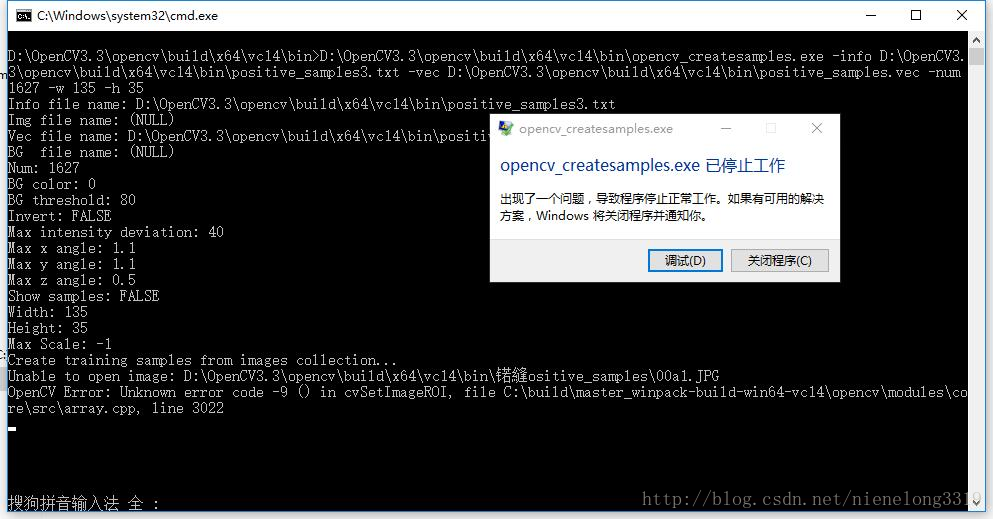
.vec檔案建立後 就是訓練分類器了
訓練分類器
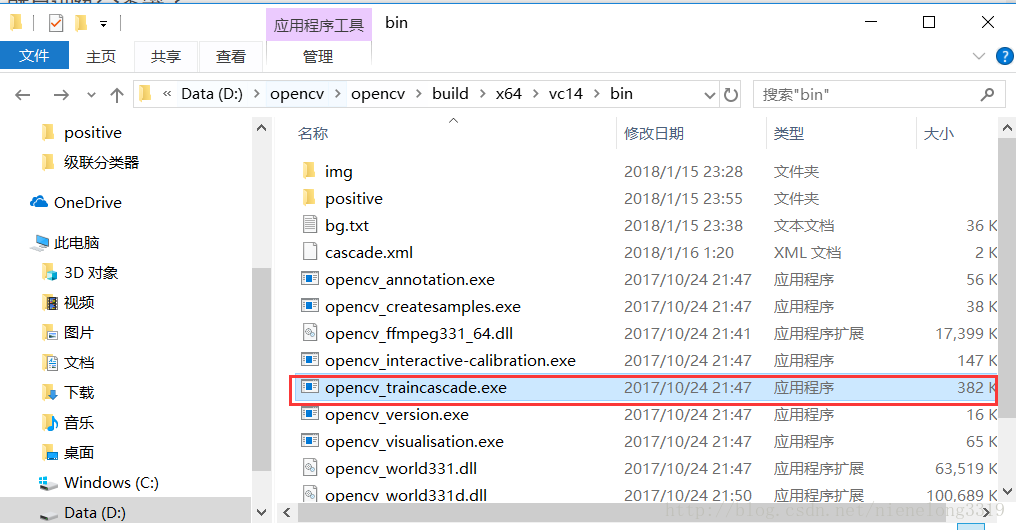
由該程式來實現,opencv2.x應該是叫haartarining.exe opencv3.x將haar和lbp整合成一個,就是上面紅框標註
和上面使用opencv_createsamples.exe相同 cmd 進入該目錄

使用命令 -data 是存放訓練好的分類器的路徑 -vec 就是存放.vec的路徑 -bg 負樣本描述檔案 -numPos 每一階段訓練的正樣本數量 -numNeg 每一階段訓練的負樣本數量 (網上說-numPos的引數要比實際正樣本數量小,-numNeg 的引數要比實際負樣本數量大 ,具體情況不太瞭解) -numStages 訓練階段數 (這個引數不能太大也不能太小 下面會說到) -featureType 選擇LBP還是HAAR 在此選用LBP -w -h 訓練樣本尺寸 和vec生成的尺寸大小相同 不然會宕機 -minHitRate 最小命中率 -maxFalseAlarmRate 最大虛警率 這兩個引數下面連結有說明 在此不多說
http://www.mamicode.com/info-detail-1724988.html
對了 提醒一下 如果 -featureType選擇HAAR 需要在加上 -mode ALL

然後就是回車 等待訓練
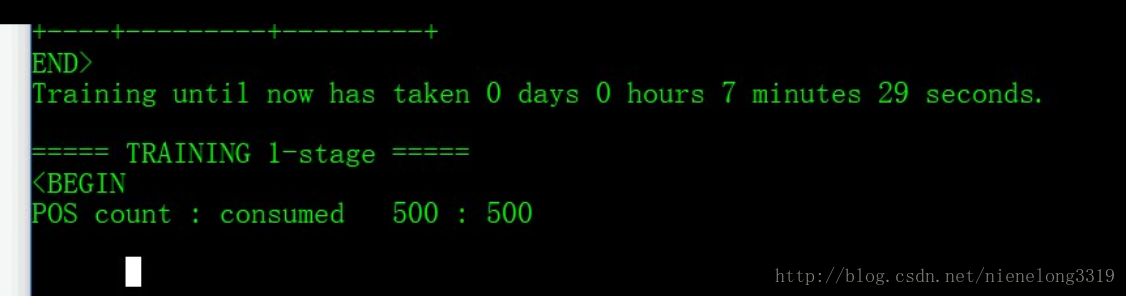
如果卡在POS這裡 不要緊張 慢慢等待 我是等了十分鐘左右才跳出 如果很久都沒跳出 -numStages引數說明太大 改小一點 即可 當然 如果太小的話 生成的xml文件分類效果可能就不太好
當出現如下提示 表示訓練完畢

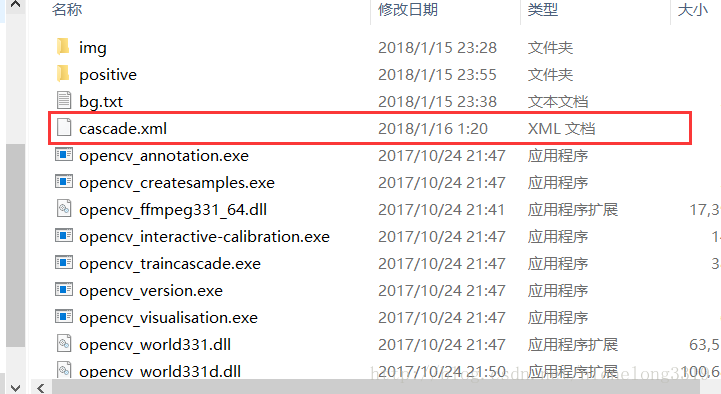
然後就可以看到一個xml文件生成 , 底下的那個stage0.xml stage1.xml params.xml是是每一階段訓練生成的xml,最終生成的cascade.xml
訓練過程會有很多問題 大家多嘗試 正樣本負樣本最好 1:3 ,1:4 比如我正樣本617個 負樣本2300多個
然後就是使用我們訓練的xml檔案了