
聚類效果好壞的評價指標
《Understanding of Internal Clustering Validation Measures》
發表在2010IEEE International Conference on Data Mining
應該譯為“內部聚類效果測量的一些理解”,我譯成了大白話,也沒錯,這篇文章講的就是如何評價你聚類好壞的。
原文下載:http://pan.baidu.com/s/1jHDvyq6
下面譯文開始:
#----------------------------------------------------------------分割線----------------------------------------------------------------#
摘要
眾所周知,聚類效果的好壞直接會影響要聚類的效果。大體上,聚類的效果的好壞會又兩類指標衡量,一類是外部聚類效果,一類是內部聚類效果。在這篇論文中,我們只探討內部聚類效果(具體什麼是內部聚類效果,為什麼用內部聚類效果進行評價看下一節),並給詳細的給出了11中評價聚類效果好壞的評價演算法,這11種演算法應用在5中聚類環境中以展現出他們到底誰更適應“惡劣多變”的聚類環境。
1.介紹
聚類是一種非常重要的非監督學習技術,他的任務是將目標樣本分成若干個簇(cluster),並且保證每個簇之間樣本儘量的接近,並且不同簇的樣本間距離儘量的遠。聚類技術被廣泛使用在影象處理和生物資訊學。作為一個非監督學習任務,評價聚類後的效果是非常有必要的,否則聚類的結果將很難被應用。
聚類的評價方式在大方向上被分成兩類,一種是分析外部資訊,另一種是分析內部資訊。外部資訊就是能看得見的直觀資訊,這裡指的是聚類結束後的類別號。雖然是個辦法,但是這種辦法沒法應用(舉個例子,如果要進行文字聚類,最後聚出了幾個類,聚類是否正確可以肉眼分析文章內容來判斷這幾個樣本是不是一個類,要是1w篇文章還能這麼做嗎?乾脆人幹吧,還要計算機幹嘛)。還有一種分析內部資訊的辦法,大致意思就是聚完類後會通過一些模型生成這個類聚的怎麼樣的引數,諸如熵和純度這種數學評價指標。
不想外部資訊進行評價,內部資訊評價是不需要肉眼識別聚類好壞的,也就是說根本就不用知道聚類後的標籤是什麼,只需要看個指數就行了。並且有很多時候,聚類後的標籤你是看不到,這樣就只能用內部資訊來評價聚類的好壞了。
在文章中,有很多已經被提出的聚類演算法好壞評價演算法,諸如CH,I,DB,SD,S_Dbw等等,然而這些演算法可能會受資料的“異常”而產生對結果的影響,諸如資料中的噪聲等。我們提出了五類可能會預測精度的資料異常情況:單調性、噪聲、密度、subcluster(沒翻譯過來,大致意思是有幾個簇離的很近,有幾個簇離得很遠)、傾斜分散(有些樣本少密度大,有些樣本多密度小)。每種情況都會用這11種評價演算法測試一下,最終發現,S_Dbw演算法完爆其他演算法。
2.簇的內部資訊評價
在這一節我會介紹有關簇的內部資訊的基本概念以及11中評價聚類好壞的演算法。
我們為了能讓簇內樣本距離儘量的近,簇與簇之間的樣本儘量的遠,我們需要用以下兩種指標來評價。
2.1緊湊度
緊湊度是衡量一個簇內樣本點之間的是否足夠緊湊的,比如到簇中心的平均距離啊,方差啊什麼的。
2.2分離度
分離度是衡量該樣本是否到其他簇的距離是否足夠的遠,這裡邊講個很多,那11種演算法的精髓也是在計算分離度,這裡我就不贅述了,原本也只是將個大致意思而已,畢竟那些演算法並不是作者寫的。這裡說說最NB的S_Dbw演算法:這種演算法是通過一種密度衡量公式來評價分離的好壞的。大致思路是,從所有的簇中心中至少有一個密度值要大於midpoint的密度值(這個沒太懂),然後通過SD演算法的緊湊度演算法搞出一個權重值判斷聚類的好壞(具體也沒時間深究了,好用就行啊)
2.3對簇內部資訊評價的理解
作者自己搞了點二維資料集,並用K-means做聚類來評價聚類的好壞,其中K-means演算法用的是CLUTO的庫(作者也是挺懶啊,誰知道這庫裡用了啥優化演算法,反正sklearn裡的kmeans用的是kmeans++還有多執行緒啥子的,實測nb的很啊)
2.3.1單調性的影響
沒太明白這個“單調性”是啥意思,反正樣本是這個樣子的(我猜是一種近乎於完美的樣本):

實驗結果如下圖:
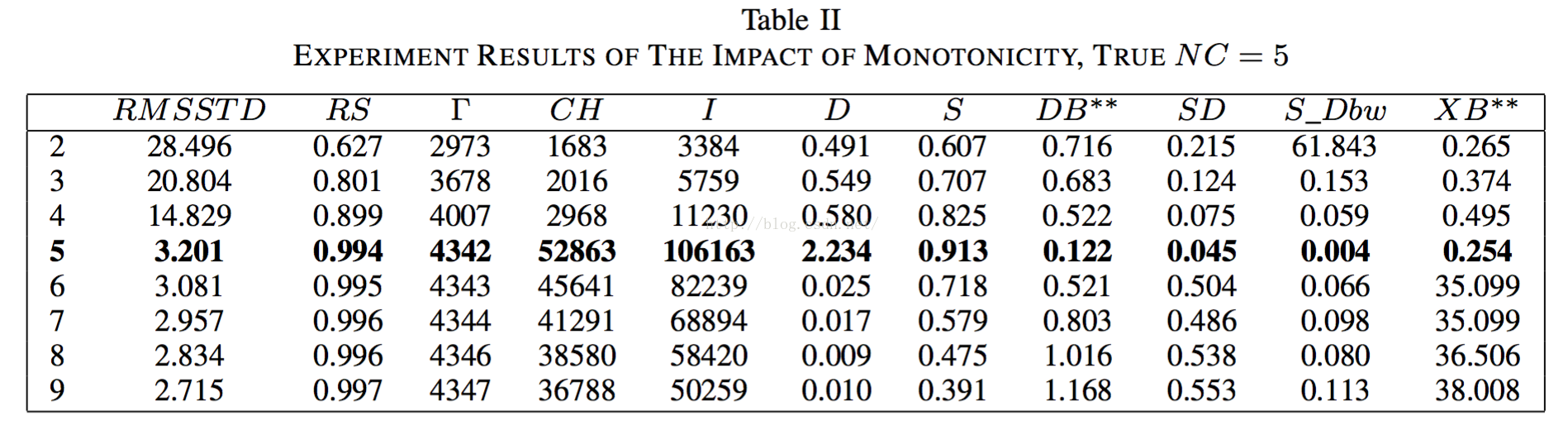
可以看到大家的結果都不錯,這是最理想的情況,所以分不出誰好誰壞。
2.3.2噪聲的影響
不多說了直接上資料圖和結果圖:
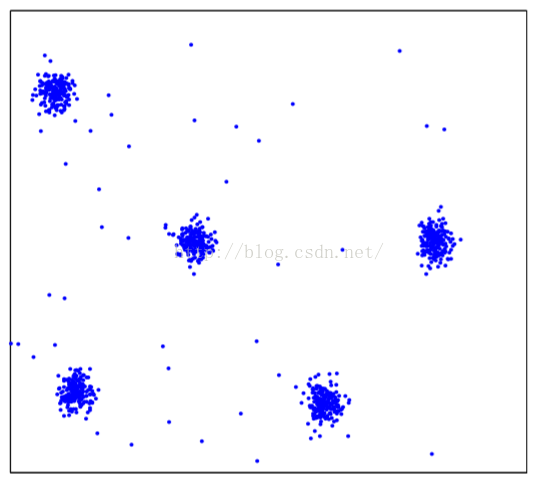
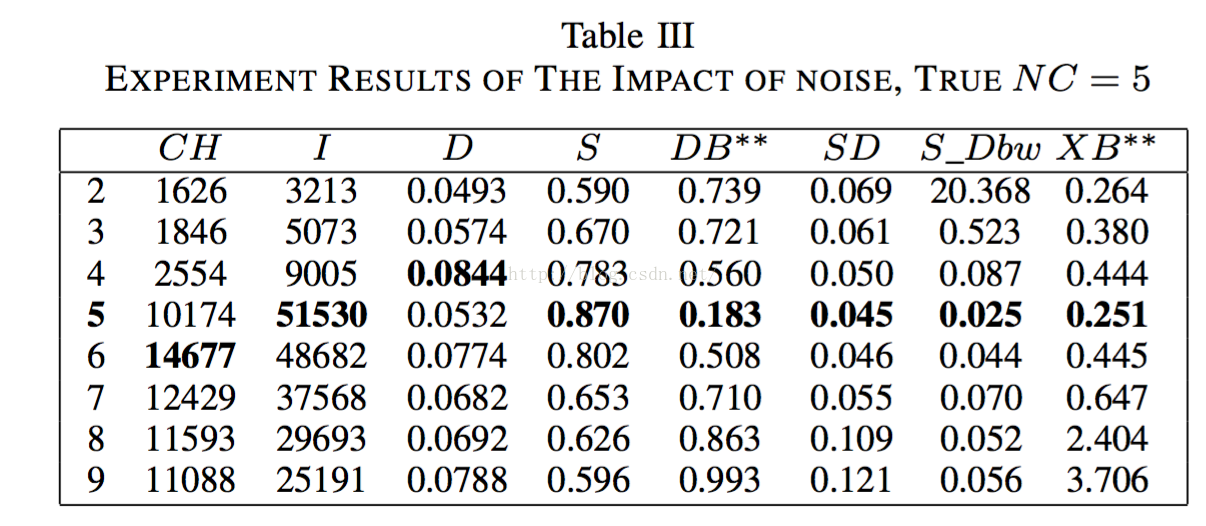
有幾個演算法已經遭不住了
2.3.3樣本密度差異的影響
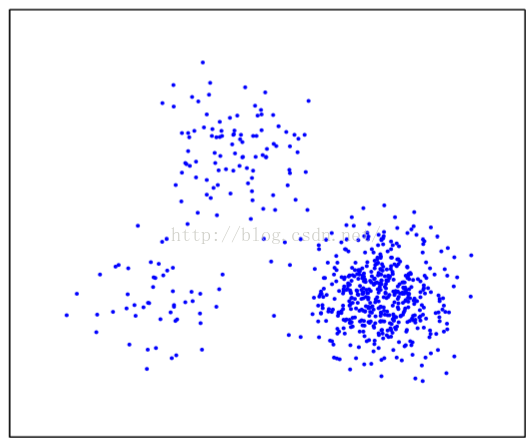
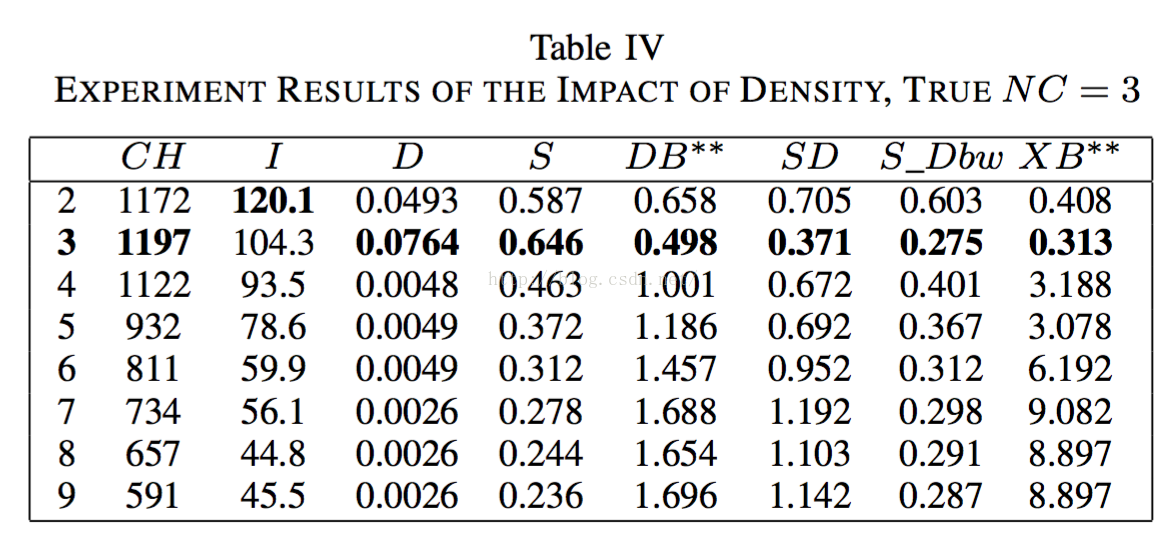
2.3.4subcluster的影響
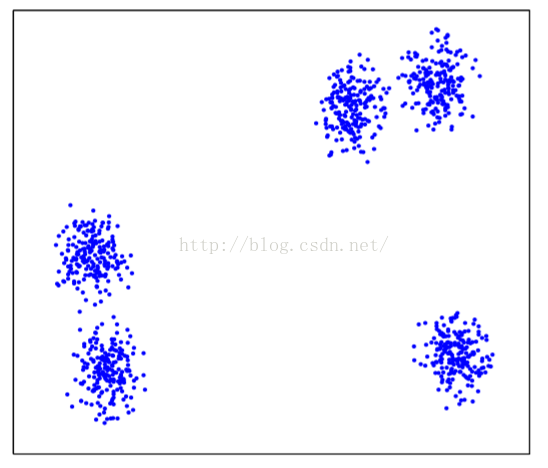
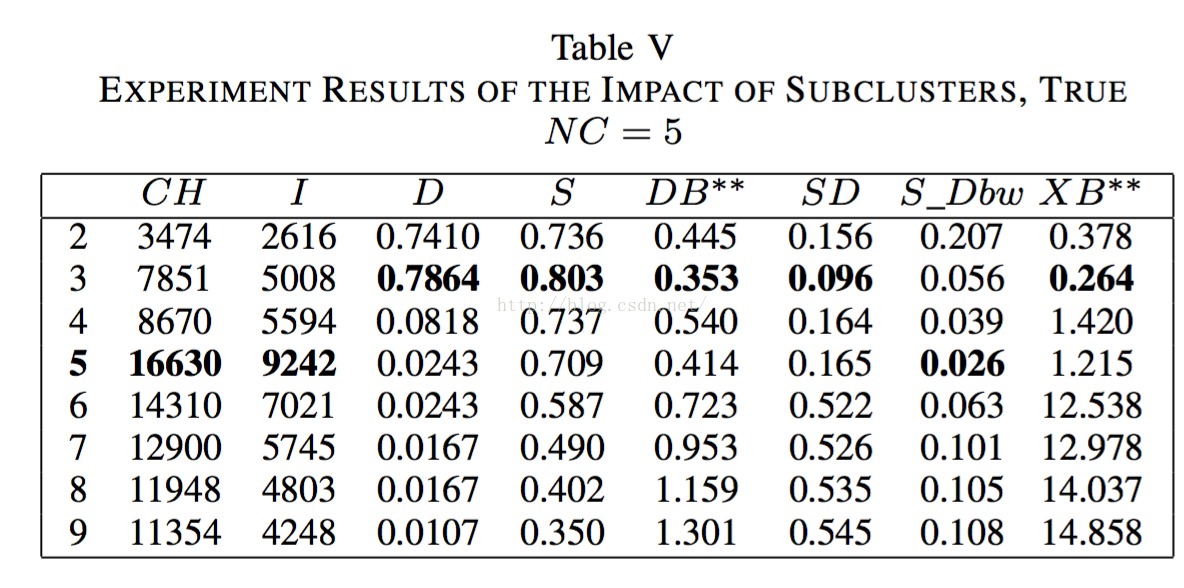
2.3.5傾斜分散的影響
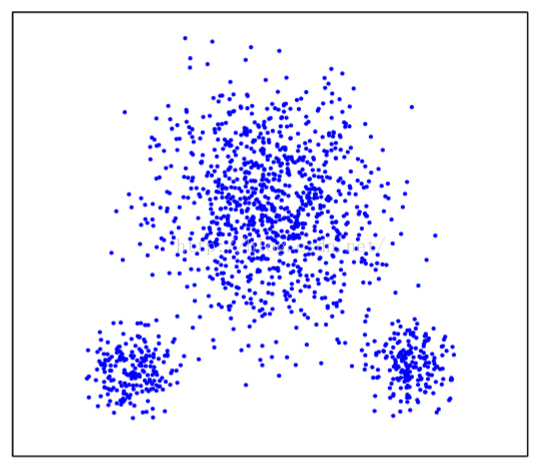
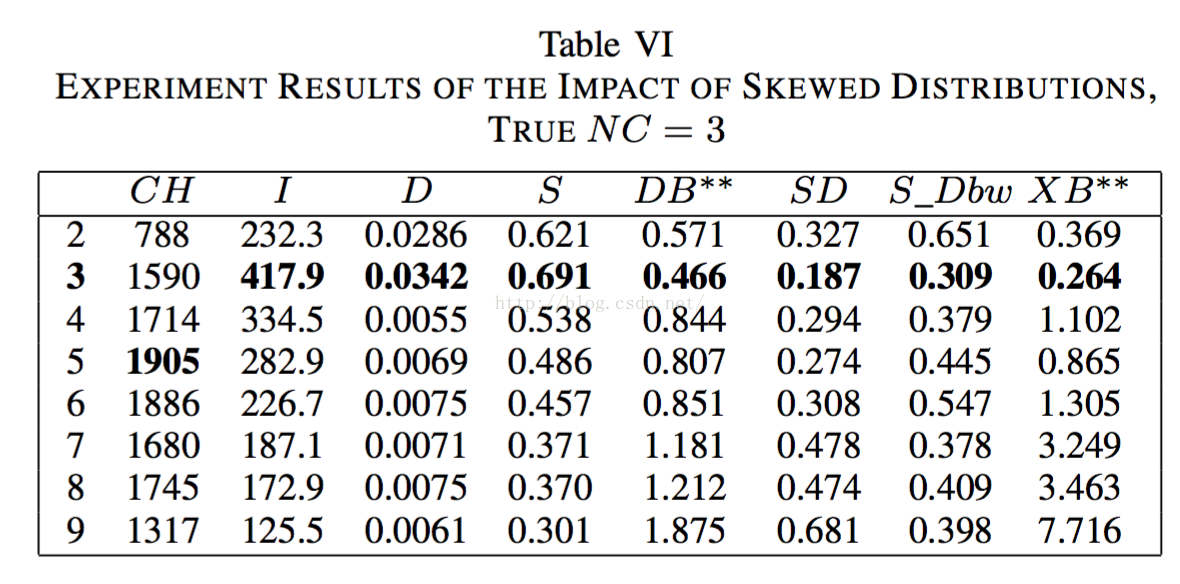
看了這些結果圖不用多說,S_Dbw演算法實在太nb了,都不會有失誤,但是這是個二維的聚類,所文字聚類怎麼也得上百維起,實際效果咋樣不得而知。
另外!聚類演算法也會有影響,但是這篇文章要比較評價聚類效果演算法好壞的討論,因此製作了簡單的對比,如下圖:
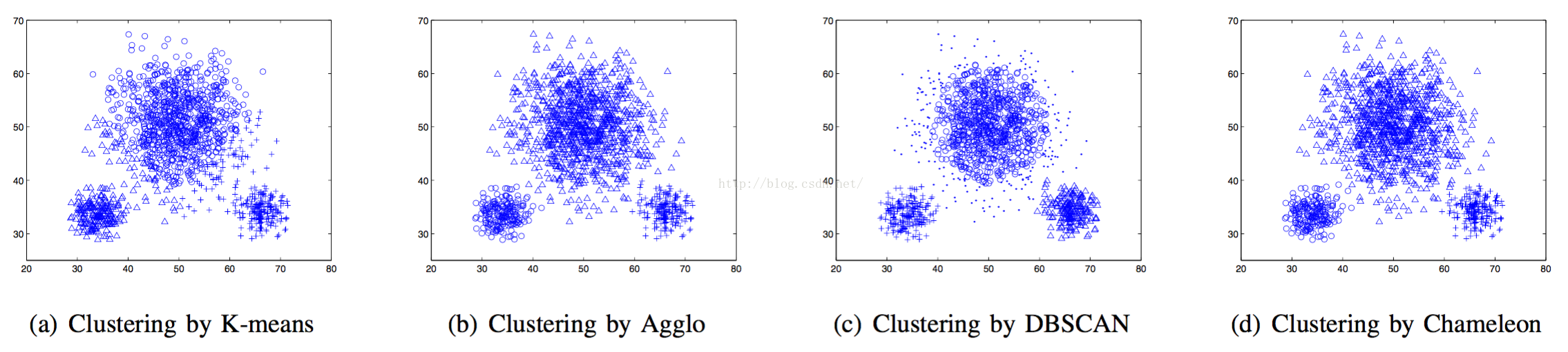
學校學的kmeans和dbscan效果實在不咋地。。。
剩下倆是何方神聖,我得好好搞搞