
CNN-目標檢測、定位、分割
1. 基本概念
1)CNN:Convolutional Neural Networks
2)FC:Fully Connected
3)IoU:Intersection over Union (IoU的值定義:Region Proposal與Ground Truth的視窗的交集比並集的比值,如果IoU低於0.5,那麼相當於目標還是沒有檢測到)
4)ICCV:International Conference on Computer Vision
5)R-CNN:Region-based Convolutional Neural Networks
6)AR:Average Recall
7)mAP:mean Average Precision
8)RPN:Region Proposal Networks
9)FAIR:Facebook AI Research
10)w.r.t.:with respect to
11)Image Classification(what?):影象分類
12)Object Detection(what+where?)、Localization、Segmentation:對角檢測、定位、分割
2. CNN基本知識
2.1 CNN的卷積流程
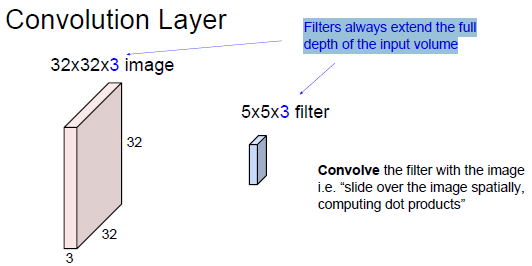

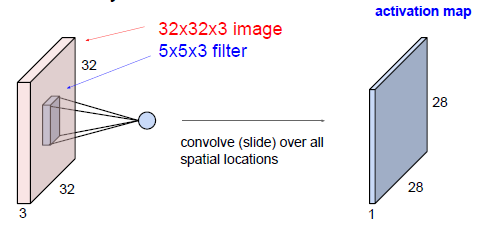
卷積計算過程如下圖所示:
我們剛才描述的即是卷積。可以把卷積想象為訊號處理中的一種奇特乘法。也可將兩個矩陣生成點積想象為兩個函式。影象就是底層函式,而過濾器就是在其上“捲過”的函式。
影象的主要問題在於其高維度,原因是對高維度的處理時間和運算能力成本很高。卷積網路就是為了通過各種方式降低影象的維度而設計的。過濾器步幅即是減少維度的一種方法,另一種方法是降取樣。
2.2 Activations maps的個數與Filter的個數一致
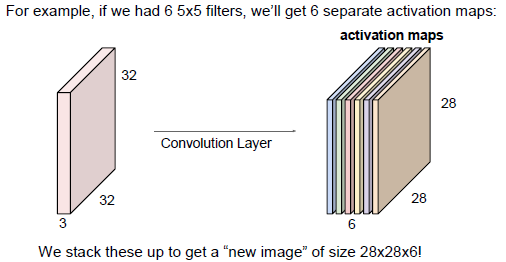
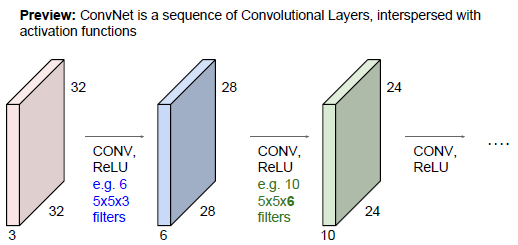
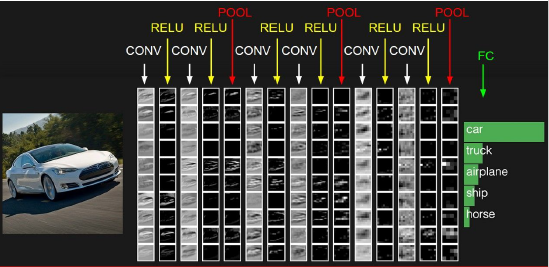
2.3 輸入層與Filter、Padding、Stride、引數和輸出層的關係

1) 引數個數由Filter定義及Filter個數決定,其公式為:
The number of parameters = (FxFxD + 1) * K
2)一個Activation Map共享一個Filter及其權重和偏差
3)Activation Map個數與Filter個數相同
2.4 Pooling(池化/降取樣)過程
1) Pooling在每個Activation Map上單獨做,在Pooling之後,Activation Map數量不變
Pooling層一般用於降維,將一個kxk的區域內取平均或取最大值,作為這一個小區域內的特徵,傳遞到下一層。傳統的Pooling層是不重疊的,使Pooling層重疊可以降低錯誤率,而且對防止過擬合有一定的效果。
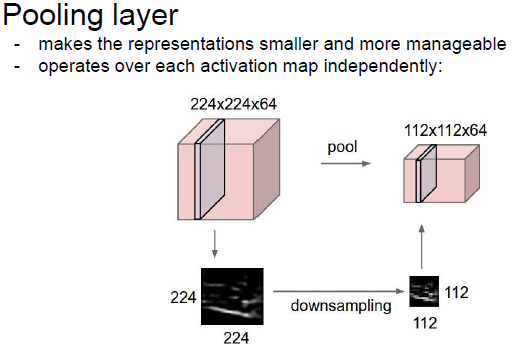
2)Pooling過程描述(Pooling過程不需要引數)

2.5 深度革命2015
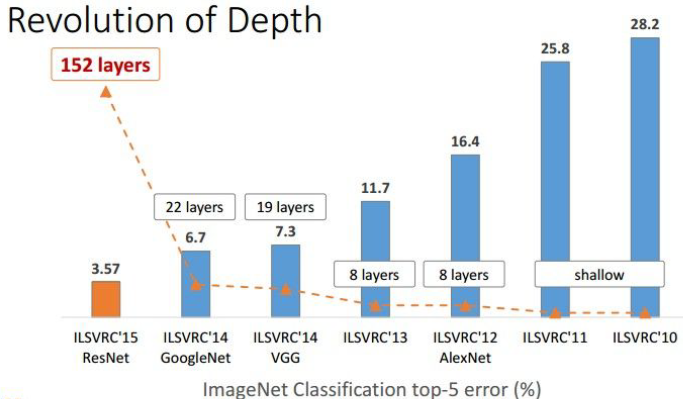
1)深度革命中遇到的問題:
隨著CNN網路的發展,尤其的VGG網路的提出,大家發現網路的層數是一個關鍵因素,貌似越深的網路效果越好。但是隨著網路層數的增加,問題也隨之而來。
(1)第一個問題: vanishing/exploding gradients(即梯度消失或爆炸):這就導致訓練難以收斂。但是隨著 normalized initialization and BN(Batch Normalization)的提出,解決了梯度消失或爆炸問題。
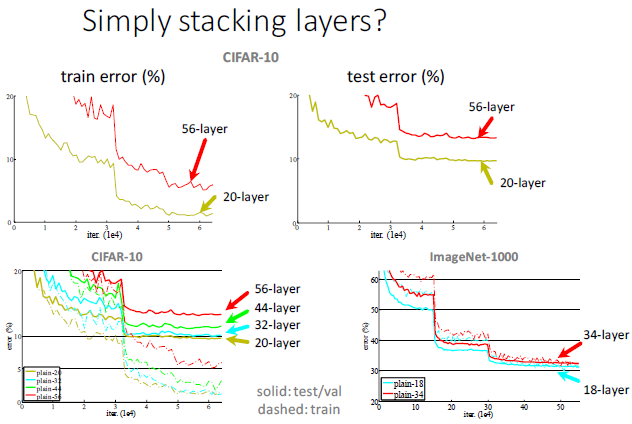
(2)第二個問題:網路越深,訓練誤差和測試誤差越大。在收斂問題解決後,又一個問題暴露出來:隨著網路深度的增加,系統精度得到飽和之後,迅速的下滑。讓人意外的是這個效能下降不是過擬合導致的。對一個合適深度的模型加入額外的層數導致訓練誤差變大。如下圖所示,可通過Deep Residual Learning 框架來解決這種因為深度增加而導致準確性下降問題。
3. 空間定位與檢測
3.1 計算機視覺任務
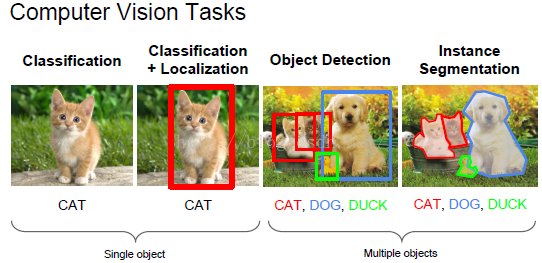
3.2 傳統目標檢測方法
傳統目標檢測流程:
1)區域選擇(窮舉策略:採用滑動視窗,且設定不同的大小,不同的長寬比對影象進行遍歷,時間複雜度高)
2)特徵提取(SIFT、HOG等;形態多樣性、光照變化多樣性、背景多樣性使得特徵魯棒性差)
3)分類器(主要有SVM、Adaboost等)
傳統目標檢測的主要問題:
1)基於滑動視窗的區域選擇策略沒有針對性,時間複雜度高,視窗冗餘
2)手工設計的特徵對於多樣性的變化沒有很好的魯棒性
3.3 基於侯選區域(Region Proposal)的深度學習目標檢測法
3.3.1 R-CNN (CVPR2014, TPAMI2015)
1)Region Proposal:可以解決滑動視窗的問題
候選區域(Region Proposal):是預先找出圖中目標可能出現的位置。它利用了影象中的紋理、邊緣、顏色等資訊,可以保證在選取較少視窗(幾千甚至幾百)的情況下保持較高的召回率(Recall)。
- Selective Search
- Edge Boxes
2)R-CNN:可以解決特徵魯棒性的問題
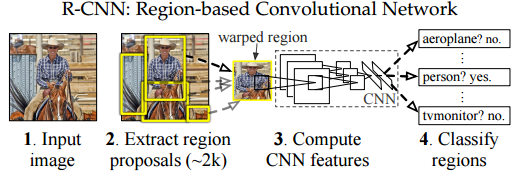
(1) 輸入測試影象
(2) 利用selective search演算法在影象中從下到上提取2000個左右的Region Proposal
(3) 將每個Region Proposal縮放(warp)成227x227的大小並輸入到CNN,將CNN的fc7層的輸出作為特徵
(4) 將每個Region Proposal提取到的CNN特徵輸入到SVM進行分類
注:1)對每個Region Proposal縮放到同一尺度是因為CNN全連線層輸入需要保證維度固定。
2)上圖少畫了一個過程——對於SVM分好類的Region Proposal做邊框迴歸(bounding-box regression),邊框迴歸是對region proposal進行糾正的線性迴歸演算法,為了讓region proposal提取到的視窗跟目標真實視窗更吻合。因為region proposal提取到的視窗不可能跟人手工標記那麼準,如果region proposal跟目標位置偏移較大,即便是分類正確了,但是由於IoU(region proposal與Ground Truth的視窗的交集比並集的比值)低於0.5,那麼相當於目標還是沒有檢測到。
3)R-CNN缺點:
(1) 訓練分為多個階段,步驟繁瑣: 微調網路+訓練SVM+訓練邊框迴歸器
(2) 訓練耗時,佔用磁碟空間大:5000張影象產生幾百G的特徵檔案
(3) 速度慢: 使用GPU, VGG16模型處理一張影象需要47s。
(4) 測試速度慢:每個候選區域需要執行整個前向CNN計算
(5) SVM和迴歸是事後操作:在SVM和迴歸過程中CNN特徵沒有被學習更新
針對速度慢的這個問題,SPP-NET給出了很好的解決方案。
3.3.2 SPP-NET (ECCV2014, TPAMI2015)
SSP-Net:Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition
先看一下R-CNN為什麼檢測速度這麼慢,一張圖都需要47s!仔細看下R-CNN框架發現,對影象提完Region Proposal(2000個左右)之後將每個Proposal當成一張影象進行後續處理(CNN提特徵+SVM分類),實際上對一張影象進行了2000次提特徵和分類的過程!這2000個Region Proposal不都是影象的一部分嗎,那麼我們完全可以對影象提一次卷積層特徵,然後只需要將Region Proposal在原圖的位置對映到卷積層特徵圖上,這樣對於一張影象我們只需要提一次卷積層特徵,然後將每個Region Proposal的卷積層特徵輸入到全連線層做後續操作。(對於CNN來說,大部分運算都耗在卷積操作上,這樣做可以節省大量時間)。
現在的問題是每個Region Proposal的尺度不一樣,直接這樣輸入全連線層肯定是不行的,因為全連線層輸入必須是固定的長度。SPP-NET恰好可以解決這個問題。
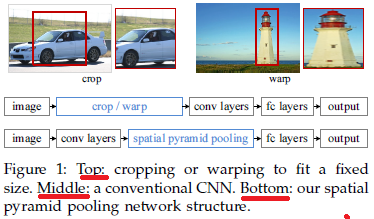
由於傳統的CNN限制了輸入必須固定大小(比如AlexNet是224x224),所以在實際使用中往往需要對原圖片進行crop或者warp的操作:
- crop:擷取原圖片的一個固定大小的patch
- warp:將原圖片的ROI縮放到一個固定大小的patch
無論是crop還是warp,都無法保證在不失真的情況下將圖片傳入到CNN當中:
- crop:物體可能會產生截斷,尤其是長寬比大的圖片。
- warp:物體被拉伸,失去“原形”,尤其是長寬比大的圖片
SPP為的就是解決上述的問題,做到的效果為:不管輸入的圖片是什麼尺度,都能夠正確的傳入網路。
具體思路為:CNN的卷積層是可以處理任意尺度的輸入的,只是在全連線層處有限制尺度——換句話說,如果找到一個方法,在全連線層之前將其輸入限制到等長,那麼就解決了這個問題。
具體方案如下圖所示:
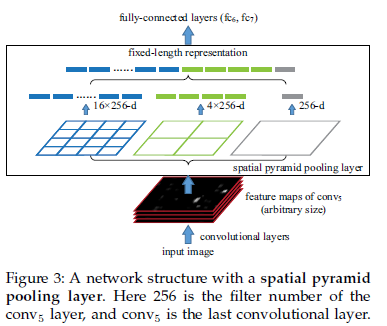
如果原圖輸入是224x224,對於conv5出來後的輸出,是13x13x256的,可以理解成有256個這樣的filter,每個filter對應一張13x13的activation map。如果像上圖那樣將activation map pooling成4x4 2x2 1x1三張子圖,做max pooling後,出來的特徵就是固定長度的(16+4+1)x256那麼多的維度了。如果原圖的輸入不是224x224,出來的特徵依然是(16+4+1)x256;直覺地說,可以理解成將原來固定大小為(3x3)視窗的pool5改成了自適應視窗大小,視窗的大小和activation map成比例,保證了經過pooling後出來的feature的長度是一致的。
使用SPP-NET相比於R-CNN可以大大加快目標檢測的速度,但是依然存在著很多問題:
(1) 訓練分為多個階段,步驟繁瑣: 微調網路+訓練SVM+訓練訓練邊框迴歸器
(2) SPP-NET在微調網路的時候固定了卷積層,只對全連線層進行微調,而對於一個新的任務,有必要對卷積層也進行微調。(分類的模型提取的特徵更注重高層語義,而目標檢測任務除了語義資訊還需要目標的位置資訊)
針對這兩個問題,RBG又提出Fast R-CNN, 一個精簡而快速的目標檢測框架。
3.3.3 Fast R-CNN(ICCV2015)
有了前邊R-CNN和SPP-NET的介紹,我們直接看Fast R-CNN的框架圖:
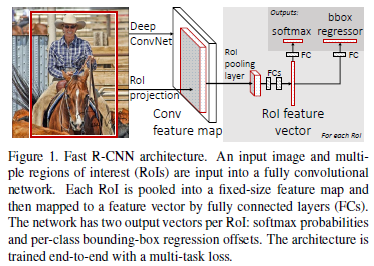
與R-CNN框架圖對比,可以發現主要有兩處不同:一是最後一個卷積層後加了一個ROI pooling layer,二是損失函式使用了多工損失函式(multi-task loss),將邊框迴歸直接加入到CNN網路中訓練。
(1) ROI pooling layer實際上是SPP-NET的一個精簡版,SPP-NET對每個proposal使用了不同大小的金字塔對映,而ROI pooling layer只需要下采樣到一個7x7的特徵圖。對於VGG16網路conv5_3有512個特徵圖,這樣所有region proposal對應了一個7*7*512維度的特徵向量作為全連線層的輸入。
(2) R-CNN訓練過程分為了三個階段,而Fast R-CNN直接使用softmax替代SVM分類,同時利用多工損失函式邊框迴歸也加入到了網路中,這樣整個的訓練過程是端到端的(除去region proposal提取階段)。
(3) Fast R-CNN在網路微調的過程中,將部分卷積層也進行了微調,取得了更好的檢測效果。
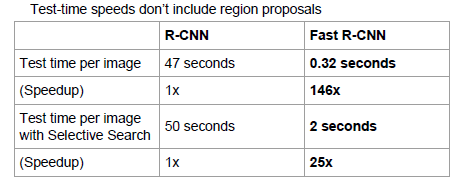
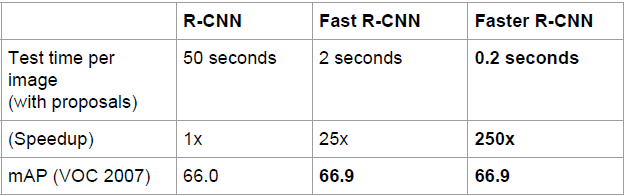
效能對比資料:
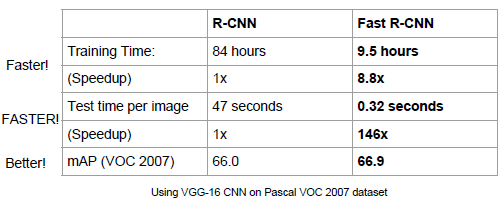
1)Fast R-CNN優點:
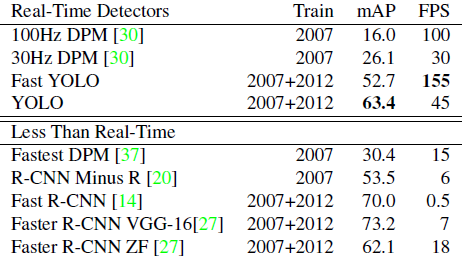
Fast R-CNN融合了R-CNN和SPP-NET的精髓,並且引入多工損失函式,使整個網路的訓練和測試變得十分方便。在Pascal VOC2007訓練集上訓練,在VOC2007測試的結果為66.9%(mAP),如果使用VOC2007+2012訓練集訓練,在VOC2007上測試結果為70%(資料集的擴充能大幅提高目標檢測效能)。使用VGG16每張影象總共需要3s左右。
2)Fast R-CNN 缺點:
Region Proposal的提取使用selective search,目標檢測時間大多消耗在這上面(提Region Proposal 2~3s,而提特徵分類只需0.32s),無法滿足實時應用,而且並沒有實現真正意義上的端到端訓練測試(region proposal使用selective search先提取處來)。那麼有沒有可能直接使用CNN直接產生Region Proposal並對其分類?Faster R-CNN框架就是符合這樣需要的目標檢測框架。
3.3.4 Faster R-CNN(NIPS2015)
Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks
在Region Proposal + CNN分類的這種目標檢測框架中,Region Proposal質量好壞直接影響到目標檢測任務的精度。如果找到一種方法只提取幾百個或者更少的高質量的假選視窗,而且召回率很高,這不但能加快目標檢測速度,還能提高目標檢測的效能(假陽例少)。RPN(Region Proposal Networks)網路應運而生。
1)RPN的核心思想
是使用卷積神經網路直接產生Region Proposal,使用的方法本質上就是滑動視窗。RPN的設計比較巧妙,RPN只需在最後的卷積層上滑動一遍,因為Anchor機制和邊框迴歸可以得到多尺度多長寬比的Region Proposal。
2)Faster R-CNN架構
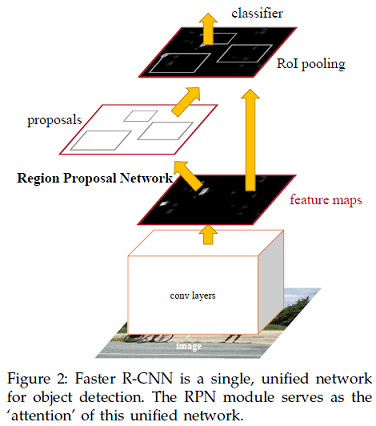
3)RPN架構
RPN採用任意大小的的影象作為輸入,並輸出一組候選的矩形,每個矩形都有一個物件分數。
RPN被用於訓練直接產生候選區域,不需要外部的候選區域。
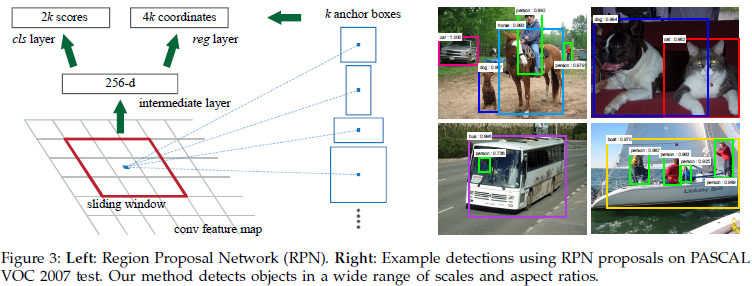
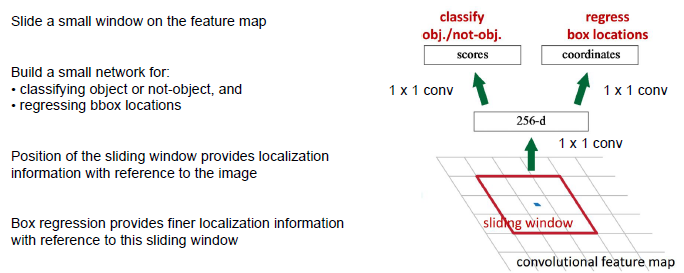

Anchor是滑動視窗的中心,它與尺度和長寬比相關,預設採3種尺度(128,256,512),3種長寬比(1:1,1:2,2:1),則在每一個滑動位置k=9 anchors。
我們直接看上邊的RPN網路結構圖(使用了ZF<Zeiler and Fergus model>模型),給定輸入影象(假設解析度為600*1000),經過卷積操作得到最後一層的卷積特徵圖(大小約為40*60)。在這個特徵圖上使用3*3的卷積核(滑動視窗)與特徵圖進行卷積,最後一層卷積層共有256個feature map,那麼這個3*3的區域卷積後可以獲得一個256維的特徵向量,後邊接cls layer(box-classification layer)和reg layer(box-regression layer)分別用於分類和邊框迴歸(跟Fast R-CNN類似,只不過這裡的類別只有目標和背景兩個類別)。3*3滑窗對應的每個特徵區域同時預測輸入影象3種尺度(128,256,512),3種長寬比(1:1,1:2,2:1)的region proposal,這種對映的機制稱為anchor。所以對於這個40*60的feature map,總共有約20000(40*60*9)個anchor,也就是預測20000個region proposal。
這樣設計的好處是什麼呢?雖然現在也是用的滑動視窗策略,但是:滑動視窗操作是在卷積層特徵圖上進行的,維度較原始影象降低了16*16倍(中間經過了4次2*2的pooling操作);多尺度採用了9種anchor,對應了三種尺度和三種長寬比,加上後邊接了邊框迴歸,所以即便是這9種anchor外的視窗也能得到一個跟目標比較接近的region proposal。
4)總結
Faster R-CNN將一直以來分離的region proposal和CNN分類融合到了一起,使用端到端的網路進行目標檢測,無論在速度上還是精度上都得到了不錯的提高。然而Faster R-CNN還是達不到實時的目標檢測,預先獲取Region Proposal,然後在對每個Proposal分類計算量還是比較大。比較幸運的是YOLO這類目標檢測方法的出現讓實時性也變的成為可能。
總的來說,從R-CNN, SPP-NET, Fast R-CNN, Faster R-CNN一路走來,基於深度學習目標檢測的流程變得越來越精簡,精度越來越高,速度也越來越快。可以說基於Region
Proposal的R-CNN系列目標檢測方法是當前目標最主要的一個分支。
3.3.5 R-FCN(2016.5)
顧名思議:全卷積網路,就是全部是卷積層,而沒有全連線層(fc)。
R-FCN(基於區域的檢測器)的方法是:在整個影象上共享計算,通過移除最後的fc層實現(即刪除了所有的子網路)。使用“位置敏感的得分圖”來解決了影象分類平移不變性與物件檢測平移變化之間的矛盾。
此矛盾為:物體分類要求平移不變性越大越好 (影象中物體的移動不用區分),而物體檢測要求有平移變化。所以,ImageNet 分類領先的結果證明儘可能有平移不變性的全卷積結構更受親睞。另一方面,物體檢測任務需要一些平移變化的定位表示。比如,物體的平移應該使網路產生響應,這些響應對描述候選框覆蓋真實物體的好壞是有意義的。我們假設影象分類網路的卷積層越深,則該網路對平移越不敏感。
CNN隨著網路深度的增加,網路對於位置(Position)的敏感度越來越低,也就是所謂的translation-invariance,但是在Detection的時候,需要對位置資訊有很強的的敏感度。
那麼ResNet-101的detection是怎麼做的?
在R-FCN之前,很簡單,把ROI-pooling層放到了前面的卷積層,然後後面的卷積層不共享計算,這樣一可以避免過多的資訊損失,二可以用後來的卷積層學習位置資訊。
R-FCN:採用全卷積網路結構作為 FCN,為給 FCN 引入平移變化,用專門的卷積層構建位置敏感分數地圖 (position-sensitive score maps)。每個空間敏感地圖編碼感興趣區域的相對空間位置資訊。 在FCN上面增加1個位置敏感 RoI 池化層來監管這些分數地圖。
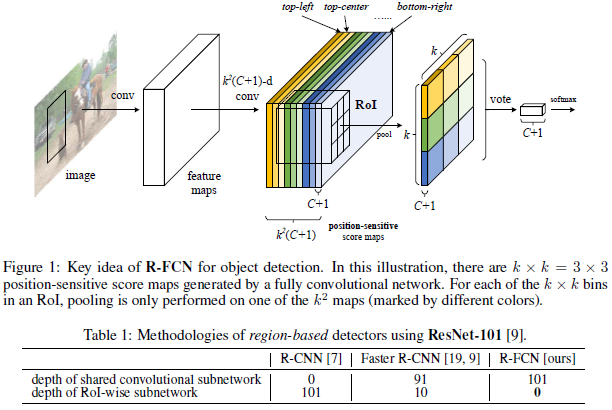
R-FCN思路就是利用最後一層網路通過FCN構成一個position-sensitive的feature map。具體而言,每一個proposal的位置資訊都需要編碼,那麼先把proposal分成k*k個grid,然後對每一個grid進行編碼。在最後一層map之後,再使用卷積計算產生一個k*k*(C+1)的map(k*k代表總共的grid數目,C代表class num,+1代表加入一個背景類)。
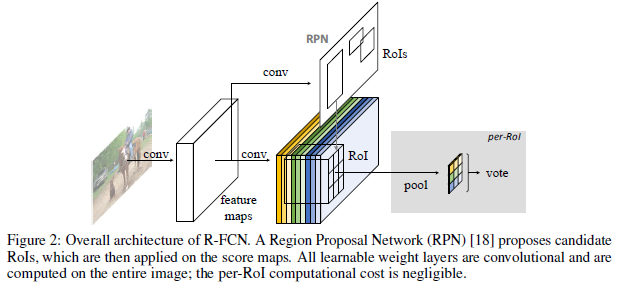
RPN 給出感興趣區域,R-FCN 對該感興趣區域分類。R-FCN 在與 RPN 共享的卷積層後多加1個卷積層。所以,R-FCN 與 RPN 一樣,輸入為整幅影象。但 R-FCN 最後1個卷積層的輸出從整幅影象的卷積響應影象中分割出感興趣區域的卷積響應影象。
R-FCN 最後1個卷積層在整幅影象上為每類生成k*k個位置敏感分數圖,有C類物體外加1個背景,因此有k*k(C+1)個通道的輸出層。k*k個分數圖對應描述位置的空間網格。比如,k×k=3×3,則9個分數圖編碼單個物體類的 {top−left,top−center,top−right,...,bottom−right}。
R-FCN 最後用位置敏感 RoI 池化層,給每個 RoI 1個分數。選擇性池化圖解:看上圖的橙色響應影象 (top−left),摳出橙色方塊 RoI,池化橙色方塊 RoI 得到橙色小方塊 (分數);其它顏色的響應影象同理。對所有顏色的小方塊投票 (或池化) 得到1類的響應結果。
產生完了這張map之後,再根據proposal產生一個長寬各為k,channel數目為C+1的score map。具體產生score map的方法是,假如k=3,C=20,那麼score map的20個類每個類都有3*3的feature,一共9個格子,每一個格子都記錄了空間資訊。而這每一個類的每一個格子都對應前面那個channel數為3*3*21的大map的其中一個channel的map。現在把score map中的格子對應的區域的map中的資訊取平均,然後這個平均值就是score
map格子中的值。最後把score map的值進行vote(avg pooling)來形成一個21維的向量來做分類即可。
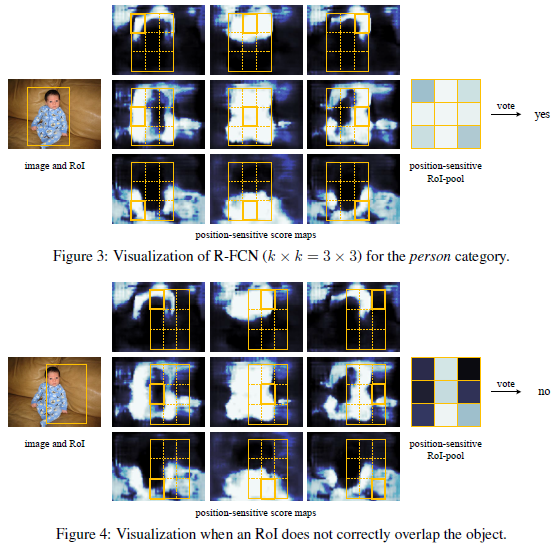
當分類正確時,該類通道的位置敏感分數圖 (中間) 的大多數橙色實線網格內的響應在整個 RoI 位置範圍內最強。
對應的bbox regression只需要把C+1設成4就可以了。
R-FCN採用的一些方法比Faster R-CNN的baseline提高了3個點,並且比原來Faster R-CNN更快(因為全部計算都共享了)。但是和改進過的Faster R-CNN相比(ROI Pooling提前那種)提高了0.2個點,速度快了2.5倍。所以目前為止這個方法的結果應該是所有方法中速度和Performance結合的最好的。
3.4 基於迴歸方法的深度學習目標檢測演算法
Faster R-CNN的方法目前是主流的目標檢測方法,但是速度上並不能滿足實時的要求。YOLO一類的方法慢慢顯現出其重要性,這類方法使用了迴歸的思想,即給定輸入影象,直接在影象的多個位置上回歸出這個位置的目標邊框以及目標類別。
3.4.1 YOLO (CVPR2016, oral)
YOLO:You Only Look Once: Unified, Real-Time Object Detection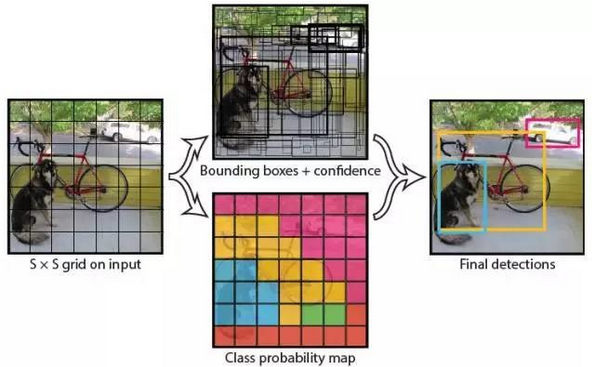 我們直接看上面YOLO的目標檢測的流程圖:
我們直接看上面YOLO的目標檢測的流程圖:(1) 給個一個輸入影象,首先將影象劃分成7*7(設S=7)的網格
(2) 對於每個網格,我們都預測2個邊框(包括每個邊框是目標的置信度以及每個邊框區域在多個類別上的概率)
(3) 根據上一步可以預測出7*7*2個目標視窗,然後根據閾值去除可能性比較低的目標視窗,最後NMS去除冗餘視窗即可。
可以看到整個過程非常簡單,不需要中間的Region Proposal在找目標,直接回歸便完成了位置和類別的判定。
 那麼如何才能做到直接在不同位置的網格上回歸出目標的位置和類別資訊呢?上面是YOLO的網路結構圖,前邊的網路結構跟GoogLeNet的模型比較類似,主要的是最後兩層的結構,卷積層之後接了一個4096維的全連線層,然後後邊又全連線到一個7*7*30維的張量上。實際上這7*7就是劃分的網格數,現在要在每個網格上預測目標兩個可能的位置以及這個位置的目標置信度和類別,也就是每個網格預測兩個目標,每個目標的資訊有4維座標資訊(中心點座標+長寬),1個是目標的置信度,還有類別數20(VOC上20個類別),總共就是(4+1)*2+20
= 30維的向量。這樣可以利用前邊4096維的全圖特徵直接在每個網格上回歸出目標檢測需要的資訊(邊框資訊加類別)。
那麼如何才能做到直接在不同位置的網格上回歸出目標的位置和類別資訊呢?上面是YOLO的網路結構圖,前邊的網路結構跟GoogLeNet的模型比較類似,主要的是最後兩層的結構,卷積層之後接了一個4096維的全連線層,然後後邊又全連線到一個7*7*30維的張量上。實際上這7*7就是劃分的網格數,現在要在每個網格上預測目標兩個可能的位置以及這個位置的目標置信度和類別,也就是每個網格預測兩個目標,每個目標的資訊有4維座標資訊(中心點座標+長寬),1個是目標的置信度,還有類別數20(VOC上20個類別),總共就是(4+1)*2+20
= 30維的向量。這樣可以利用前邊4096維的全圖特徵直接在每個網格上回歸出目標檢測需要的資訊(邊框資訊加類別)。
總結: YOLO將目標檢測任務轉換成一個迴歸問題,大大加快了檢測的速度,使得YOLO可以每秒處理45張影象。而且由於每個網路預測目標視窗時使用的是全圖資訊,使得false positive比例大幅降低(充分的上下文資訊)。但是YOLO也存在問題:沒有了Region Proposal機制,只使用7*7的網格迴歸會使得目標不能非常精準的定位,這也導致了YOLO的檢測精度並不是很高。
3.4.2 SSD(單次檢測)
SSD: Single Shot MultiBox Detector 上面分析了YOLO存在的問題,使用整圖特徵在7*7的粗糙網格內迴歸對目標的定位並不是很精準。那是不是可以結合Region Proposal的思想實現精準一些的定位?SSD結合YOLO的迴歸思想以及Faster R-CNN的anchor機制做到了這點。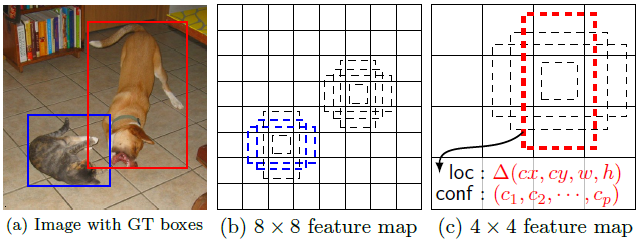 上圖是SSD的一個框架圖,首先SSD獲取目標位置和類別的方法跟YOLO一樣,都是使用迴歸,但是YOLO預測某個位置使用的是全圖的特徵,SSD預測某個位置使用的是這個位置周圍的特徵(感覺更合理一些)。那麼如何建立某個位置和其特徵的對應關係呢?可能你已經想到了,使用Faster R-CNN的anchor機制。如SSD的框架圖所示,假如某一層特徵圖(圖b)大小是8*8,那麼就使用3*3的滑窗提取每個位置的特徵,然後這個特徵迴歸得到目標的座標資訊和類別資訊(圖c)。
不同於Faster R-CNN,這個anchor是在多個feature map上,這樣可以利用多層的特徵並且自然的達到多尺度(不同層的feature map 3*3滑窗感受野不同)。
小結:
SSD結合了YOLO中的迴歸思想和Faster R-CNN中的anchor機制,使用全圖各個位置的多尺度區域特徵進行迴歸,既保持了YOLO速度快的特性,也保證了視窗預測的跟Faster R-CNN一樣比較精準。SSD在VOC2007上mAP可以達到72.1%,速度在GPU上達到58幀每秒。
上圖是SSD的一個框架圖,首先SSD獲取目標位置和類別的方法跟YOLO一樣,都是使用迴歸,但是YOLO預測某個位置使用的是全圖的特徵,SSD預測某個位置使用的是這個位置周圍的特徵(感覺更合理一些)。那麼如何建立某個位置和其特徵的對應關係呢?可能你已經想到了,使用Faster R-CNN的anchor機制。如SSD的框架圖所示,假如某一層特徵圖(圖b)大小是8*8,那麼就使用3*3的滑窗提取每個位置的特徵,然後這個特徵迴歸得到目標的座標資訊和類別資訊(圖c)。
不同於Faster R-CNN,這個anchor是在多個feature map上,這樣可以利用多層的特徵並且自然的達到多尺度(不同層的feature map 3*3滑窗感受野不同)。
小結:
SSD結合了YOLO中的迴歸思想和Faster R-CNN中的anchor機制,使用全圖各個位置的多尺度區域特徵進行迴歸,既保持了YOLO速度快的特性,也保證了視窗預測的跟Faster R-CNN一樣比較精準。SSD在VOC2007上mAP可以達到72.1%,速度在GPU上達到58幀每秒。
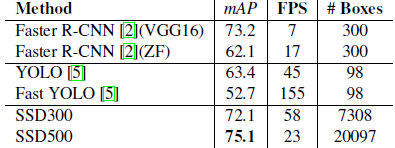
總結:YOLO的提出給目標檢測一個新的思路,SSD的效能則讓我們看到了目標檢測在實際應用中真正的可能性。
3.5 基於殘差(Residual)方法的深度學習目標檢測演算法
3.5.1 深度殘差網路(Deep Residual Networks)
它使用殘差學習的這一思想使得學習更深的網路成為可能,從而學習到更好的表達。 層數越多的神經網路越難以訓練。當層數超過一定數量後,傳統的深度網路就會因優化問題而出現欠擬合(underfitting)的情況。殘差學習框架大幅降低訓練更深層網路的難度,也使準確率得到顯著提升。在 ImageNet 和 COCO 2015 競賽中,共有 152 層的深度殘差網路 ResNet 在影象分類、目標檢測和語義分割各個分項都取得最好成績,相關論文更是連續兩次獲得 CVPR 最佳論文。 最新研究發現,當殘差網路將身份對映作為 skip connection 並實現 inter-block activation,正向和反向訊號能夠直接從一個區塊傳播到另一個區塊,這樣就達到了 1001 層的殘差網路。由此可見,神經網路的深度這一非常重要的因素,還有很大的提升空間。1)深度譜
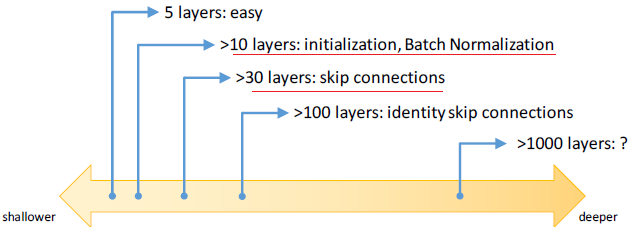
2)為使用網路層數更多,通常採用的方法有:初始化演算法,BN方法 3)是否簡單堆疊的網路層數越多,訓練誤差和測試誤差就越小?答案正好相反 4)目前流行的深度神經網路結構大致可以分為三類: - 直線型(如AlexNet, VGGNet) - 區域性雙分支型(ResNet) - 區域性多分支型(GoogleNet) 很久以前人們就已經認識到更深的網路能夠產生更好的資料表達,但是如何訓練一個很深的網路卻一直是一個困擾人們的問題,這主要是由於梯度消失或爆炸以及尺度不均勻的初始化造成的。圍繞這一問題,人們提出了ReLU、Xavier、pReLU、batch normalization和path-SGD等一系列方法,但是本文作者卻發現即使有這些方法,神經網路的訓練仍然呈現了degradation的現象。所謂degradation現象,就是隨著網路深度的增加,網路的效能反而下降,而且這種效能的下降並不是由前面所說的問題造成的。
 4)深度殘差學習(Deep Residual Learning)的思想
假如目前有一個可以工作的很好的網路A,這時來了一個比它更深的網路B,只需要讓B的前一部分與A完全相同,後一部分只實現一個恆等對映(identity mapping),這樣B最起碼能獲得與A相同的效能,而不至於更差。深度殘差學習的思想也由此而產生,既然B後面的部分完成的是恆等對映,何不在訓練網路的時候加上這一先驗(在網路訓練過程中,加入先驗資訊指導非常重要,合理的先驗往往會取得非常好的效果),於是構造網路的時候加入了捷徑(shortcut)連線,即每層的輸出不是傳統神經網路中的輸入的對映,而是輸入的對映和輸入的疊加,如下圖中的"Residual
net"所示。
4)深度殘差學習(Deep Residual Learning)的思想
假如目前有一個可以工作的很好的網路A,這時來了一個比它更深的網路B,只需要讓B的前一部分與A完全相同,後一部分只實現一個恆等對映(identity mapping),這樣B最起碼能獲得與A相同的效能,而不至於更差。深度殘差學習的思想也由此而產生,既然B後面的部分完成的是恆等對映,何不在訓練網路的時候加上這一先驗(在網路訓練過程中,加入先驗資訊指導非常重要,合理的先驗往往會取得非常好的效果),於是構造網路的時候加入了捷徑(shortcut)連線,即每層的輸出不是傳統神經網路中的輸入的對映,而是輸入的對映和輸入的疊加,如下圖中的"Residual
net"所示。

在Residual net中: (1)identity:為恆等對映,此條路徑一直存在 (2)F(x):為需要學習的殘差函式(residual function):H(x)-x = F(x) 問題的重新表示或預處理會簡化問題的優化! 假設我們期望的網路層關係對映為 H(x), 我們讓 the stacked nonlinear layers 擬合另一個對映, F(x):= H(x)-x , 那麼原先的對映就是 F(x)+x。 這裡我們假設優化殘差對映F(x) 比優化原來的對映 H(x)容易。 這裡我們首先求取殘差對映 F(x):= H(x)-x,那麼原先的對映就是 F(x)+x。儘管這兩個對映應該都可以近似理論真值對映 the desired functions (as hypothesized),但是它倆的學習難度是不一樣的。 這種改寫啟發於"網路層數越多,訓練和測試誤差越大"效能退化問題違反直覺的現象。如果增加的層數可以構建為一個恆等對映(identity mappings),那麼增加層數後的網路訓練誤差應該不會增加,與沒增加之前相比較。效能退化問題暗示多個非線性網路層用於近似identity mappings 可能有困難。使用殘差學習改寫問題之後,如果identity mappings 是最優的,那麼優化問題變得很簡單,直接將多層非線性網路引數趨0。
實際中,identity mappings 不太可能是最優的,但是上述改寫問題可能幫助預處理問題。如果最優函式接近identity mappings,那麼優化將會變得容易些。 實驗證明該思路是對的。
F(x)+x 可以通過shortcut connections 來實現,如下圖所示:
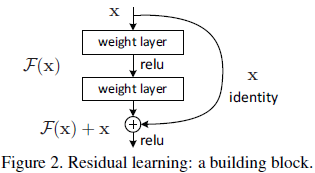 上圖中的shortcut connections執行一個簡單的恆等對映;既沒有引數,也沒有計算複雜度。
公式分析如下:
(1)需要學習的殘差對映
上圖中的shortcut connections執行一個簡單的恆等對映;既沒有引數,也沒有計算複雜度。
公式分析如下:
(1)需要學習的殘差對映
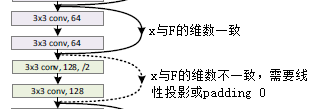
 (2)x和F的維數必須相同
如果x和F的維數不相同,則對x進行線性投影(linear projection)使用其與F的維數一致,公式如下:
(2)x和F的維數必須相同
如果x和F的維數不相同,則對x進行線性投影(linear projection)使用其與F的維數一致,公式如下:
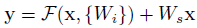 5)網路架構
5.1)普通網路(Plain Network)
設計原則:
(1)對於輸出特徵圖大小相同的層,它們的卷積擁有相同的filter個數
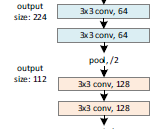
5)網路架構
5.1)普通網路(Plain Network)
設計原則:
(1)對於輸出特徵圖大小相同的層,它們的卷積擁有相同的filter個數(2)如果輸出的特徵圖大小減半,則filter個數乘以2,以確保每層的時間複雜度相同
 5.2)殘併網絡(Residual Network)
在遵循普通網路設計原則的基礎上,增加了shortcut connections。
5.2)殘併網絡(Residual Network)
在遵循普通網路設計原則的基礎上,增加了shortcut connections。
 6)恆等對映的重要性
6.1)平滑的正向傳播
6)恆等對映的重要性
6.1)平滑的正向傳播
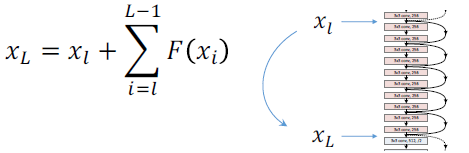 任意xl被直接正向傳播到xL,xL是xl與殘差相加的結果。
6.2)平滑的反向傳播
任意xl被直接正向傳播到xL,xL是xl與殘差相加的結果。
6.2)平滑的反向傳播
 7)保持最短路徑儘量平滑
7)保持最短路徑儘量平滑
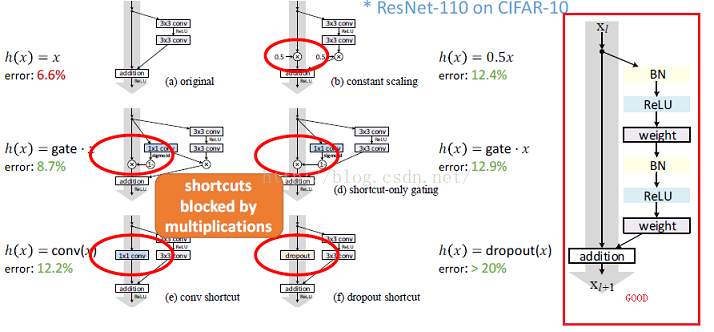 - 如果h(x)不是identity mapping,它將阻塞正向、反向傳播,從而導致誤差增加
- 如果h(x)不是identity mapping,它將阻塞正向、反向傳播,從而導致誤差增加
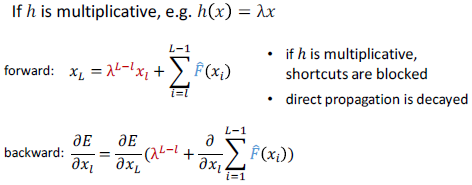 - BN可能阻塞傳播
- BN可能阻塞傳播
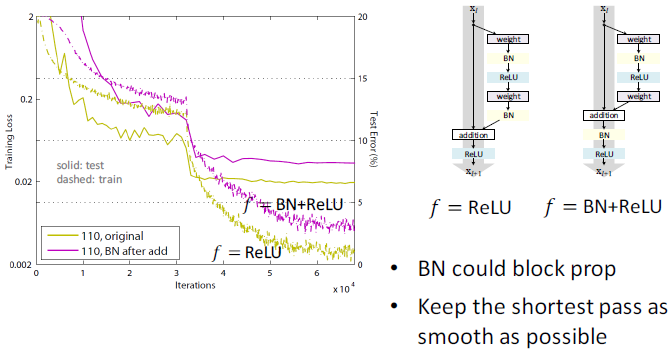 - ReLU可能阻塞傳播
- ReLU可能阻塞傳播

3.5 提高目標檢測方法
R-CNN系列目標檢測框架和YOLO目標檢測框架給了我們進行目標檢測的兩個基本框架。除此之外,研究人員基於這些框架從其他方面入手提出了一系列提高目標檢測效能的方法。 (1) 難分樣本挖掘(hard negative mining)相關推薦
CNN-目標檢測、定位、分割
1. 基本概念 1)CNN:Convolutional Neural Networks 2)FC:Fully Connected 3)IoU:Intersection over Union (IoU的值定義:Region Proposal與
cs231n學習筆記-CNN-目標檢測、定位、分割
1. 基本概念 1)CNN:Convolutional Neural Networks 2)FC:Fully Connected 3)IoU:Intersection over Union (IoU的值定義:Region Proposal與Grou
學習筆記-目標檢測、定位、識別(RCNN,Fast-RCNN, Faster-RCNN,Mask-RCNN,YOLO,SSD 系列)
0. 前言 說到深度學習的目標檢測,就要提到傳統的目標檢測方法。 傳統的目標檢測流程: 1)區域選擇(窮舉策略:採用滑動視窗,且設定不同的大小,不同的長寬比對影象進行遍歷,時間複雜度高) 2)特徵提取(SIFT、HOG等;形態多樣性、光照變化多樣性、背景多樣性使得特徵魯棒性差)
cs231n學習筆記 CNN 目標檢測 定位 分割
分享一下我老師大神的人工智慧教程!零基礎,通俗易懂!http://blog.csdn.net/jiangjunshow 也歡迎大家轉載本篇文章。分享知識,造福人民,實現我們中華民族偉大復興!
cs231n學習筆記-CNN-目標檢測 定位 分割
分享一下我老師大神的人工智慧教程!零基礎,通俗易懂!http://blog.csdn.net/jiangjunshow 也歡迎大家轉載本篇文章。分享知識,造福人民,實現我們中華民族偉大復興!
【計算機視覺必讀乾貨】影象分類、定位、檢測,語義分割和例項分割方法梳理
文章來源:新智元 作者:張皓 【導讀】本文作者來自南京大學計算機系機器學習與資料探勘所(LAMDA),本文直觀系統地梳理了深度學習在計算機視覺領域四大基本任務中的應用,包括影象分類、定位、檢測、語義分割和例項分割。 本文旨在介紹深度學習在計算機視覺領域四大基本任務中的應用,包括分類(圖
目標檢測之RCNN、Fast RCNN 、Faster RCNN技術演進與對比
三者的處理步驟 先上三者的處理步驟: RCNN: 1、提取1000-2000個(超引數)的候選框(採用selective search演算法); 2、將每個候選框中的影象調整到相同的size; 3、將調整size後的影象(數量與候選框個數相同)輸入CNN提取featu
深度學習中目標檢測演算法 RCNN、Fast RCNN、Faster RCNN 的基本思想
前言 影象分類,檢測及分割是計算機視覺領域的三大任務。即影象理解的三個層次: 分類(Classification),即是將影象結構化為某一類別的資訊,用事先確定好的類別(string)或例項ID來描述圖片。這一任務是最簡單、最基礎的影象理解任務,也是深度學習模型最先取得突
深度學習(二十)基於Overfeat的圖片分類、定位、檢測
作者:hjimce一、相關理論本篇博文主要講解來自2014年ICLR的經典圖片分類、定位物體檢測overfeat演算法:《OverFeat: Integrated Recognition, Locali
【目標檢測】【語義分割】—Mask-R-CNN詳解
一、mask rcnn簡介 論文連結:論文連結 論文程式碼:Facebook程式碼連結;Tensorflow版本程式碼連結; Keras and TensorFlow版本程式碼連結;MxNet版本程式碼連結 mask rcnn是基於faster rcnn架構提出的卷積網
第3天:CSS浮動、定位、表格、表單總結
特性 input 器) 用戶 style line ie瀏覽器 練習 doctype 今天學的是浮動、定位、表格、表單等內容,這些是CSS中最容易混淆的知識,有許多小技巧在寫代碼過程中需要註意。下面是主要知識點: 一、float浮動1、塊元素在一行顯示2、內聯元素支持寬高3
CSS - 文件流 and 佈局(浮動、流式、定位、相對、絕對、固定)
目錄 一、文件流(normal flow) 1、概念 2、BFC(Block formatting context 塊格式化上下文) - 2.1一切皆為框 - 2.2 無名塊框 3、BFC規則 二、浮動佈局 1
Android整合百度地圖-----顯示地圖、定位、長按顯示地址資訊
一、基礎部分 轉載請註明出處:https://blog.csdn.net/Hunter2916/article/details/82867205 1、下載百度地圖的SDK 下載地址:http://lbsyun.baidu.com/index.php?title=android-locsd
影象標註工具彙總目標檢測標註工具影象分割標註工具
對於監督學習演算法而言,資料決定了任務的上限,而演算法只是在不斷逼近這個上限。世界上最遙遠的距離就是我們用同一個模型,但是卻有不同的任務。但是資料標註是個耗時耗力的工作,下面介紹幾個影象標註工具: Labelme Labelme適用於影象分割任務的資料集製作: 它來自下面的專案:https:
python+selenium四:iframe檢視、定位、切換 python+selenium四:iframe檢視、定位、切換
python+selenium四:iframe檢視、定位、切換 1.檢視iframe 1.Top Window:可直接定位 2.iframe#i:說明此元素在iframe上
Faster R-CNN 目標檢測演算法詳細總結分析(two-stage)(深度學習)(NIPS 2015)
論文名稱:《 Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks 》 論文下載:https://papers.nips.cc/paper/5638-faster-r-cnn-t
Fast R-CNN 目標檢測演算法詳細總結分析(two-stage)(深度學習)(ICCV 2015)
論文名稱:《 Fast R-CNN 》 論文下載:https://arxiv.org/pdf/1504.08083.pdf 論文程式碼:https://github.com/rbgirshick/fast-rcnn 一、 網路結構:
R-CNN 目標檢測演算法詳細總結分析(two-stage)(深度學習)(CVPR 2014)
論文名稱:《 Rich feature hierarchies for accurate object detection and semantic segmentation 》 論文下載:https://arxiv.org/pdf/1311.2524.pdf 論文程式碼:ht
CSS學習總結:浮動、定位、父容器塌陷問題
怎麼說呢,從接觸前端起,到現在已經有三個月了,這麼長時間的學習呢,我的水平依然一般,前幾天參加了IFE2017,下面總結一下對CSS中浮動、定位、分列布局、父容器塌陷問題的一些心得。 首先,浮動和定位是CSS中佈局的基礎,通過浮動和定位,可以實現對每一個盒模型精確到畫素級別的控制,可見其
04 在地圖上新增主頁、定位、鷹眼圖和比例尺控制元件
在上一篇文章中我們學習瞭如何建立一個簡單的地圖,那接下來,我們學習如何給建立好的地圖上新增一些基本的空間,最終效果如下圖所示: 由上圖可以看出,我們在地圖上添加了主頁、定位、鷹眼圖以及比例尺控制元件,下面將詳細介紹如何新增: 1 主頁按鈕的新增 新增主頁按鈕的前提是