
【機器學習PAI實戰】—— 玩轉人工智慧之美食推薦

前言
在生活中,我們經常給朋友推薦一些自己喜歡的東西,也時常接受別人的推薦。怎麼能保證推薦的電影或者美食就是朋友喜歡的呢?一般來說,你們兩個人經常對同一個電影或者美食感興趣,那麼你喜歡的東西就很大程度上朋友也會比較感興趣。在大資料的背景下,演算法會幫我尋找興趣相似的那些人,並關注他們喜歡的東西,以此來給我們推薦可能喜歡的事物。
場景描述
某外賣店鋪收集了一些使用者對本店鋪美食的評價和推薦分,並計劃為一些新老客戶推薦他們未曾嘗試的美食。
資料分析
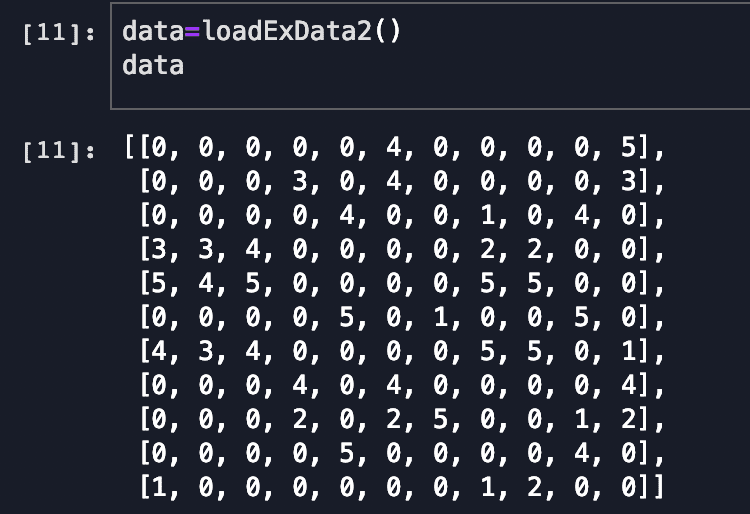
A B C D E F G H I J K 0[0, 0, 0, 0, 0, 4, 0, 0, 0, 0, 5], 1[0, 0, 0, 3, 0, 4, 0, 0, 0, 0, 3], 2[0, 0, 0, 0, 4, 0, 0, 1, 0, 4, 0], 3[5, 4, 5, 0, 0, 0, 0, 5, 5, 0, 0], 4[0, 0, 0, 0, 5, 0, 1, 0, 0, 5, 0], 5[4, 3, 4, 0, 0, 0, 0, 5, 5, 0, 1], 6[0, 0, 0, 4, 0, 4, 0, 0, 0, 0, 4], 7[0, 0, 0, 2, 0, 2, 5, 0, 0, 1, 2], 8[0, 0, 0, 0, 5, 0, 0, 0, 0, 4, 0], 9[1, 0, 0, 0, 0, 0, 0, 1, 2, 0, 0]
橫軸為美食品種,分為A--K 11中,豎軸為使用者序號,有0-9 10個人。表內值為某個使用者對某種美食的推薦分,0表示其未曾吃過,5分為最高的推薦分。以上資料為實驗虛構資料。
場景抽象化
給定一個使用者i,我們根據上面的資料為其推薦N個推薦分最高的美食。
模型選擇
協同過濾簡單來說是利用某興趣相投、擁有共同經驗之群體的喜好來推薦使用者感興趣的資訊,個人通過合作的機制給予資訊相當程度的迴應(如評分)並記錄下來以達到過濾的目的進而幫助別人篩選資訊,迴應不一定侷限於特別感興趣的,特別不感興趣資訊的紀錄也相當重要。
我們也將採用協同過濾來實現商品推薦,並在下面的章節一步步實現基於協同過濾的商品推薦系統。
資料處理
以上資料,不存在缺失和無意義推薦分,即不超出範圍,格式正確。
搭建環境
- 首先進入noteBook建模,連結

- 然後建立新例項

- 之後開啟例項
現在基礎環境以及搞定了,我們可以用terminal安裝自己需要的包環境。同時可以選擇python2或者python3的開發環境。而且左側的檔案系統,支援本地檔案的上傳下載等。
相似度計算
在推薦系統中,我們需要計算兩個人或商品的相似度,我們可以採用餘弦相似度,皮爾遜相關係數等。
餘弦相似性通過測量兩個向量的夾角的餘弦值來度量它們之間的相似性。0度角的餘弦值是1,表示完全一樣,而其他任何角度的餘弦值都不大於1;並且其最小值是-1,相似度為0。
皮爾遜相關係數( Pearson correlation coefficient),是用於度量兩個變數X和Y之間的相關(線性相關),其值介於-1與1之間。
新建檔案recom.py,實現相似度計算函式
def cosSim(inA,inB):
num = float(inA.T*inB)
denom = la.norm(inA)*la.norm(inB)
return 0.5+0.5*(num/denom)推薦分計算
在檔案recom.py,實現推薦分計算
#dataMat 使用者與美食的矩陣
#user 使用者序號
#simMeas 相似度演算法
#item 美食商品
def standEst(dataMat, user, simMeas, item):
n = shape(dataMat)[1]#商品數
simTotal = 0.0; ratSimTotal = 0.0
for j in range(n):#所有商品,遍歷
userRating = dataMat[user,j]#user對該商品的推薦分
if userRating == 0: continue#如果user 未推薦該商品則過濾
#logical_and邏輯與,nonzero非零判斷,overLap為均為商品item,j推薦的使用者
overLap = nonzero(logical_and(dataMat[:,item].A>0, \
dataMat[:,j].A>0))[0]
if len(overLap) == 0: similarity = 0
#以此overLap,計算兩商品的相似度。
else: similarity = simMeas(dataMat[overLap,item], \
dataMat[overLap,j])
print('the %d and %d similarity is: %f' % (item, j, similarity))
simTotal += similarity
ratSimTotal += similarity * userRating
if simTotal == 0: return 0
else: return ratSimTotal/simTotal對於特徵向量非常稀疏,或者特徵之間關聯關係明顯,協方差較大則需要對原有維度的特徵進行降維。這樣既可以節省資源加快運算,也可以避免冗餘特徵帶來的干擾。
def svdEst(dataMat, user, simMeas, item):
n = shape(dataMat)[1]
simTotal = 0.0; ratSimTotal = 0.0
U,Sigma,VT = la.svd(dataMat) #奇異值分解
Sig4 = mat(eye(4)*Sigma[:4]) #構建對角矩陣
xformedItems = dataMat.T * U[:,:4] * Sig4.I #資料維度轉換
for j in range(n):
userRating = dataMat[user,j]
if userRating == 0 or j==item: continue
similarity = simMeas(xformedItems[item,:].T,\
xformedItems[j,:].T)
print('the %d and %d similarity is: %f' % (item, j, similarity))
simTotal += similarity
ratSimTotal += similarity * userRating
if simTotal == 0: return 0
else: return ratSimTotal/simTotal通過計算待推薦商品與已推薦商品的相似度,並乘以該使用者對已推薦商品的推薦分,來計算待推薦商品的推薦分。
在檔案recom.py,加入recommend函式
#dataMat 使用者與美食的矩陣
#user 使用者序號
#N 推薦前N個商品
#simMeas 相似度計算演算法
#estMethod 推薦分計算演算法
def recommend(dataMat, user, N=3, simMeas=cosSim, estMethod=standEst):
#找出user未評分的商品
unratedItems = nonzero(dataMat[user,:].A==0)[1]#find unrated items
if len(unratedItems) == 0: return 'you rated everything'
itemScores = []
#依次計算這些商品的推薦分
for item in unratedItems:
estimatedScore = estMethod(dataMat, user, simMeas, item)
itemScores.append((item, estimatedScore))
#返回前N個較好分的結果
return sorted(itemScores, key=lambda jj: jj[1], reverse=True)[:N]演算法演示
如果是本地編輯的檔案,可以通過檔案上傳方式上傳到伺服器。
- 新建noteBook演示
- 載入演算法模板

- 資料展示
- 為序號為2的使用者推薦商品
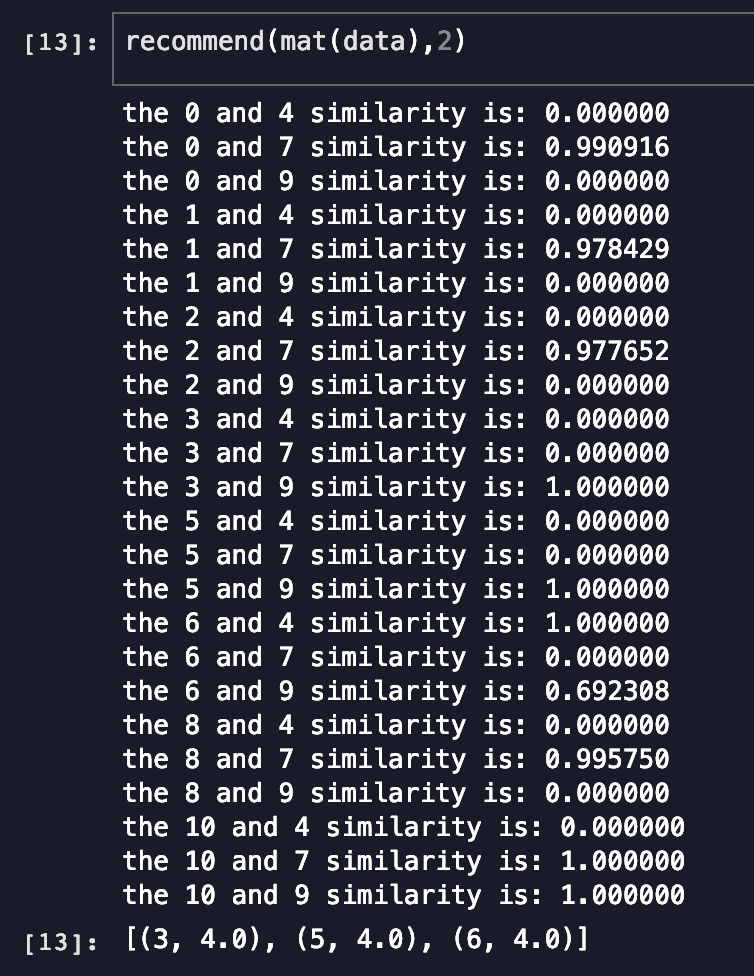
總結
通常在計算相似度之前,我們需要確定是計算基於商品的相似度(上面的方式),還是計算基於使用者的相似度。在現實情況下,我們要根據使用者和商品的資料決定選擇哪種計算方式。同時,在資料量變大時,我們通常需要先降維,在做商品推薦。部分程式碼參考《機器學習實戰》,本篇文章主要介紹如何使用PAI-DSW實現演算法實驗。
開發十年,就只剩下這套架構體系了!
>>>
開發十年,就只剩下這套架構體系了!
>>>
是否 pla 聯系 比較 ima 缺失值 根據 人工智能 快速
摘要: 分類問題是生活中最常遇到的問題之一。普通人在做出選擇之前,可能會猶豫不決,但對機器而言,則是唯一必選的問題。我們可以通過算法生成模型去幫助我們快速的做出選擇,而且保證誤差最小。充足的樣本,合適的算法 區域 targe 使用方式 team 包含 csdn 作者 我們 行處理 一、背景
感謝大家關註玩轉數據系列文章,我們希望通過在阿裏雲機器學習平臺上提供demo數據並搭建相關的實驗流程的方式來幫助大家學習如何通過算法來挖掘數據中的價值。本系列文章包含詳細的實驗流程以及相關
背景
如果你是做網際網路金融的,那麼一定聽說過評分卡。評分卡是信用風險評估領域常用的建模方法,評分卡並不簡單對應於某一種機器學習演算法,而是一種通用的建模框架,將原始資料通過分箱後進行特徵工程變換,繼而應用於線性模型進行建模的一種方法。
評分卡建模理論常
一、背景
新聞分類是文字挖掘領域較為常見的場景。目前很多媒體或是內容生產商對於新聞這種文字的分類常常採用人肉打標的方式,消耗了大量的人力資源。本文嘗試通過智慧的文字挖掘演算法對於新聞文字進行分類。無需任何人肉打標,完全由機器智慧化實現。
本文通過PLDA演算
背景
我們在之前的文章中介紹過如何通過PAI內建的TensorFlow框架實驗基於Cifar10的影象分類,文章連結:https://yq.aliyun.com/articles/72841。使用Tensorflow做深度學習做深度學習的網路搭建和訓練需要通過 model 但是 目標 學習 imp 選擇 處理 定義 條件 課程定位:
註重基礎、故事性
機器學習定義:
data - Algo - improve
機器學習使用條件
1、有優化的目標,可量化的。
2、規則不容易寫下來,需要學習。
3、要有數據
一個可能的推薦 證明 機器學習 sign 線性可分 缺點 學習 犯錯 nbsp 錯誤 感知機算法:
1、首先找到點,使得sign(wt * xt) != yt,
那麽如果yt = 1,說明wt和xt呈負角度,wt+1 = wt + xt能令wt偏向正角度。
如果yt = -1, 說 質數 一個 非監督 輸入 編號 不同 象棋 按順序 pla 一、不同的output
1、二分類
2、多分類
3、回歸問題
4、structured learn: 從一個句子 -> 句子每個 詞的詞性。
輸出是一個結構化的東西。
例子:蛋白質數據 -> 機器學習 估計 事情 永遠 pro app out 天下 oba 天下沒有白吃的午餐,從樣本內到樣本外永遠無法估計。
抽樣的話,樣本內頻率和樣本外概率相等PAC (probably approximately correct)
一個重要的事情是樣本要在總體分布中取。
E 總結 ora 二次 判斷 天都 特性 以及 解釋 意思 【機器學習基本理論】詳解最大似然估計(MLE)、最大後驗概率估計(MAP),以及貝葉斯公式的理解
https://mp.csdn.net/postedit/81664644
最大似然估計(Maximum lik 目錄
線性代數
一、基本知識
二、向量操作
三、矩陣運算
線性代數
一、基本知識
本書中所有的向量都是列向量的形式: \[\mathbf{\vec x}=(x_1,x_2,\cdots,x_n)^T=\begin{bmatrix}x_1\\x_2\
分享一下我老師大神的人工智慧教程!零基礎,通俗易懂!http://blog.csdn.net/jiangjunshow
也歡迎大家轉載本篇文章。分享知識,造福人民,實現我們中華民族偉大復興!
分享一下我老師大神的人工智慧教程!零基礎,通俗易懂!http://blog.csdn.net/jiangjunshow
也歡迎大家轉載本篇文章。分享知識,造福人民,實現我們中華民族偉大復興!
分享一下我老師大神的人工智慧教程!零基礎,通俗易懂!http://blog.csdn.net/jiangjunshow
也歡迎大家轉載本篇文章。分享知識,造福人民,實現我們中華民族偉大復興!
【參考資料】 【1】《蟻群演算法原理及其應用》 【2】測試資料: https://comopt.ifi.uni-heidelberg.de/software/TSPLIB95/tsp/att48.tsp.gz
演算法原理(以TSP問題為例)
(1)引數初始化。令時間t=0和迴圈次數
文章目錄
1 機器學習概念
2 線性迴歸
3 代價函式
4 代價函式求解
4.1 正規方程求解
4.2 梯度下降法
4.2.1 批量梯度下降(BGD)
4.2.2 隨機梯
數學基礎
1.轉置矩陣
定義: 將矩陣A同序數的行換成列成為轉置矩陣ATA^TAT,舉例:
A=(1203−11)A=\begin{pmatrix}
1 & 2 & 0 \\
3 & -1 &
【參考資料】
【1】《概率論與數理統計》
【2】 http://scikit-learn.org /stable/auto_examples/ linear_model/ plot_ols.html # sphx-glr-auto-examples- 相關推薦
【機器學習PAI實戰】—— 玩轉人工智慧之美食推薦
【機器學習PAI實戰】—— 玩轉人工智慧之商品價格預測
【機器學習PAI實戰】—— 玩轉人工智能之你最喜歡哪個男生?
【機器學習PAI實踐二】人口普查統計
【機器學習PAI實踐十二】機器學習演算法基於信用卡消費記錄做信用評分
【機器學習PAI實踐七】文字分析演算法實現新聞自動分類
【機器學習PAI實踐十】深度學習Caffe框架實現影象分類的模型訓練
【機器學習基石筆記】一、綜述
【機器學習基石筆記】二、感知機
【機器學習基石筆記】三、不同類型的機器學習
【機器學習基石筆記】四、無法學習?
【機器學習基本理論】詳解最大似然估計(MLE)、最大後驗概率估計(MAP),以及貝葉斯公式的理解
【機器學習數學基礎】線性代數基礎
【機器學習演算法實現】主成分分析 PCA ——基於python+numpy
【機器學習演算法實現】logistic迴歸 基於Python和Numpy函式庫
【機器學習演算法實現】kNN演算法 手寫識別——基於Python和NumPy函式庫
【機器學習筆記35】蟻群演算法
【機器學習演算法總結】線性迴歸
【機器學習筆記02】最小二乘法(多元線性迴歸模型)
【機器學習筆記01】最小二乘法(一元線性迴歸模型)