
【機器學習PAI實踐七】文字分析演算法實現新聞自動分類
一、背景
新聞分類是文字挖掘領域較為常見的場景。目前很多媒體或是內容生產商對於新聞這種文字的分類常常採用人肉打標的方式,消耗了大量的人力資源。本文嘗試通過智慧的文字挖掘演算法對於新聞文字進行分類。無需任何人肉打標,完全由機器智慧化實現。
本文通過PLDA演算法挖掘文章的主題,通過主題權重的聚類,實現新聞自動分類。包括了分詞、詞型轉換、停用詞過濾、主題挖掘、聚類等流程。
二、資料集介紹
具體欄位如下:
| 欄位名 | 含義 | 型別 | 描述 |
|---|---|---|---|
| category | 新聞型別 | string | 體育、女性、社會、軍事、科技等 |
| title | 標題 | string | 新聞標題 |
| content | 內容 | string | 新聞內容 |
資料截圖:

三、資料探索流程
首先,實驗流程圖:
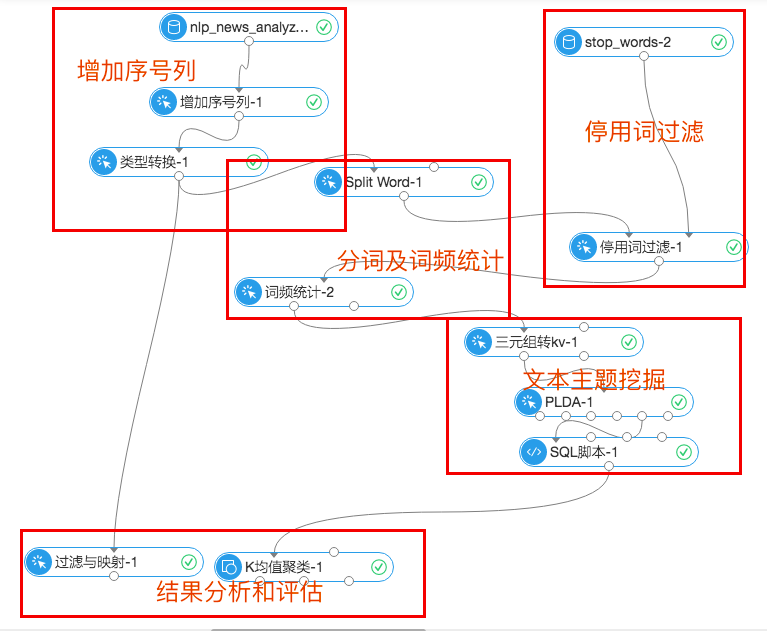
實驗可以大致分為五個模組,分別是增加序號列、停用詞過濾、分詞及詞頻統計、文字主題挖掘、結果分析和評估。
1.增加序號列
本文的資料來源輸入是以單個新聞為單元,需要增加ID列來作為每篇新聞的唯一標識,方便下面的演算法進行計算。
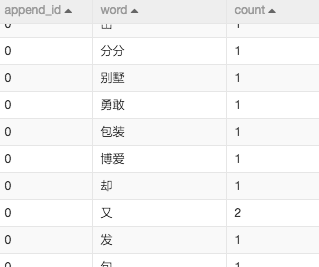
2.分詞及詞頻統計
這兩步都是文字挖掘領域最常規的做法,首先利用分詞控制元件對於content欄位,也就是新聞內容進行分詞。去除過濾詞之後(過濾詞一般是標點符號及助語),對於詞頻進行統計。
如下圖:
3.停用詞過濾
停用詞過濾功能用於過濾輸入的停用詞詞庫,一般過濾標點符號以及對於文章影響較少的助語等。
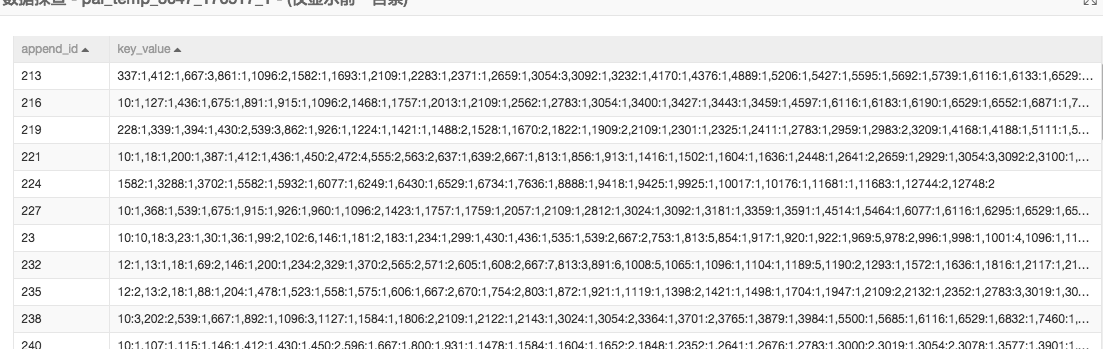
4.文字主題挖掘
使用PLDA文字挖掘元件需要先將文字轉換成三元形式,append_id是每篇新聞的唯一標識,key_value欄位中冒號前面的數字表示的是單詞抽象成的數字標識,冒號後面是對應的單詞出現的頻率。三元組元件生成結果如下:
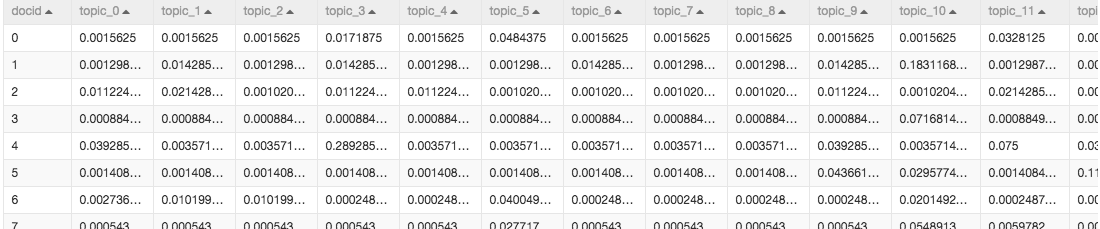
在上一步完成了文字轉數字的過程,下一步資料進入PLDA演算法。PLDA演算法又叫主題模型,演算法可以定位代表每篇文章的主題的詞語。本次試驗設定了50個主題,PLDA有六個輸出樁,第五個輸出樁輸出結果顯示的是每篇文章對應的每個主題的概率。如圖:
5.結果分析和評估
上一步把文章從主題的維度表示成了一個向量。接下來就可以通過向量的距離實現聚類,從而實現文章分類。我們這裡可以簡單看一下分類的結果。檢視K均值聚類元件的結果,cluster_index表示的是每一類的名稱。找到第0類,一共有docid為115,292,248,166四篇文章。
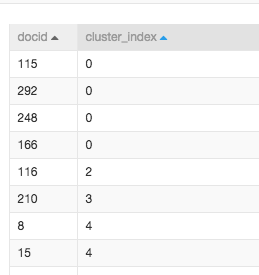
通過過濾與對映元件查詢115,292,248,166四篇文章。結果如下:

效果並不十分理想,將一篇財經、一篇科技的新聞跟兩個體育類新聞分到了一起。主要原因是細節的調優沒有做,也沒有做特徵工程,同時資料量太小也是一個主要的因素。本文只是一個簡單的案例,商業合作可以私下聯絡我們,我們在文字方面我們有較完善的解決方案。
四、其它
作者微信公眾號(與我聯絡):
