
ES整合ik分詞並測試
一、先啟動Elasticsearch和IK
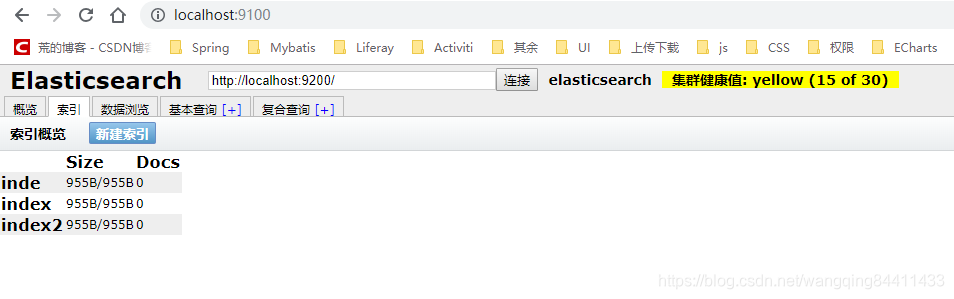
二、訪問http://localhost:9100/如下圖:
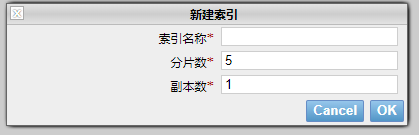
新建索引:輸入索引名稱,點選OK
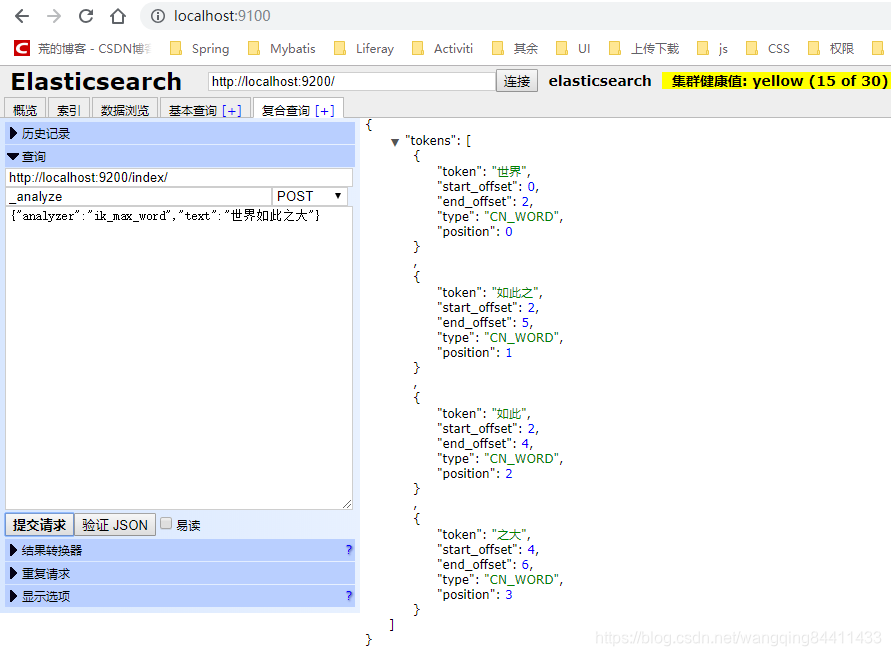
三、測試分詞:
總結: ES2.0版本與ES5.0以後的版本對比以及注意事項
1、5.0以後移除名為 ik 的analyzer和tokenizer,請分別使用 ik_smart 和 ik_max_word(也就是5.0之前進行測試的時候需要將上面中的ik_max_word換成ik關鍵字)
2、ES6.0與ik6.0進行整合安裝之後,只能通過head工具來進行測試,通過url進行測試的時候會報錯,這是一個bug已經提交到gethub上了,希望社群管理能及時更正(親測5.5.1版本沒問題)。
3、ES5.0之後的ik_smart和ik_max_word說明
ik_max_word: 會將文字做最細粒度的拆分,比如會將“我是中國人”拆分為“我,是,中國人,中國,國人”,會窮盡各種可能的組合。
ik_smart: 會做最粗粒度的拆分,比如會將“我是中國人”拆分為“我,是,中國人”。
相關推薦
ES整合ik分詞並測試
一、先啟動Elasticsearch和IK 二、訪問http://localhost:9100/如下圖: 新建索引:輸入索引名稱,點選OK 三、測試分詞: 總結: ES2.0版本與ES5.0以後的版本對比以及注意事項
solr-4.10.3 安裝在windows 7 並整合IK分詞器
硬體環境 window版本為:windows 7 64位 軟體環境 JDK版本:1.7.0_17 solr版本:4.10.3 tomcat版本:tomcat 7 安裝過程 步驟一:將下載好的solr-4.10.4.zip解壓,解壓後拷貝%solrh
ElasticSearch測試、IK分詞簡單測試(PHP)
以下全是測試程式碼:如有需要了解安裝 ElasticSearch和IK分詞的可參考:https://blog.csdn.net/weixin_42579642/article/details/84317099 use Elasticsearch\ClientBuilder; cla
Elasticsearch 系列指南(三)——整合ik分詞器
{ "tokens": [ { "token": "聯", "start_offset": 0, "end_offset": 1, "type": "<IDEOGRAPHIC>
solr7安裝以及整合ik分詞器
今天來研究了一下solr,以及怎麼整合ik分詞器,把研究的過程記錄下來,整個過程是在windows 7系統中完成的。1、solr7環境要求solr7.2.1需要java8環境,且需要在環境變數中新增 JAVA_HOME變數,指向jdk1.8的目錄,如下圖:2、下載solr並啟
ElasticSearch入門 - 整合ik分詞器
lucene由於是jar工具包,如果要在使用lucene的環境下使用ik分詞器,只需匯入對應jar,做一些配置就OK.但是ES不是工具包了,是伺服器.怎麼整合呢? 以外掛的方式整合ES伺服器,客戶端只需告訴我們某個欄位要用這
solr5.5整合IK分詞及mysql定時資料同步的開發記錄
目錄 1.前言 2.java環境 2.1 安裝jdk 2.1.1 64位安裝 2.1.2 32位安裝 2.1.3 環境變數 2.1.4 重新整理許可權 2.1.5 確認安裝 3 安裝tomcat8 3.1 修改埠號 3.2 設定tomcat-user
(2)ElasticSearch在linux環境中整合IK分詞器
1.簡介 ElasticSearch預設自帶的分詞器,是標準分詞器,對英文分詞比較友好,但是對中文,只能把漢字一個個拆分。而elasticsearch-analysis-ik分詞器能針對中文詞項顆粒度進行粗細提取,所以對中文搜尋是比較友好的。IK分詞器有兩種型別ik_smart和ik_max_word,前者提
docker之es+es-head+kibana+ik分詞器安裝
data elastics work str search url 使用 數據 head 一、es 第一步:搜索docker search elasticsearch第二步:下載鏡像第三步:創建數據文件夾和配置文件宿主服務器創建文件夾mkdir -p /docker/es1
ES ik分詞器使用技巧
match查詢會將查詢詞分詞,然後對分詞的結果進行term查詢。 然後預設是將每個分詞term查詢之後的結果求交集,所以只要分詞的結果能夠命中,某條資料就可以被查詢出來,而分詞是在新建索引時指定的,只有text型別的資料才能設定分詞策略。 新建索引,並指定分詞策略: PUT mail_test3 {
ElasticSearch實戰二(es基本操作以及IK分詞器的安裝)
1 基本概念 1.1 Node 與 Cluster Elastic 本質上是一個分散式資料庫,允許多臺伺服器協同工作,每臺伺服器可以執行多個 Elastic 例項。 單個 Elastic 例項稱為一個節點(node)。一組節點構成一個叢集(cluster)。 1.2 Index El
IK分詞器下載、使用和測試
對於Win10x86、Ubuntu環境均適用~ 1.下載 為什麼要使用IK分詞器呢?最後面有測評~ 如果選擇下載原始碼然後自己編譯的話,使用maven進行編譯: 在該目錄下,首先執行:mvn compile;,會生成一個target目錄,然後
ES中的分析器和IK分詞器外掛
一些概念 Token(詞元) 全文搜尋引擎會用某種演算法對要建索引的文件進行分析, 從文件中提取出若干Tokenizer(分詞器) Tokenizer(分詞器) 這些演算法叫做Tokenizer(分詞器) Token F
安裝ik分詞器以及版本和ES版本的相容性
一.檢視自己ES的版本號與之對應的IK分詞器版本 https://github.com/medcl/elasticsearch-analysis-ik/blob/master/README.md 二.下載與之對應的版本 https://github.com/medcl/elasticse
淺談es的原理、機制 ,IK分詞原理
1、分散式的架構es都有哪些機制? 1、主備 primary shard 的副本 replica shard primary shard不能和自己的replica shard放在同一個節點上、 2、容錯 使用選舉機制 master node宕機,選舉mast
使用xshell測試elasticsearch的ik分詞報錯問題
我的xshell是預設安裝的,今天把ik分詞安裝好了,然後按照安裝官方給的進行測試, 第一步 1.create a index curl -XPUT http://localhost:9200/index 沒問題 第二步 2.create a mapping
ElasticSearch-IK分詞器和整合使用
## 1.查詢存在問題分析 在進行字串查詢時,我們發現去搜索"搜尋伺服器"和"鋼索"都可以搜尋到資料; 而在進行詞條查詢時,我們搜尋"搜尋"卻沒有搜尋到資料; 究其原因是ElasticSearch的標準分詞器導致的,當我們建立索引時,欄位使用的是標準分詞器: >如果使用ES搜尋中文內容,預設是不支援中文
13.solr學習速成之IK分詞器
更新 api 一個 廣泛 針對 -i 處理器 多個 -1 IKAnalyzer簡介 IKAnalyzer是一個開源的,基於java語言開發的輕量級的中文分詞工具包。 IKAnalyzer特性 a. 算法采用“正向叠代最細粒度切分算法”,支持細粒度和最大詞
IK分詞器安裝
ik分詞器安裝簡介:當前講解的 IK分詞器 包的 version 為1.8。一、下載zip包。 下面有附件鏈接【ik-安裝包.zip】,下載即可。二、上傳zip包。 下載後解壓縮,如下圖。 打開修改修改好後打成zip包。# ‘elasticsearch.version‘ version o
ElasticSearch 用ik分詞器建立索引(java API)
tle creat analyzer undefined 全文搜索 () map 多用戶 tcl ElasticSearch是一個基於Lucene的搜索服務器。它提供了一個分布式多用戶能力的全文搜索引擎,基於RESTful web接口。Elasticsearch是用Ja