
Spark原理總結
一、Spark 是什麼
Spark是UC Berkeley AMP lab所開源的類Hadoop MapReduce的通用分散式平行計算框架。Spark擁有hadoop MapReduce所具有的優點,但和MapReduce 的最大不同之處在於Spark是基於記憶體的迭代式計算——Spark的Job處理的中間輸出結果可以儲存在記憶體中,從而不再需要讀寫HDFS,除此之外,一個MapReduce 在計算過程中只有map 和reduce 兩個階段,處理之後就結束了,而在Spark的計算模型中,可以分為n階段,因為它記憶體迭代式的,我們在處理完一個階段以後,可以繼續往下處理很多個階段,而不只是兩個階段。
因此Spark能更好地適用於資料探勘與機器學習等需要迭代的MapReduce的演算法。其不僅實現了MapReduce的運算元map 函式和reduce函式及計算模型,還提供更為豐富的運算元,如filter、join、groupByKey等。是一個用來實現快速而同用的叢集計算的平臺。
二、spark 的框架設計
spark 框架如圖1 所示 :
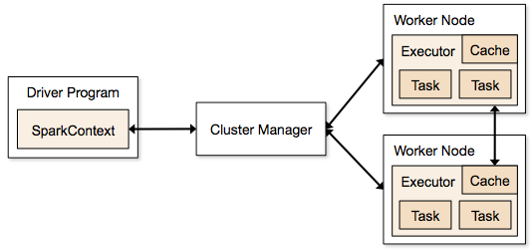
從圖1中可以看到,所有的Spark應用程式都離不開SparkContext和Executor兩部分,Executor負責執行任務,執行Executor的機器稱為Worker節點,SparkContext由使用者程式啟動,通過資源排程模組和Executor通訊。SparkContext和Executor這兩部分的核心程式碼實現在各種執行模式中都是公用的,在它們之上,根據執行部署模式的不同,包裝了不同調度模組以及相關的適配程式碼。
具體來說,以SparkContext為程式執行的總入口,在SparkContext的初始化過程中,Spark會分別建立DAGScheduler作業排程和TaskScheduler任務調度兩級排程模組。其中作業排程模組是基於任務階段的高層排程模組,它為每個Spark作業計算具有依賴關係的多個排程階段(通常根據shuffle來劃分),然後為每個階段構建出一組具體的任務(通常會考慮資料的本地性等),然後以TaskSets(任務組)的形式提交給任務排程模組來具體執行。而任務排程模組則負責具體啟動任務、監控和彙報任務執行情況。
備註:在上述框架圖中的一些術語解釋如下:
Cluster Manager:
1. Standalone, Spark原生的資源管理;
2. Apache Mesos, 和Hadoop Mapreduce相容性良好的資源排程框架;
Application: 使用者編寫的應用應用程式。
Driver: Application中執行main函式並建立的SparkContext, 建立SparkContext的目的是和叢集的ClusterManager通訊,進行資源的申請、任務的分配和監控等。所以,可以用SparkContext代表Driver
Worker:叢集中可以執行Application程式碼的節點。
Executor: 某個Application在Worker上面的一個程序,該程序負責執行某些Task,並負責把資料存在記憶體或者磁碟上。每個Application都各自有一批屬於自己的Executor。
Task:被送到Executor執行的工作單元,和Hadoop MapReduce中的MapTask和ReduceTask一樣,是執行Application的基本單位。多個Task組成一個Stage,而Task的排程和管理由TaskScheduler負責。
Job:包含多個Task組成的平行計算,往往由Spark Action觸發產生。一個Application可以產生多個Job。
Stage:每個Job的Task被拆分成很多組Task, 作為一個TaskSet,命名為Stage。Stage的排程和劃分由DAGScheduler負責。Stage又分為Shuffle Map Stage和Result Stage兩種。Stage的邊界就在發生Shuffle的地方。
**RDD:**Spark的基本資料操作抽象,可以通過一系列運算元進行操作。RDD是Spark最核心的東西,可以被分割槽、被序列化、不可變、有容錯機制,並且能並行操作的資料集合。儲存級別可以是記憶體,也可以是磁碟。
DAGScheduler:根據Job構建基於Stage的DAG(有向無環任務圖),並提交Stage給TaskScheduler
TaskScheduler:將Stage提交給Worker(叢集)執行,每個Executor執行什麼在此分配。
**共享變數:**Spark Application在整個執行過程中,可能需要一些變數在每個Task中都使用,共享變數用於實現該目的。Spark有兩種共享變數:一種快取到各個節點的廣播變數;一種只支援加法操作,實現求和的累加變數。
寬依賴:或稱為ShuffleDependency, 寬依賴需要計算好所有父RDD對應分割槽的資料,然後在節點之間進行Shuffle。
窄依賴:或稱為NarrowDependency,指某個RDD,其分割槽partition x最多被其子RDD的一個分割槽partion y依賴。窄依賴都是Map任務,不需要發生shuffle。因此,窄依賴的Task一般都會被合成在一起,構成一個Stage。
三、spark 的工作流程原理
spark 的工作原理圖 如圖2 所示
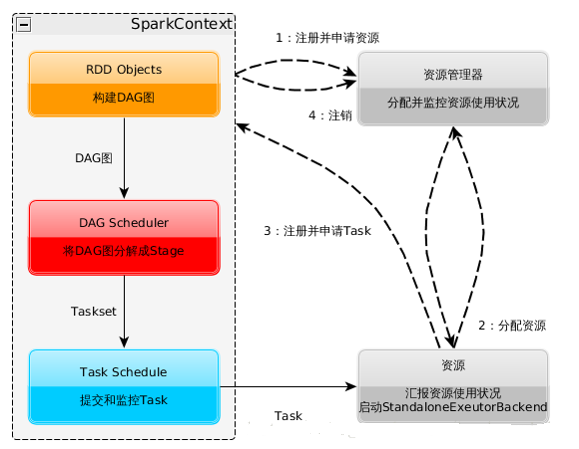
根據圖2 可以把spark的工作流程描述如下:
a. 構建Spark Application的執行環境(啟動SparkContext)
b. SparkContext在初始化過程中分別建立DAGScheduler作業排程和TaskScheduler任務排程
兩級排程模組
c. SparkContext向資源管理器(可以是Standalone、Mesos、Yarn)申請執行Executor資源;
d. 由資源管理器分配資源並啟動StandaloneExecutorBackend,executor,之後向SparkContext申請Task;
e. DAGScheduler將job 劃分為多個stage,並將Stage提交給TaskScheduler;
g. Task在Executor上執行,執行完畢釋放所有資源。
詳解:
在我們使用spark-submit 提交了我們的應用程式的時候,提交spark的運用機器會通過反射的方式,建立和構造一個Driver程序,Driver程序執行Application程式,根據sparkConf中的配置初始SparkContext,在SparkContext 初始化的過程中會啟動DAGScheduler和taskScheduler兩個排程模組,同時taskSheduler通過後臺程序,向Master註冊Application,Master接到到了Application的註冊請求之後,會使用自己的資源排程演算法,在spark叢集的worker上,通知worker為application啟動多個Executor。之後Executor會向taskScheduler反向註冊。Driver完成SparkContext初始化,並繼續執行application程式,當執行到Action時,就會建立Job。並且由DAGScheduler將Job劃分多個Stage,每個Stage
由TaskSet 組成,並將TaskSet提交給taskScheduler,taskScheduler把TaskSet中的task依次提交給Executor,Executor在接收到task之後,會使用taskRunner來封裝task(TaskRuner主要將我們編寫程式,也就是我們編寫的運算元和函式進行拷貝和反序列化),然後,從Executor的執行緒池中取出一個執行緒來執行task。就這樣Spark的每個Stage被作為TaskSet提交給Executor執行,每個Task對應一個RDD的partition,執行我們的定義的運算元和函式。直到所有操作執行完為止。
四、spark 的核心程式設計操作
在我們的實際開發中需要我們處理的核心程式設計如下:
1、初始定義的RDD,即你要定義的RDD來自於哪裡,比如是HDFS,還是Linux系統中的本地檔案或者是集合
2、定義對RDD 的計算操作,在spark 中通常稱為運算元。比如:map 、groupByKey 、reduce 等
3、對步驟2中產生的新RDD 進行迴圈往復定義其它的運算元操作
4、將最終獲得的資料集儲存起來。比如儲存在資料庫或者HDFS上
五、spark 的核心RDD
1、RDD的定義
RDD(Resilient Distributed Datasets) 彈性分散式資料集。 其詳細描述如下:
a、RDD在抽象上來說是一種元素集合,包含了資料。它是被分割槽的,分為多個分割槽,每個分割槽分佈在叢集中的不同節點上,從而讓RDD中的資料可以被並行操作。(分散式資料集)
b、RDD的資料預設情況下存放在記憶體中的,但是在記憶體資源不足時,Spark會自動將RDD資料寫入磁碟。比如每個節點最多放5萬資料,結果你每個partition是10萬資料。那麼就會把partition中的部分資料寫入磁碟上,進行儲存。(彈性)
2、RDD操作特性
RDD將操作分為兩類:transformation與action。無論執行了多少次transformation操作,RDD都不會真正執行運算,只有當action操作被執行時,運算才會觸發。而在RDD的內部實現機制中,底層介面則是基於迭代器的,從而使得資料訪問變得更高效,也避免了大量中間結果對記憶體的消耗。
3、RDD的容錯特性
RDD最重要的特性就是,提供了容錯性,可以自動從節點失敗中恢復過來。即如果某個節點上的RDD partition,因為節點故障,導致資料丟了,那麼RDD會自動通過自己的資料來源重新計算該partition。這一切對使用者是透明的。