
STL原始碼分析(總結)
STL六大元件
- 容器(containers):是一種class template,裡面包含各種資料結構。
- 演算法(algorithms):是一種function template,裡面包含各種演算法。
- 迭代器(iterators):是所謂的泛型指標,每個容器都有自己的專屬的迭代器,知道如何遍歷自己的元素。
- 仿函式(functors):是一種過載了operator()的class或class template,可作為演算法的某種策略。
- 配接器(adapters):是一種用來修飾容器或仿函式或迭代器介面的東西。
- 配置器(allocators):是一個實現了動態空間配置,空間管理,空間釋放的class template,負責空間配置與管理。
空間配置器
構造
- 分配新的空間
- 在新空間上構造物件
template <class T>
inline T* _allocate(...) {
...
T* tmp = (T*)(::operate new((size_t)(size * sizeof(T))));
...
}template <class T1, class T2>
inline void _construct(T1* p, const T2& value) {
new(p) T1(value); //placement new. operator new
(1)只分配所要求的空間,不呼叫相關物件的建構函式。當無法滿足所要求分配的空間時,則
->如果有new_handler,則呼叫new_handler,否則
->如果沒要求不丟擲異常(以nothrow引數表達),則執行bad_alloc異常,否則
->返回0
(2)可以被過載
(3)過載時,返回型別必須宣告為void*
(4)過載時,第一個引數型別必須為表達要求分配空間的大小(位元組),型別為size_t
(5)過載時,可以帶其它引數
Placement new
placement new 是過載operator new 的一個標準、全域性的版本,它不能夠被自定義的版本代替(不像普通版本的operator new和operator delete能夠被替換)。
物件的分配
在已分配的快取區呼叫placement new來構造一個物件。
Task *ptask = new (buf) Task
SGI中的空間配置與釋放(std::alloc)
SGI設計哲學:
- 向system heap要求空間
- 考慮多執行緒狀態
- 考慮記憶體不足時的應變措施
- 考慮過多“小型區塊”可能造成的碎片問題
記憶體分配中使用::operator new()與::operator delete()分配與釋放相當於molloc()與free().
考慮第四點設計了雙層配置器,第一層直接呼叫malloc()和free().
配置記憶體小於128bytes時,使用第二級配置器:
使用16個自由連結串列負責16種小型區塊的次級配置能力。如果記憶體不足轉一級配置器。
8 16 24 32 40 48 56 64 72 80 88 96 104 112 120 128
迭代器
迭代器類似於一種智慧指標,比較重要的行為有內容提領和成員訪問。
迭代器相應型別
為了讓迭代器適應不同種類的容器即泛化,需利用function template的引數推導機制推導型別。
偏特化:如果class template擁有一個以上的template引數,我們可以針對其中某個template引數進行特化工作(我們可以在泛化設計中提供一個特化版本)。
trans程式設計技法
宣告內嵌型別推導函式返回值:
template <class T>
struct MyIter {
typedef T value_type; //內嵌型別
T* ptr;
MyIter(T* p=0) : ptr(p) {}
T& operator*() const { return *ptr; }
//...
}
template <class I>
typename I::value_type //這一整行是func的返回值型別
func(I ite) {
return *ite;
}
MyIter<int> ite(new int(8));
cout << func(ite);萃取型別:
template <class I>
struct iterator_traits {
typedef typename I::value_type value_type;
}
template <class I>
typename iterator_traits<I>::value_type //函式返回型別
func(I ite) {
return *ite;
}
//萃取原生指標,偏特化版本
template <class T>
struct iterator_traits<T*> {
typedef T value_type;
};STL根據經驗,定義了迭代器最常用到的五種型別:value_type、difference_type、pointer、reference、iterator_category,任何開發者如果想將自己開發的容器與STL結合在一起,就一定要為自己開發的容器的迭代器定義這五種型別,這樣都可以通過統一介面iterator_traits萃取出相應的型別,下面列出STL中iterator_traits的完整定義:
tempalte<typename I>
struct iterator_traits
{
typedef typename I::iterator_category iterator_category;
typedef typename I::value_type value_type;
typedef typeanme I:difference_type difference_type;
typedef typename I::pointer pointer;
typedef typename I::reference reference;
};重點提一下iterator_category:
根據移動特性與施行操作,迭代器被分為五類:
- Input Iterator:只讀
- Output Iterator:只寫
- Forward Iterator:允許“寫入型”演算法(例如replace())在此種迭代器所形成的區間上進行讀寫操作。
- Bidirectional Iterator:可雙向移動。
- Random Access Iterator:前四種迭代器都只供應一部分指標算術能力(前三種支援 operator++,第四種再加上operator–),第五種則涵蓋所有指標算術能力,包括p+n, p-n, p[n], p1-p2, p1
序列式容器

元素可序但未必有序
vector
vector底層為動態陣列,分配策略為:
- 如果vector原大小為0,則配置1,也即一個元素的大小。
- 如果原大小不為0,則配置原大小的兩倍。
當然,vector的每種實現都可以自由地選擇自己的記憶體分配策略,分配多少記憶體取決於其實現方式,不同的庫採用不同的分配策略。
當以兩倍空間增長時之前分配的記憶體空間不可能被使用,這樣對於快取並不友好。
相關連線:https://www.zhihu.com/question/36538542
vector的迭代器
使用vector迭代器時要時刻注意vector是否發生了擴容,一旦擴容引起了空間重新配置,指向原vector的所有迭代器都將失效。
vector維護的是一個連續線性空間,與陣列array一樣,所以無論其元素型別為何,普通指標都可以作為vector的迭代器而滿足所有必要的條件。vector所需要的迭代器操作,包括operator*,operator->,operator++,operator–,operator+=,operator-=等,普通指標都具有。
vector提供了Random Access Iterators。
vector的資料結構
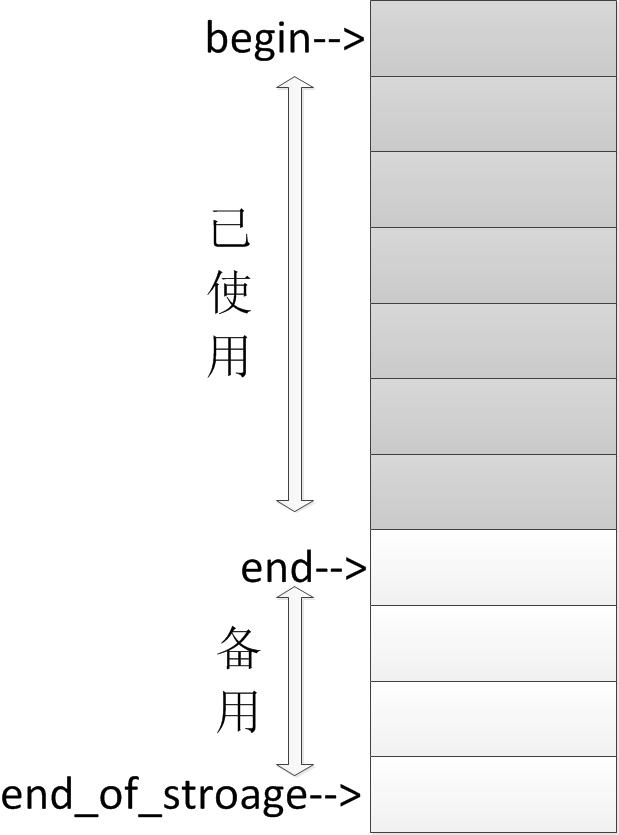
vector底層為連續線性空間
list
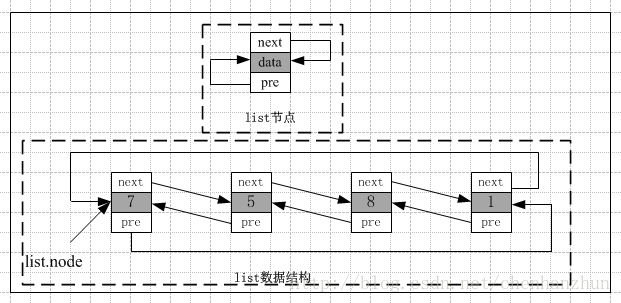
list容器完成的功能實際上和資料結構中的雙向連結串列是極其相似的,list中的資料元素是通過連結串列指標串連成邏輯意義上的線性表
對於迭代器,只能通過“++”或“–”操作將迭代器移動到後繼/前驅節點元素處,而不能對迭代器進行+n或-n的操作。增加任何元素都不會使迭代器失效。刪除元素時,除了指向當前被刪除元素的迭代器外,其它迭代器都不會失效。
deque
**deque是一種雙向開口的線性空間。**deque容器類與vector類似,支援隨機訪問和快速插入刪除,它在容器中某一位置上的操作所花費的是線性時間。雖然vector也支援從頭端插入元素,不過效率奇差,deque與vector最大差異:
- deque允許常數時間內對起頭端進行元素的插入或移除操作。
- deque沒有所謂的容量觀念,因為它是動態的以分段連續空間組合而成,隨時可以增加一段新的空間並拼接起來。
一旦有必要在deque的前段或尾端增加新空間,便配置一段定量連續空間,串在整個deque的頭端或尾端。迭代器較為複雜,操作複雜度大。
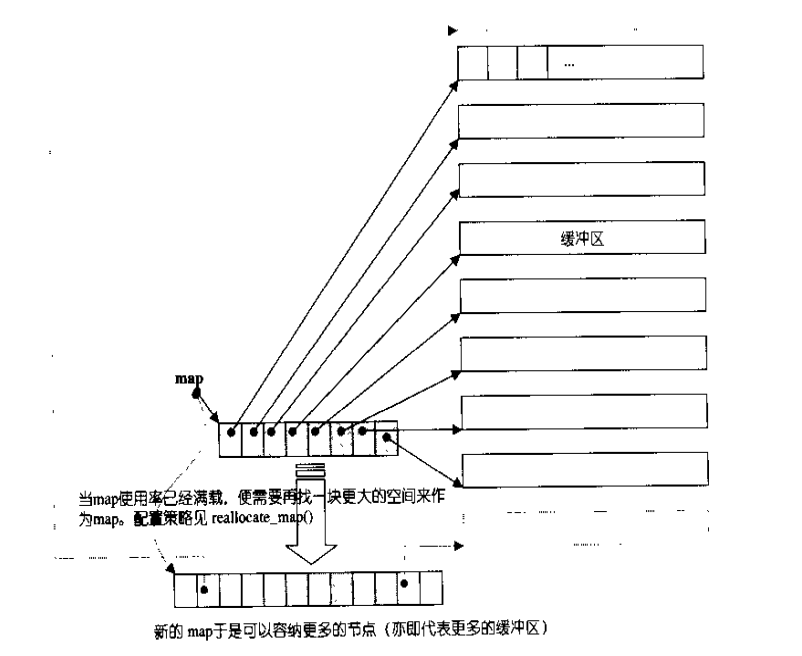
deque是由一塊所謂的map作為主控,map是一段連續的空間,其中每個元素指向另一段連續的空間,稱為緩衝區。一旦map空間不足,需配備一塊更大的map。
deque迭代器
雖然deque也提供Random Access Iterators,不過其迭代器比較特殊。

迭代器失效:
插入操作:
1、在隊前或隊後插入元素時(push_back(),push_front()),由於可能緩衝區的空間不夠,需要增加map中控器,而中控器的個數也不夠,所以新開闢更大的空間來容納中控器,所以可能會使迭代器失效;但指標、引用仍有效,因為緩衝區已有的元素沒有重新分配記憶體。
2、在佇列其他位置插入元素時,由於會造成緩衝區的一些元素的移動(原始碼中執行copy()來移動資料),所以肯定會造成迭代器的失效;並且指標、引用都會失效。
刪除操作:
1、刪除隊頭或隊尾的元素時,由於只是對當前的元素進行操作,所以其他元素的迭代器不會受到影響,所以一定不會失效,而且指標和引用也都不會失效;
2、刪除其他位置的元素時,也會造成元素的移動,所以其他元素的迭代器、指標和引用都會失效。
stack
是一種配接器,將介面改變符合先進後出規則,沒有迭代器。
以deque為底層容器,以list為底層容器。
queue
是一種配接器,將介面改變符合先進先出規則,沒有迭代器。
以deque為底層容器,以list為底層容器。
priority_queue
是一種配接器,沒有迭代器,是以二叉堆為底層資料結構來實現的,所以先簡單介紹heap。
heap
堆的實現通過構造二叉堆(binary heap),實為二叉樹的一種;由於其應用的普遍性,當不加限定時,均指該資料結構的這種實現。這種資料結構具有以下性質。
- 任意節點小於(或大於)它的所有後裔,最小元(或最大元)在堆的根上(堆序性)。
- 堆總是一棵完全樹。即除了最底層,其他層的節點都被元素填滿,且最底層儘可能地從左到右填入。
將根節點最大的堆叫做最大堆或大根堆,根節點最小的堆叫做最小堆或小根堆,STL供應的是最大堆。
在SGI STL中用array來實現堆,則當某個節點位於i處時,其左子節點和右子節點分別為2i,2i+1,父節點為i/2.
priority_queue 優先順序佇列是一個擁有權值概念的單向佇列queue,在這個佇列中,所有元素是按優先順序排列的(也可以認為queue是個按進入佇列的先後做為優先順序的優先順序佇列——先進入佇列的元素優先權要高於後進入佇列的元素)。
priority_queue預設使用vector作為底層容器,預設會在構造時通過max-heap建堆。
關聯式容器
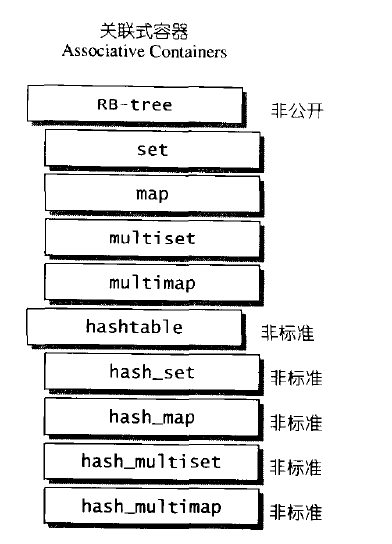
標準的STL關聯式容器分為set(集合)/map(對映表)兩大類,以及這兩大類的衍生體multiset(多鍵集合)和 multimap(多鍵對映表)。這些容器的底層機制均以RB-tree(紅黑樹)完成。RB-tree也是一個獨立容器,但並不開放給外界使用。
此外,SGI STL 還提供了一個不在標準規格之列的關聯式容器:hash table (散列表),以及以此hash table 為底層機制而完成的hash_set(雜湊集合)、hash_map(雜湊對映表)、hash_multiset(雜湊多鍵集合)、hash_multimap(雜湊多鍵對映表)。
根據C++ 11標準的推薦,用unordered_map代替hash_map。
所謂的關聯式容器,觀念上類似關聯式資料庫:每筆資料(每個元素)都有一個鍵值(key)和一個實值(value)。當元素被插入到關聯式容器中時,容器內部結構(可能是RB-tree ,也可能是hash-table)便依照其鍵值大小,以某種特定規則將這個元素放置於適當位置。關聯式容器沒有所謂的頭尾(只有最大元素和最小元素),所以不會有所謂push_back()/push_front()/pop_back()/pop_front()/begin()/end() 這樣的操作行為。
一般而言,關聯式容器的內部結構是一個balanced binary tree(平衡二叉樹),以便獲得良好的搜尋效率。balanced binary tree 有許多種型別,包括AVL-tree、RB-tree、AA-tree ,其中最被廣泛運用於STL的是RB-tree(紅黑樹)。
紅黑樹
演算法導論對R-B Tree的介紹:
紅黑樹,一種二叉查詢樹,但在每個結點上增加一個儲存位表示結點的顏色,可以是Red或Black。
通過對任何一條從根到葉子的路徑上各個結點著色方式的限制,紅黑樹確保沒有一條路徑會比其他路徑長出倆倍,因而是接近平衡的。
紅黑樹的5個性質:
- 每個結點要麼是紅的要麼是黑的。
- 根結點是黑的。
- 每個葉結點(葉結點即指樹尾端NIL指標或NULL結點)都是黑的。
- 如果一個結點是紅的,那麼它的兩個兒子都是黑的。
- 對於任意結點而言,其到葉結點樹尾端NIL指標的每條路徑都包含相同數目的黑結點。
紅黑樹能夠以O(log2 n) 的時間複雜度進行搜尋、插入、刪除操作。此外,由於它的設計,任何不平衡都會在三次旋轉之內解決。當然,還有一些更好的,但實現起來更復雜的資料結構,能夠做到一步旋轉之內達到平衡,但紅黑樹能夠給我們一個比較“便宜”的解決方案。紅黑樹的演算法時間複雜度和AVL相同,但統計效能比AVL樹更高。
紅黑樹節點和迭代器:
紅黑樹節點和迭代器的設計和slist原理一樣,將結構和資料分離.原理如下:
struct __rb_tree_node_base
{
typedef __rb_tree_color_type color_type;
typedef __rb_tree_node_base* base_ptr;
color_type color; // 紅黑樹的顏色
base_ptr parent; // 父節點
base_ptr left; // 指左節點
base_ptr right; // 指向右節點
}
template <class Value>
struct __rb_tree_node : public __rb_tree_node_base
{
typedef __rb_tree_node<Value>* link_type;
Value value_field; // 儲存資料
};紅黑樹的基礎迭代器為struct __rb_tree_base_iterator,主要成員就是一個__rb_tree_node_base節點,指向樹中某個節點,作為迭代器與樹的連線關係,還有兩個方法,用於將當前迭代器指向前一個節點decrement()和下一個節點increment().下面看下正式迭代器的原始碼:
template <class Value, class Ref, class Ptr>
struct __rb_tree_iterator : public __rb_tree_base_iterator
{
typedef Value value_type;
typedef Ref reference;
typedef Ptr pointer;
typedef __rb_tree_iterator<Value, Value&, Value*> iterator;
typedef __rb_tree_iterator<Value, const Value&, const Value*> const_iterator;
typedef __rb_tree_iterator<Value, Ref, Ptr> self;
typedef __rb_tree_node<Value>* link_type;
__rb_tree_iterator() {}//迭代器預設建構函式
__rb_tree_iterator(link_type x) { node = x; }//由一個節點來初始化迭代器
__rb_tree_iterator(const iterator& it) { node = it.node; }//迭代器複製建構函式
//迭代器解引用,即返回這個節點儲存的數值
reference operator*() const { return link_type(node)->value_field; }
#ifndef __SGI_STL_NO_ARROW_OPERATOR
//返回這個節點數值值域的指標
pointer operator->() const { return &(operator*()); }
#endif /* __SGI_STL_NO_ARROW_OPERATOR */
//迭代器++運算
self& operator++() { increment(); return *this; }
self operator++(int) {
self tmp = *this;
increment();
return tmp;
}
//迭代器--運算
self& operator--() { decrement(); return *this; }
self operator--(int) {
self tmp = *this;
decrement();
return tmp;
}
};
inline bool operator==(const __rb_tree_base_iterator& x,
const __rb_tree_base_iterator& y) {
return x.node == y.node;
// 兩個迭代器相等,指這兩個迭代器指向的節點相等
}
inline bool operator!=(const __rb_tree_base_iterator& x,
const __rb_tree_base_iterator& y) {
return x.node != y.node;
// 兩個節點不相等,指這兩個迭代器指向的節點不等
}迭代器的解引用運算,返回的是這個節點的值域.所以對於set來說,返回的就是set儲存的值,對於map來說,返回的就是pair
size_type node_count; // 記錄樹的大小(節點的個數)
link_type header;
Compare key_compare; // 節點間的比較器,是仿函式對於header,其實相當與連結串列中的頭節點,不儲存資料,可用於紅黑樹的入口.header的設計可以說的STL紅黑樹設計的一個亮點,header和root互為父節點,header的左節點指向最小的值,header的右節點指向最大的值,所以header也可以作為end()迭代器指向的值.圖示如下:

紅黑樹的操作就不再贅述,演算法書裡都有介紹。
map&set
map底層用的是紅黑樹,所以map只是在紅黑樹上加了一層封裝,set同理。
multiset與multimap與上述最大的不同在於允許重複的鍵值在紅黑樹上,插入操作採用的是底層RB-Tree的insert_equal()而非insert_unique()。
迭代器失效:如果迭代器所指向的元素被刪除,則該迭代器失效。其它任何增加、刪除元素的操作都不會使迭代器失效。
hashtable
hashtable即所謂的散列表,對於衝突的解決方法,stl採用開鏈的方法來解決衝突。STL的做法是在bucket中維護一個list,然後key對應的值插入list。至於buckets聚合體,stl採用vector作為底層容器。
hash_table節點的定義:
template <class _Val>
struct _Hashtable_node
{
_Hashtable_node* _M_next;
_Val _M_val;
};
hashtable的迭代器:
struct _Hashtable_iterator {
typedef _Hashtable_node<_Val> _Node;
typedef forward_iterator_tag iterator_category;
_Node* _M_cur;
_Hashtable* _M_ht;
iterator& operator++();
iterator operator++(int);
};hashtable的迭代器型別為ForwardIterator,所以只支援operator++操作。
hashtable關鍵實現:
對於散列表大小的選取,CLRS上面也提到了m常常選擇與2的冪不太接近的質數。在這種情況下,取一個素數總是個不壞的選擇。
SGI STL提供了28個素數最為備選方案,__stl_next_prime可以選出一個最接近n且比n要大的素數。
enum { __stl_num_primes = 28 };
static const unsigned long __stl_prime_list[__stl_num_primes] =
{
53ul, 97ul, 193ul, 389ul, 769ul,
1543ul, 3079ul, 6151ul, 12289ul, 24593ul,
49157ul, 98317ul, 196613ul, 393241ul, 786433ul,
1572869ul, 3145739ul, 6291469ul, 12582917ul, 25165843ul,
50331653ul, 100663319ul, 201326611ul, 402653189ul, 805306457ul,
1610612741ul, 3221225473ul, 4294967291ul
};
inline unsigned long __stl_next_prime(unsigned long __n)
{
const unsigned long* __first = __stl_prime_list;
const unsigned long* __last = __stl_prime_list + (int)__stl_num_primes;
const unsigned long* pos = lower_bound(__first, __last, __n);
return pos == __last ? *(__last - 1) : *pos;
}
size_type max_bucket_count() const
{
return __stl_prime_list[(int)__stl_num_primes - 1];
}hash_table的模板引數
template <class _Val, class _Key, class _HashFcn,
class _ExtractKey, class _EqualKey, class _Alloc>其中
// 重新調整表格大小
template <class _Val, class _Key, class _HF, class _Ex, class _Eq, class _All>
void hashtable<_Val,_Key,_HF,_Ex,_Eq,_All>
::resize(size_type __num_elements_hint)
{
const size_type __old_n = _M_buckets.size();
// 超過原來表格的大小時才進行調整
if (__num_elements_hint > __old_n) {
// 新的表格大小
const size_type __n = _M_next_size(__num_elements_hint);
// 在邊界情況下可能無法調整(沒有更大的素數了)
if (__n > __old_n) {
vector<_Node*, _All> __tmp(__n, (_Node*)(0),
_M_buckets.get_allocator());
__STL_TRY {
// 填充新的表格
for (size_type __bucket = 0; __bucket < __old_n; ++__bucket) {
_Node* __first = _M_buckets[__bucket];
while (__first) {
size_type __new_bucket = _M_bkt_num(__first->_M_val, __n);
_M_buckets[__bucket] = __first->_M_next;
__first->_M_next = __tmp[__new_bucket];
__tmp[__new_bucket] = __first;
__first = _M_buckets[__bucket];
}
}
// 通過swap交換
_M_buckets.swap(__tmp);
}
# ifdef __STL_USE_EXCEPTIONS
// 異常處理
catch(...) {
for (size_type __bucket = 0; __bucket < __tmp.size(); ++__bucket) {
while (__tmp[__bucket]) {
_Node* __next = __tmp[__bucket]->_M_next;
_M_delete_node(__tmp[__bucket]);
__tmp[__bucket] = __next;
}
}
throw;
}
# endif /* __STL_USE_EXCEPTIONS */
}
}
}unordered_map
unordered_map是以hash_table為底層容器來實現的。
演算法
STL演算法部分主要由標頭檔案,,組成。要使用 STL中的演算法函式必須包含標頭檔案,對於數值演算法須包含,中則定義了一些模板類,用來宣告函式物件。
STL中演算法大致分為四類:
1. 非可變序列演算法:指不直接修改其所操作的容器內容的演算法。
2. 可變序列演算法:指可以修改它們所操作的容器內容的演算法。
3. 排序演算法:包括對序列進行排序和合並的演算法、搜尋演算法以及有序序列上的集合操作。
4. 數值演算法:對容器內容進行數值計算。
stl中大概有70個演算法,不再一一列舉。接下來介紹STL中最龐大的sort()排序演算法。
sort:
sort接受兩個RandomAccessIterators(隨機存取迭代器),然後將區間內的所有元素以漸增方式從小到大排列。第二個版本允許使用者指定一個仿函式作為比較的標準。
STL的sort()演算法,資料量大時採用Quick Sort,分段遞迴排序,一旦分段後的資料量小於某個門檻,為避免Quick Sort的遞迴呼叫帶來過大的額外負荷,就改用Insertion Sort。如果遞迴層次過深,還會改用Heap Sort。
Insertion Sort是《演算法導論》一開始就討論的演算法。它的基本原理是:將初始序列的第一個元素作為一個有序序列,然後將剩下的N-1個元素按關鍵字大小依次插入序列,並一直保持有序。這個演算法的複雜度為O(N^2),最好情況下時間複雜度為O(N)。在資料量很少時,尤其還是在序列“幾近排序但尚未完成”時,有著很不錯的效果。
Insertion Sort
// 預設以漸增方式排序
template <class RandomAccessIterator>
void __insertion_sort(RandomAccessIterator first,
RandomAccessIterator last)
{
if (first == last) return;
// --- insertion sort 外迴圈 ---
for (RandomAccessIterator i = first + 1; i != last; ++i)
__linear_insert(first, i, value_type(first));
// 以上,[first,i) 形成一個子區間
}
template <class RandomAccessIterator, class T>
inline void __linear_insert(RandomAccessIterator first,
RandomAccessIterator last, T*)
{
T value = *last; // 記錄尾元素
if (value < *first){ // 尾比頭還小 (注意,頭端必為最小元素)
copy_backward(first, last, last + 1); // 將整個區間向右移一個位置
*first = value; // 令頭元素等於原先的尾元素值
}
else // 尾不小於頭
__unguarded_linear_insert(last, value);
}
template <class RandomAccessIterator, class T>
void __unguarded_linear_insert(RandomAccessIterator last, T value)
{
RandomAccessIterator next = last;
--next;
// --- insertion sort 內迴圈 ---
// 注意,一旦不再出現逆轉對(inversion),迴圈就可以結束了
while (value < *next){ // 逆轉對(inversion)存在
*last = *next; // 調整
last = next; // 調整迭代器
--next; // 左移一個位置
}
*last = value; // value 的正確落腳處
}上述函式之所以命名為unguarded_x是因為,一般的Insertion Sort在內迴圈原本需要做兩次判斷,判斷是否相鄰兩元素是”逆轉對“,同時也判斷迴圈的行進是否超過邊界。但由於上述所示的原始碼會導致最小值必然在內迴圈子區間的邊緣,所以兩個判斷可合為一個判斷,所以稱為unguarded_。省下一個判斷操作,在大資料量的情況下,影響還是可觀的。
Quick Sort是目前已知最快的排序法,平均複雜度為O(NlogN),可是最壞情況下將達O(N^2)。
Quick Sort演算法可以敘述如下。假設S代表將被處理的序列:
1. 如果S的元素個數為0或1,結束。
2. 取S中的任何一個元素,當做樞軸(pivot) v。
3. 將S分割為L、R兩段,使L內的每一個元素都小於或等於v,R內的每一個元素都大於或等於v。
4. 對L、R遞迴執行Quick Sort。
Median-of-Three(三點中值)
因為任何元素都可以當做樞軸(pivot),為了避免元素輸入時不夠隨機帶來的惡化效應,最理想最穩當的方式就是取整個序列的投、尾、中央三個元素的中值(median)作為樞軸。這種做法稱為median-of-three partitioning。
Quick Sort
// 返回 a,b,c之居中者
template <class T>
inline const T& __median(const T& a, const T& b, const T& c)
{
if (a < b)
if (b < c) // a < b < c
return b;
else if (a < c) // a < b, b >= c, a < c --> a < b <= c
return c;
else // a < b, b >= c, a >= c --> c <= a < b
return a;
else if (a < c) // c > a >= b
return a;
else if (b < c) // a >= b, a >= c, b < c --> b < c <= a
return c;
else // a >= b, a >= c, b >= c --> c<= b <= a
return b;
}Partitioning(分割)
分割方法有很多,以下敘述既簡單又有良好成效的做法。令first向尾移動,last向頭移動。當*first大於或等於pivot時停下來,當*last小於或等於pivot時也停下來,然後檢驗兩個迭代器是否交錯。未交錯則元素互相,然後各自調整一個位置,再繼續相同行為。若交錯,則以此時first為軸將序列分為左右兩半,左邊值都小於或等於pivot,右邊都大於等於pivot
Partitioning
template <class RandomAccessIterator, class T>
RandomAccessIterator __unguarded_partition(
RandomAccessIterator first,
RandomAccessIterator last,
T pivot)
{
while(true){
while (*first < pivot) ++first; // first 找到 >= pivot的元素就停
--last;
while (pivot < *last) --last; // last 找到 <=pivot
if (!(first < last)) return first; // 交錯,結束迴圈
// else
iter_swap(first,last); // 大小值交換
++first; // 調整
}
}Heap Sort:partial_sort(),即heap不斷將頭取出.
Heap Sort
// paitial_sort的任務是找出middle - first個最小元素。
template <class RandomAccessIterator>
inline void partial_sort(RandomAccessIterator first,
RandomAccessIterator middle,
RandomAccessIterator last)
{
__partial_sort(first, middle, last, value_type(first));
}
template <class RandomAccessIterator,class T>
inline void __partial_sort(RandomAccessIterator first,
RandomAccessIterator middle,
RandomAccessIterator last, T*)
{
make_heap(first, middle); // 預設是max-heap,即root是最大的
for (RandomAccessIterator i = middle; i < last; ++i)
if (*i < *first)
__pop_heap(first, middle, i, T(*i), distance_type(first));
sort_heap(first,middle);
}IntroSort
不當的樞軸選擇,導致不當的分割,導致Quick Sort惡化為O(N^2)。David R. Musser於1996年提出一種混合式排序演算法,Introspective Sorting。其行為在大部分情況下幾乎與 median-of-3 Quick Sort完全相同。但是當分割行為(partitioning)有惡化為二次行為傾向時,能自我偵測,轉而改用Heap Sort,使效率維持在O(NlogN),又比一開始就使用Heap Sort來得好。大部分STL的sort內部其實就是用的IntroSort。
template <class RandomAccessIterator>
inline void sort(RandomAccessIterator first,
RandomAccessIterator last)
{
if (first != last){
__introsort_loop(first, last, value_type(first), __lg(last-first)*2);
__final_insertion_sort(first,last);
}
}
// __lg()用來控制分割惡化的情況
// 找出2^k <= n 的最大值,例:n=7得k=2; n=20得k=4
template<class Size>
inline Size __lg(Size n)
{
Size k;
for (k = 0; n > 1; n >>= 1)
++k;
return k;
} // 當元素個數為40時,__introsort_loop的最後一個引數
// 即__lg(last-first)*2是5*2,意思是最多允許分割10層。
const int __stl_threshold = 16;
template <class RandomAccessIterator, class T, class Size>
void __introsort_loop(RandomAccessIterator first,
RandomAccessIterator last, T*,
Size depth_limit)
{
while (last - first > __stl_threshold){ // > 16
if (depth_limit == 0){ // 至此,分割惡化
partial_sort(first, last, last); // 改用 heapsort
return;
}
--depth_limit;
// 以下是 median-of-3 partition,選擇一個夠好的樞軸並決定分割點
// 分割點將落在迭代器cut身上
RandomAccessIterator cut = __unguarded_partition
(first, last, T(__median(*first,
*(first + (last - first)/2),
*(last - 1))));
// 對右半段遞迴進行sort
__introsort_loop(cut,last,value_type(first), depth_limit);
last = cut;
// 現在回到while迴圈中,準備對左半段遞迴進行sort
// 這種寫法可讀性較差,效率也並沒有比較好
}
}函式一開始就判斷序列大小,通過個數檢驗之後,再檢測分割層次,若分割層次超過指定值,就改用partial_sort(),即Heap sort。都通過了這些校驗之後,便進入與Quick Sort完全相同的程式。
當__introsort_loop()結束,[first,last)內有多個“元素個數少於或等於”16的子序列,每個序列有相當程式的排序,但尚未完全排序(因為元素個數一旦小於 __stl_threshold,就被中止了)。回到母函式,再進入__final_insertion_sort():
template <class RandomAccessIterator>
void __final_insertion_sort(RandomAccessIterator first,
RandomAccessIterator last)
{
if (last - first > __stl_threshold){
// > 16
// 一、[first,first+16)進行插入排序
// 二、呼叫__unguarded_insertion_sort,實質是直接進入插入排序內迴圈,
// *參見Insertion sort 原始碼
__insertion_sort(first,first + __stl_threshold);
__unguarded_insertion_sort(first + __stl_threshold, last);
}
else
__insertion_sort(first, last);
}
template <class RandomAccessIterator>
inline void __unguarded_insertion_sort(RandomAccessIterator first,
RandomAccessIterator last)
{
__unguarded_insertion_sort_aux(first, last, value_type(first));
}
template <class RandomAccessIterator, class T>
void __unguarded_insertion_sort_aux(RandomAccessIterator first,
RandomAccessIterator last,
T*)
{
for (RandomAccessIterator i = first; i != last; ++i)
__unguarded_linear_insert(i, T(*i));
}