
增強學習(三)----- MDP的動態規劃解法
上一篇我們已經說到了,增強學習的目的就是求解馬爾可夫決策過程(MDP)的最優策略,使其在任意初始狀態下,都能獲得最大的Vπ值。(本文不考慮非馬爾可夫環境和不完全可觀測馬爾可夫決策過程(POMDP)中的增強學習)。
那麼如何求解最優策略呢?基本的解法有三種:
動態規劃法(dynamic programming methods)
蒙特卡羅方法(Monte Carlo methods)
時間差分法(temporal difference)。
動態規劃法是其中最基本的演算法,也是理解後續演算法的基礎,因此本文先介紹動態規劃法求解MDP。本文假設擁有MDP模型M=(S, A, Psa, R)的完整知識。
1. 貝爾曼方程(Bellman Equation)
上一篇我們得到了Vπ和Qπ的表示式,並且寫成了如下的形式
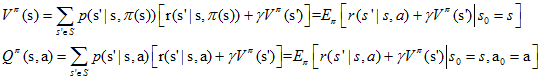
在動態規劃中,上面兩個式子稱為貝爾曼方程,它表明了當前狀態的值函式與下個狀態的值函式的關係。
優化目標π*可以表示為: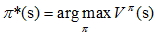
分別記最優策略π*對應的狀態值函式和行為值函式為V*(s)和Q*(s, a),由它們的定義容易知道,V*(s)和Q*(s, a)存在如下關係: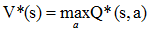
狀態值函式和行為值函式分別滿足如下貝爾曼最優性方程(Bellman optimality equation):
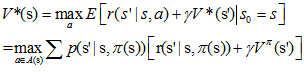
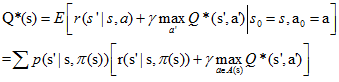
有了貝爾曼方程和貝爾曼最優性方程後,我們就可以用動態規劃來求解MDP了。
2. 策略估計(Policy Evaluation)
首先,對於任意的策略π,我們如何計算其狀態值函式Vπ(s)?這個問題被稱作策略估計,
前面講到對於確定性策略,值函式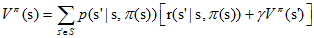
現在擴充套件到更一般的情況,如果在某策略π下,π(s)對應的動作a有多種可能,每種可能記為π(a|s),則狀態值函式定義如下:
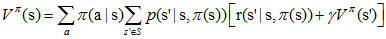
一般採用迭代的方法更新狀態值函式,首先將所有Vπ(s)的初值賦為0(其他狀態也可以賦為任意值,不過吸收態必須賦0值),然後採用如下式子更新所有狀態s的值函式(第k+1次迭代):
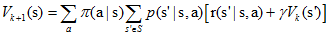
對於Vπ(s),有兩種更新方法,
第一種:將第k次迭代的各狀態值函式[Vk(s1),Vk(s2),Vk(s3)..]儲存在一個數組中,第k+1次的Vπ(s)採用第k次的Vπ(s')來計算,並將結果儲存在第二個陣列中。
第二種:即僅用一個數組儲存各狀態值函式,每當得到一個新值,就將舊的值覆蓋,形如[Vk+1(s1),Vk+1(s2),Vk(s3)..],第k+1次迭代的Vπ(s)可能用到第k+1次迭代得到的Vπ(s')。
通常情況下,我們採用第二種方法更新資料,因為它及時利用了新值,能更快的收斂。整個策略估計演算法如下圖所示:

3. 策略改進(Policy Improvement)
上一節中進行策略估計的目的,是為了尋找更好的策略,這個過程叫做策略改進(Policy Improvement)。
假設我們有一個策略π,並且確定了它的所有狀態的值函式Vπ(s)。對於某狀態s,有動作a0=π(s)。 那麼如果我們在狀態s下不採用動作a0,而採用其他動作a≠π(s)是否會更好呢?要判斷好壞就需要我們計算行為值函式Qπ(s,a),公式我們前面已經說過:
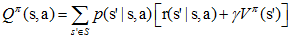
評判標準是:Qπ(s,a)是否大於Vπ(s)。如果Qπ(s,a)> Vπ(s),那麼至少說明新策略【僅在狀態s下采用動作a,其他狀態下遵循策略π】比舊策略【所有狀態下都遵循策略π】整體上要更好。
策略改進定理(policy improvement theorem):π和π'是兩個確定的策略,如果對所有狀態s∈S有Qπ(s,π'(s))≥Vπ(s),那麼策略π'必然比策略π更好,或者至少一樣好。其中的不等式等價於Vπ'(s)≥Vπ(s)。
有了在某狀態s上改進策略的方法和策略改進定理,我們可以遍歷所有狀態和所有可能的動作a,並採用貪心策略來獲得新策略π'。即對所有的s∈S, 採用下式更新策略:
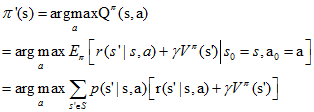
這種採用關於值函式的貪心策略獲得新策略,改進舊策略的過程,稱為策略改進(Policy Improvement)
最後大家可能會疑惑,貪心策略能否收斂到最優策略,這裡我們假設策略改進過程已經收斂,即對所有的s,Vπ'(s)等於Vπ(s)。那麼根據上面的策略更新的式子,可以知道對於所有的s∈S下式成立:
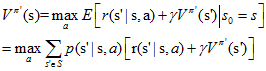
可是這個式子正好就是我們在1中所說的Bellman optimality equation,所以π和π'都必然是最優策略!神奇吧!
4. 策略迭代(Policy Iteration)
策略迭代演算法就是上面兩節內容的組合。假設我們有一個策略π,那麼我們可以用policy evaluation獲得它的值函式Vπ(s),然後根據policy improvement得到更好的策略π',接著再計算Vπ'(s),再獲得更好的策略π'',整個過程順序進行如下圖所示:
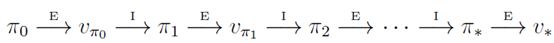
完整的演算法如下圖所示:

5. 值迭代(Value Iteration)
從上面我們可以看到,策略迭代演算法包含了一個策略估計的過程,而策略估計則需要掃描(sweep)所有的狀態若干次,其中巨大的計算量直接影響了策略迭代演算法的效率。我們必須要獲得精確的Vπ值嗎?事實上不必,有幾種方法可以在保證演算法收斂的情況下,縮短策略估計的過程。
值迭代(Value Iteration)就是其中非常重要的一種。它的每次迭代只掃描(sweep)了每個狀態一次。值迭代的每次迭代對所有的s∈S按照下列公式更新:
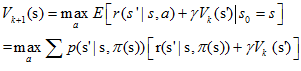
即在值迭代的第k+1次迭代時,直接將能獲得的最大的Vπ(s)值賦給Vk+1。值迭代演算法直接用可能轉到的下一步s'的V(s')來更新當前的V(s),演算法甚至都不需要儲存策略π。而實際上這種更新方式同時卻改變了策略πk和V(s)的估值Vk(s)。 直到演算法結束後,我們再通過V值來獲得最優的π。
此外,值迭代還可以理解成是採用迭代的方式逼近1中所示的貝爾曼最優方程。
值迭代完整的演算法如圖所示:

由上面的演算法可知,值迭代的最後一步,我們才根據V*(s),獲得最優策略π*。
一般來說值迭代和策略迭代都需要經過無數輪迭代才能精確的收斂到V*和π*, 而實踐中,我們往往設定一個閾值來作為中止條件,即當Vπ(s)值改變很小時,我們就近似的認為獲得了最優策略。在折扣回報的有限MDP(discounted finite MDPs)中,進過有限次迭代,兩種演算法都能收斂到最優策略π*。
至此我們瞭解了馬爾可夫決策過程的動態規劃解法,動態規劃的優點在於它有很好的數學上的解釋,但是動態要求一個完全已知的環境模型,這在現實中是很難做到的。另外,當狀態數量較大的時候,動態規劃法的效率也將是一個問題。下一篇介紹蒙特卡羅方法,它的優點在於不需要完整的環境模型。
PS: 如果什麼沒講清楚的地方,歡迎提出,我會補充說明...