
【機器學習PAI實戰】—— 玩轉人工智慧之商品價格預測

前言
我們經常思考機器學習,深度學習,以至於人工智慧給我們帶來什麼?在資料相對充足,足夠真實的情況下,好的學習模型可以發現事件本身的內在規則,內在聯絡。我們去除冗餘的資訊,可以通過最少的特徵構建最簡單、誤差最小的模型,以此將學習到的規則,邏輯應用到具體的場景中,幫助我們可以快速準確的處理某些繁瑣重複的工作。
在本篇的案例中,我們將對迴歸模型做一次具體的分析和應用。迴歸可以做什麼?與分類模型不同,分類模型的預測值是固定的,而回歸模型可以預測連續型的資料結果。比如商品銷量預測,商品價格預測等等。常用的迴歸模型包括線性迴歸,加權線性迴歸,嶺迴歸以及樹迴歸。在接下來的具體場景中,我們將分析上述的迴歸演算法,選擇最適合目前場景和已有資料的迴歸演算法。
場景描述
某收藏愛好者,欲購買某知名品牌的積木套裝。為了瞭解現在的市場行情,他收集了關於該品牌積木的生成日期,是否為全新的,積木數量,原始價格等特徵和已交易的價格。他想要根據這些資料,來預估現在市場上正在出售的積木價格,才可以選擇合適的價格購入,但他發現經憑藉經驗來預測這些價格,往往不夠準確,而且繁瑣重複的工作相當耗費精力。並且他了解到阿里PAI平臺,可以通過智慧的方法,針對具體場景快速搭建解決方案。但是自己的問題能不能被很好的解決,具體該怎麼去實施還是一頭霧水,下面就讓我們伴隨他一起走進阿里機器學習平臺PAI的實戰。
資料分析
在拿到收集到的資料之後,我們要先對資料進行簡單的分析,來選擇合適的演算法。
price date number is_new origin_price
0 85.00 2006 797 0.0 49.99
1 102.50 2006 799 0.0 49.99
2 77.00 2006 795 0.0 49.99
3 162.50 2006 800 0.0 49.99
4 699.99 2002 3094 0.0 269.99
5 602.00 2002 3093 0.0 269.99
6 515.00 2002 3090 0.0 269.99
7 510.00 2002 3090 0.0 269.99
8 375.00 2002 3086 0.0 269.99
9 850.00 2002 3096 1.0 269.99
10 740.00 2002 3096 0.0 269.99
11 759.00 2002 3096 1.0 269.99
12 730.00 2002 3096 0.0 269.99
13 750.00 2002 3096 1.0 269.99
14 910.00 2007 5195 0.0 499.99
15 1199.99 2007 5195 1.0 499.99
16 811.88 2007 5194 0.0 499.99
17 1324.79 2007 5195 0.0 499.99
18 850.00 2007 5195 1.0 499.99
19 800.00 2007 5195 1.0 499.99
20 810.00 2007 5194 0.0 499.99
21 1075.00 2007 5195 1.0 499.99
22 1050.00 2007 5195 0.0 499.99
我們截取了部分資料,從第三列到第為列特徵含義依次是生成年份,積木數量,是否為全新以及原價。第二列為收集到的已交易的價格。
- 資料型別
我們驚喜的發現,所有資料都是連續性的,而不是標稱性資料。所謂連續型就是不可列舉,數值是聯絡可變的,而標稱型資料就是幾個固定的值,比如學生性別,手機型號,衣服尺碼(L,XL,XXL)等。如果不是連續型資料,就需要做資料的量化處理。
- 資料特徵分析
通過上面的部分資料,我們可以直觀的看出下面資訊。
1,年份和原價具有強相關性,換句話說年份和原價具有對等關係,這兩個特徵為重複特徵,其包含的資訊是一樣的;2,是否為全新這個特徵,是二值特徵。不能表示商品的新舊程度。3,積木數量若存在缺失,將嚴重影響價格。4,收藏品價格會在一定程度上高於原價。
- 資料量
我們從這位收藏愛好者處瞭解到,其收集到的資料不足100條。希望的場景是,如果再給一組樣本,可以快速的給出預測的價格。
場景抽象化
接下來,我們就需要把具體的問題抽象化。假設我們只用原價一個特徵來預估商品價格。
price= f(origin_price)=w*origin_price+b
f(x)就是一種目標值的計算公式。w,b就是線性迴歸係數,一旦得到這些係數,再輸入新的特徵值(原價)就可以計算出商品的交易價格。如果輸入特徵為多維的即:
price= f(date,number,is_new,origin_price,)=w1*date+w2*number+w3*is_new+w4*origin_price+b
當然我們有策略選擇哪些係數是最優的。在模型的學習和預測中,我們遇到帶標籤的資料,即已經知道交易價格的資料。通過這些標籤值和我們預測值的比較來判斷這組迴歸係數是不是最好的。
E=error(price-predicted_price)=||price-predicted_price|| l
當這組係數在所有資料中誤差為最小的,我們就可以說學習到了最優的引數來擬合訓練資料。
模型選擇
我們知道這個問題可以通過迴歸演算法來解決,就興致沖沖的打開了PAI 視覺化建模頁面進入了自己搭建的機器學習專案。進入方法如下:
在元件欄發現有好多回歸演算法可以選擇。

但是這麼多演算法該如何選擇?
模型的選擇絕大程度上依賴樣本的特徵,如果特徵值與樣本呈現明顯的線性關係,我們就選擇線性迴歸模型。比 如一本書的厚度和頁碼的關係。非線性迴歸的例子也有很多,比如圓形容器的蓄水量和容器的半徑的關係。當然大多是非線性迴歸也可以轉化成線性迴歸,這裡就不細談。
GBDT迴歸,是樹迴歸的一種,可以解決線性和非線性迴歸問題。
AdaBoost迴歸是一種強化迴歸演算法,AdaBoost是整合學習演算法,可以將弱學習器強化為強學習器,可以應用在分類和迴歸演算法。這裡AdaBoost迴歸就是一種強化的整合迴歸演算法。
PS-SMART,PS-線性迴歸,分別是基於PS是引數伺服器(Parameter server)的GBDT演算法和線性迴歸演算法。主要用於大規模資料的學習預測任務。
針對上面樣例,直觀的發現,價格與特徵呈明顯的線性關係。我們可以選擇線性迴歸作為嘗試。
資料處理
在模型訓練之前,需要對對訓練資料進行預處理。主要包括型別的轉化,量化,缺失值填充等等。現在我們有一份txt的格式的離線資料,內容樣本如上所示。通過對資料的分析,現有資料不需要進行型別的轉化和量化,可以進行缺失值的填充。在進入預處理之前,我們需要將訓練樣本放到odps表中。
- 首先,開啟dataworks-資料開發,如下圖所示,進入Dataworks 自己專案下的資料開發平臺:
- 新建節點,輸入下面程式碼,選中程式碼,點選執行按鈕,新建odps表。
CREATE TABLE if not EXISTS item_features
(
price Double COMMENT "預測價格",
production_date BIGINT COMMENT "production_date",
quantity BIGINT COMMENT "數量",
is_new DOUBLE COMMENT "1:new,0:old",
original_price DOUBLE COMMENT "原價"
)
LIFECYCLE 7
;
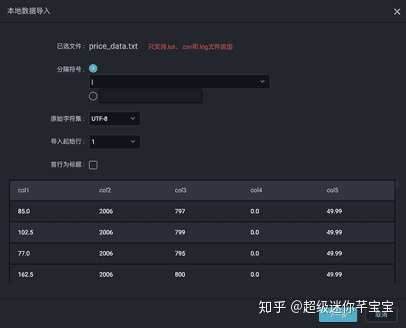
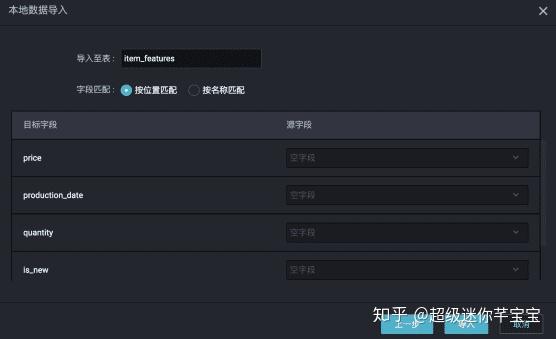
- 將本地資料匯入到odps表中。
分隔符為本地檔案的列之間的分隔符,預設為逗號。如果本地檔案中第一行不是標題,則選擇起始行為1,不勾選首行為標題。下一步,然後輸入新建的odps表名,選擇按位置匹配(只有前面選擇首行為標題,才可以選擇按名稱匹配),然後匯入。
至此,我們對資料有了充足的瞭解,知道選擇何種模型,需要對資料做什麼預處理,而且訓練資料也已準備好了。接下來,我就需要在PAI 視覺化建模頁面,拖拽元件,搭建視覺化訓練流程。
模型訓練
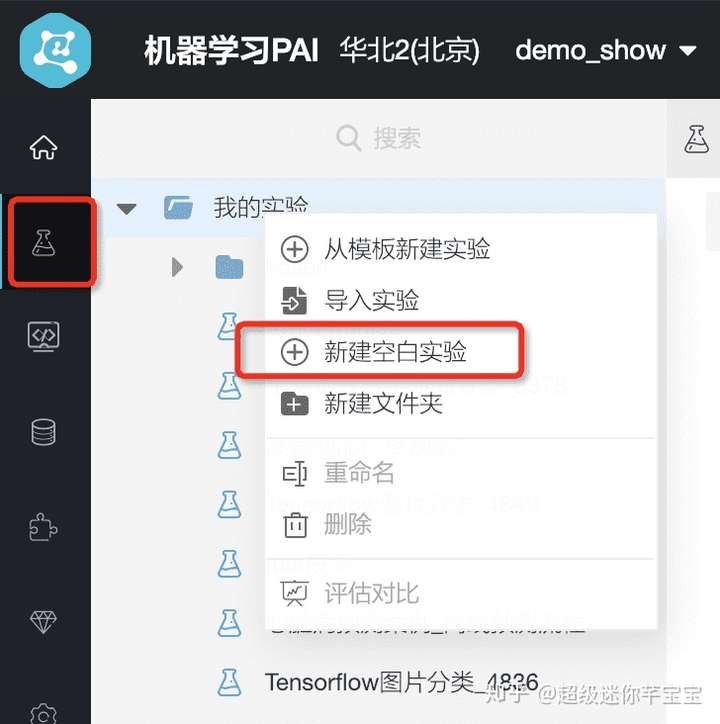
- 首先進入PAI 視覺化建模頁面,點選實驗-新建空白實驗。
- 拖拽資料讀取元件,源/目標-讀資料表。
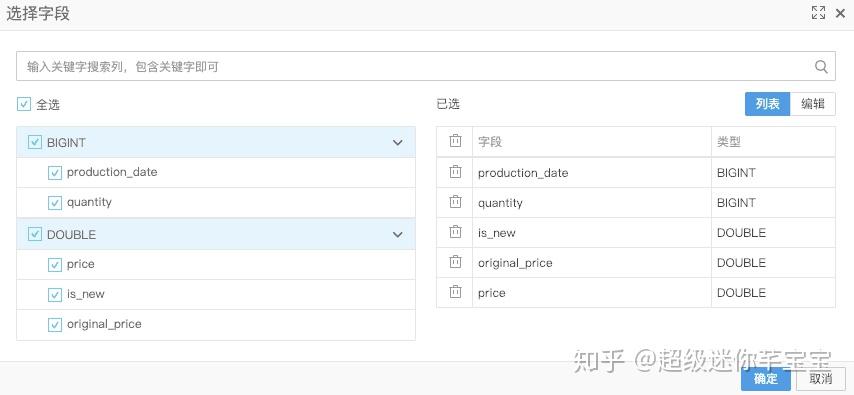
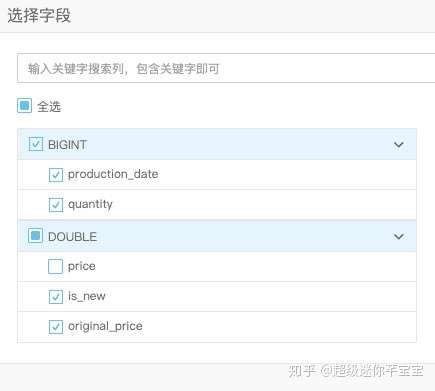
雙擊拖入的讀資料表元件,再表名列輸入,前面新建的odps表名。可以在欄位資訊欄看到表中部分資料。

- 拖入預設值填充元件,資料預處理-缺失值填充。
訓練資料中,可能存在部分特徵值缺失的情況,缺失值填充可以選擇多種測試填充缺失值。
在右側屬性欄,選擇進行填充的引數,原值型別和填充值策略。
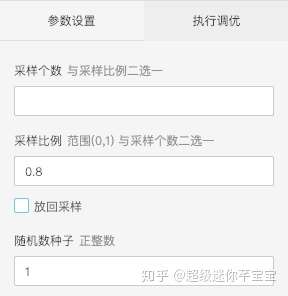
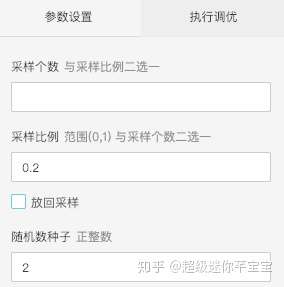
- 樣本隨機取樣
對於所有的訓練資料,我們可以有重疊的選擇出訓練集和測試集。拖入兩個隨機取樣元件,資料預處理-取樣與過濾-隨機取樣。欄位引數設定如下圖:
- 線性迴歸演算法
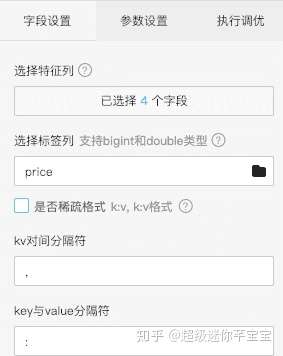
拖入線性迴歸演算法元件,機器學習-迴歸-線性迴歸。特徵列選擇 date number is_new origin_price特徵,標籤列為price。
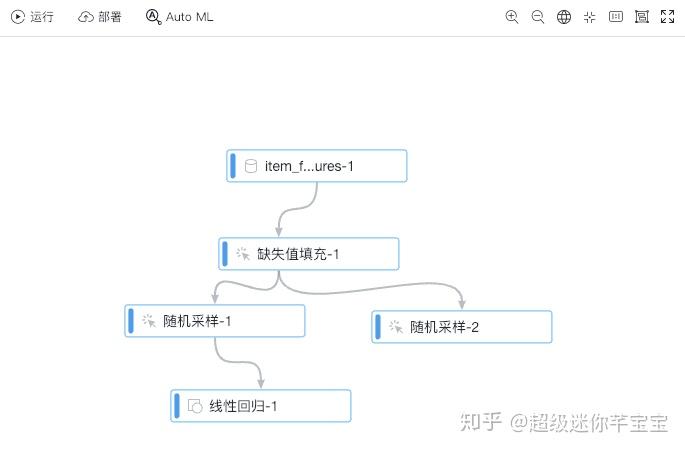
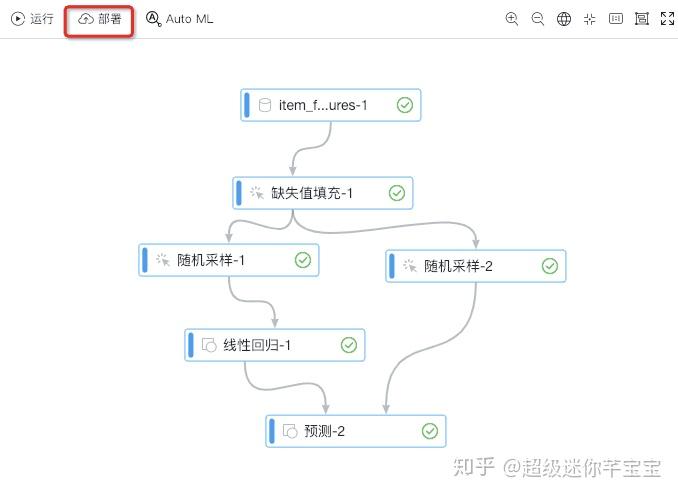
至此,如下圖所示,模型訓練的流程已搭建完成。點選執行,就可以依託PAI平臺服務,進行模型訓練了。
模型測試
通過模型訓練,學習得到了線性迴歸模型。在PAI平臺上,我們可以一鍵拖拽測試元件,機器學習-預測。對學習到的模型就行測試,並可以直觀的觀測模型預測的結果。
如下圖所示:

模型部署
詳情參考線上部署使用說明。
- 檢視模型
線上性迴歸模型元件,右鍵選擇模型選項-檢視模型,就可以看到學習到的模型。
- 儲存模型
右鍵選擇儲存模型,就可以將模型儲存到我的模型下。通過模型定位,就可以定位到我的模型處。
- 一鍵部署
模型訓練完成之後,點選部署-線上部署。輸入自定義的服務名稱(全網唯一,呼叫服務時使用)。
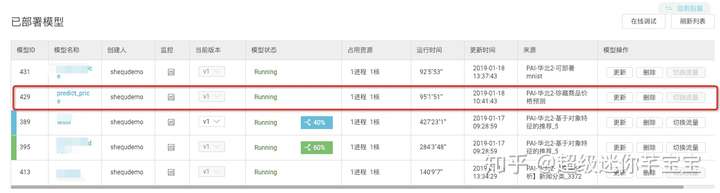
在已部署模型頁可以看到,自己部署的所有服務。
服務測試
詳情參考線上部署使用說明。
注意事項,body引數要按照特徵值的數量給出,每一條是一個字典,欄位要和表結構一致,多條資料以陣列形式新增。
總結
迴歸演算法和分類演算法類似,也是對目標值的預測。其中迴歸演算法主要用於對聯絡值的預測,而分類演算法預測的則是離散值。在PAI平臺上有常用的各類迴歸演算法,如果有興趣,可以一一嘗試,選擇最適合自己場景和資料的迴歸演算法。在接到一個具體的場景和問題後,通常我們需要一系列的步驟去解決這個問題,收集資料,準備資料,分析資料,演算法選擇,訓練演算法,測試演算法,使用演算法。同時,PAI平臺中這些迴歸演算法元件還支援部分演算法引數的調整,比如迭代次數,最小誤差,以及正則化係數等等,我們可以在訓練演算法模型中調整這些引數以達到最小可接受的誤差。
本文為雲棲社群原創內容,未經