TensorFlow實現ResNet(ResNet 152網路結構的forward耗時檢測)(轉)
阿新 • • 發佈:2019-01-04
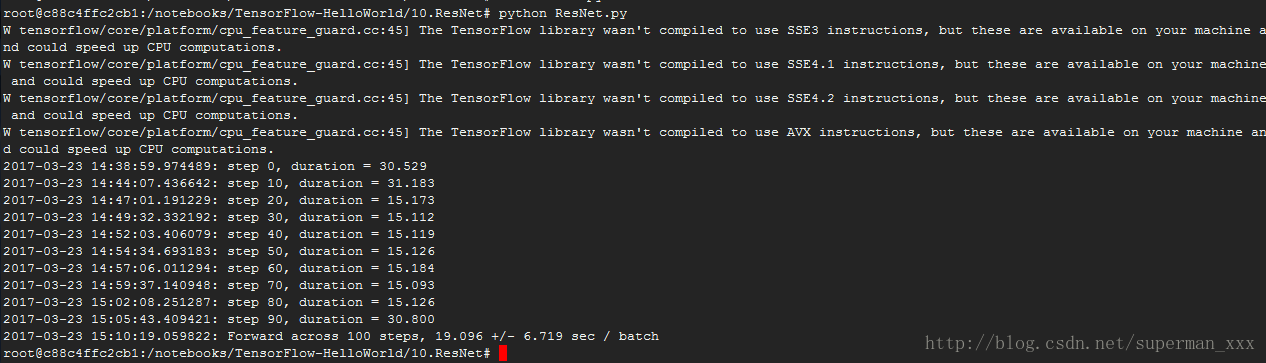
結構有ResNet 50、ResNet 152、ResNet 200,考慮耗時原因只跑了ResNet 152網路結構的forward。
# coding:UTF-8 """ Typical use: from tensorflow.contrib.slim.nets import resnet_v2 ResNet-101 for image classification into 1000 classes: # inputs has shape [batch, 224, 224, 3] with slim.arg_scope(resnet_v2.resnet_arg_scope(is_training)): net, end_points = resnet_v2.resnet_v2_101(inputs, 1000) ResNet-101 for semantic segmentation into 21 classes: # inputs has shape [batch, 513, 513, 3] with slim.arg_scope(resnet_v2.resnet_arg_scope(is_training)): net, end_points = resnet_v2.resnet_v2_101(inputs, 21, global_pool=False, output_stride=16) """ import collections # 原生的collections庫 import tensorflow as tf slim = tf.contrib.slim # 使用方便的contrib.slim庫來輔助建立ResNet class Block(collections.namedtuple('Block', ['scope', 'unit_fn', 'args'])): ''' 使用collections.namedtuple設計ResNet基本模組組的name tuple,並用它建立Block的類 只包含資料結構,不包含具體方法。 定義一個典型的Block,需要輸入三個引數: scope:Block的名稱 unit_fn:ResNet V2中的殘差學習單元 args:Block的args。 ''' ########定義一個降取樣的方法######## def subsample(inputs, factor, scope=None): """Subsamples the input along the spatial dimensions. Args: inputs: A `Tensor` of size [batch, height_in, width_in, channels]. factor: The subsampling factor.(取樣因子) scope: Optional variable_scope. Returns: output: 如果factor為1,則不做修改直接返回inputs;如果不為1,則使用 slim.max_pool2d最大池化來實現,通過1*1的池化尺寸,stride作步長,實 現降取樣。 """ if factor == 1: return inputs else: return slim.max_pool2d(inputs, [1, 1], stride=factor, scope=scope) ########建立卷積層######## def conv2d_same(inputs, num_outputs, kernel_size, stride, scope=None): """ Args: inputs: A 4-D tensor of size [batch, height_in, width_in, channels]. num_outputs: An integer, the number of output filters. kernel_size: An int with the kernel_size of the filters. stride: An integer, the output stride. rate: An integer, rate for atrous convolution. scope: Scope. Returns: output: A 4-D tensor of size [batch, height_out, width_out, channels] with the convolution output. """ if stride == 1: return slim.conv2d(inputs, num_outputs, kernel_size, stride=1, padding='SAME', scope=scope) else: # 如果不為1,則顯式的pad zero,pad zero總數為kernel_size - 1 #kernel_size_effective = kernel_size + (kernel_size - 1) * (rate - 1) pad_total = kernel_size - 1 pad_beg = pad_total // 2 pad_end = pad_total - pad_beg inputs = tf.pad(inputs, # 對輸入變數進行補零操作 [[0, 0], [pad_beg, pad_end], [pad_beg, pad_end], [0, 0]]) # 因為已經進行了zero padding,所以只需再使用一個padding模式為VALID的slim.conv2d建立這個卷積層 return slim.conv2d(inputs, num_outputs, kernel_size, stride=stride, padding='VALID', scope=scope) ########定義堆疊Blocks的函式######## @slim.add_arg_scope def stack_blocks_dense(net, blocks, outputs_collections=None): """ Args: net: A `Tensor` of size [batch, height, width, channels].輸入。 blocks: 是之前定義的Block的class的列表。 outputs_collections: 收集各個end_points的collections。 Returns: net: Output tensor """ # 使用兩層迴圈,逐個Residual Unit地堆疊 for block in blocks: # 先使用兩個tf.variable_scope將殘差學習單元命名為block1/unit_1的形式 with tf.variable_scope(block.scope, 'block', [net]) as sc: for i, unit in enumerate(block.args): with tf.variable_scope('unit_%d' % (i + 1), values=[net]): # 在第2層迴圈中,我們拿到每個block中每個Residual Unit的args並展開為下面四個引數 unit_depth, unit_depth_bottleneck, unit_stride = unit net = block.unit_fn(net, # 使用殘差學習單元的生成函式順序的建立並連線所有的殘差學習單元 depth=unit_depth, depth_bottleneck=unit_depth_bottleneck, stride=unit_stride) net = slim.utils.collect_named_outputs(outputs_collections, sc.name, net) # 將輸出net新增到collections中 return net # 當所有block中的所有Residual Unit都堆疊完成之後,再返回最後的net作為stack_blocks_dense # 建立ResNet通用的arg_scope,arg_scope用來定義某些函式的引數預設值 def resnet_arg_scope(is_training=True, # 訓練標記 weight_decay=0.0001, # 權重衰減速率 batch_norm_decay=0.997, # BN的衰減速率 batch_norm_epsilon=1e-5, # BN的epsilon預設1e-5 batch_norm_scale=True): # BN的scale預設值 batch_norm_params = { # 定義batch normalization(標準化)的引數字典 'is_training': is_training, 'decay': batch_norm_decay, 'epsilon': batch_norm_epsilon, 'scale': batch_norm_scale, 'updates_collections': tf.GraphKeys.UPDATE_OPS, } with slim.arg_scope( # 通過slim.arg_scope將[slim.conv2d]的幾個預設引數設定好 [slim.conv2d], weights_regularizer=slim.l2_regularizer(weight_decay), # 權重正則器設定為L2正則 weights_initializer=slim.variance_scaling_initializer(), # 權重初始化器 activation_fn=tf.nn.relu, # 啟用函式 normalizer_fn=slim.batch_norm, # 標準化器設定為BN normalizer_params=batch_norm_params): with slim.arg_scope([slim.batch_norm], **batch_norm_params): with slim.arg_scope([slim.max_pool2d], padding='SAME') as arg_sc: # ResNet原論文是VALID模式,SAME模式可讓特徵對齊更簡單 return arg_sc # 最後將基層巢狀的arg_scope作為結果返回 # 定義核心的bottleneck殘差學習單元 @slim.add_arg_scope def bottleneck(inputs, depth, depth_bottleneck, stride, outputs_collections=None, scope=None): """ Args: inputs: A tensor of size [batch, height, width, channels]. depth、depth_bottleneck:、stride三個引數是前面blocks類中的args rate: An integer, rate for atrous convolution. outputs_collections: 是收集end_points的collection scope: 是這個unit的名稱。 """ with tf.variable_scope(scope, 'bottleneck_v2', [inputs]) as sc: # slim.utils.last_dimension獲取輸入的最後一個維度,即輸出通道數。 depth_in = slim.utils.last_dimension(inputs.get_shape(), min_rank=4) # 可以限定最少為四個維度 # 使用slim.batch_norm對輸入進行batch normalization,並使用relu函式進行預啟用preactivate preact = slim.batch_norm(inputs, activation_fn=tf.nn.relu, scope='preact') if depth == depth_in: shortcut = subsample(inputs, stride, 'shortcut') # 如果殘差單元的輸入通道數和輸出通道數一致,那麼按步長對inputs進行降取樣 else: shortcut = slim.conv2d(preact, depth, [1, 1], stride=stride, normalizer_fn=None, activation_fn=None, scope='shortcut') # 如果不一樣就按步長和1*1的卷積改變其通道數,使得輸入、輸出通道數一致 # 先是一個1*1尺寸,步長1,輸出通道數為depth_bottleneck的卷積 residual = slim.conv2d(preact, depth_bottleneck, [1, 1], stride=1, scope='conv1') # 然後是3*3尺寸,步長為stride,輸出通道數為depth_bottleneck的卷積 residual = conv2d_same(residual, depth_bottleneck, 3, stride, scope='conv2') # 最後是1*1卷積,步長1,輸出通道數depth的卷積,得到最終的residual。最後一層沒有正則項也沒有啟用函式 residual = slim.conv2d(residual, depth, [1, 1], stride=1, normalizer_fn=None, activation_fn=None, scope='conv3') output = shortcut + residual # 將降取樣的結果和residual相加 return slim.utils.collect_named_outputs(outputs_collections, # 將output新增進collection並返回output作為函式結果 sc.name, output) ########定義生成resnet_v2的主函式######## def resnet_v2(inputs, # A tensor of size [batch, height_in, width_in, channels].輸入 blocks, # 定義好的Block類的列表 num_classes=None, # 最後輸出的類數 global_pool=True, # 是否加上最後的一層全域性平均池化 include_root_block=True, # 是否加上ResNet網路最前面通常使用的7*7卷積和最大池化 reuse=None, # 是否重用 scope=None): # 整個網路的名稱 # 在函式體先定義好variable_scope和end_points_collection with tf.variable_scope(scope, 'resnet_v2', [inputs], reuse=reuse) as sc: end_points_collection = sc.original_name_scope + '_end_points' # 定義end_points_collection with slim.arg_scope([slim.conv2d, bottleneck, stack_blocks_dense], outputs_collections=end_points_collection): # 將三個引數的outputs_collections預設設定為end_points_collection net = inputs if include_root_block: # 根據標記值 with slim.arg_scope([slim.conv2d], activation_fn=None, normalizer_fn=None): net = conv2d_same(net, 64, 7, stride=2, scope='conv1') # 建立resnet最前面的64輸出通道的步長為2的7*7卷積 net = slim.max_pool2d(net, [3, 3], stride=2, scope='pool1') # 然後接最大池化 # 經歷過兩個步長為2的層圖片縮為1/4 net = stack_blocks_dense(net, blocks) # 將殘差學習模組組生成好 net = slim.batch_norm(net, activation_fn=tf.nn.relu, scope='postnorm') if global_pool: # 根據標記新增全域性平均池化層 net = tf.reduce_mean(net, [1, 2], name='pool5', keep_dims=True) # tf.reduce_mean實現全域性平均池化效率比avg_pool高 if num_classes is not None: # 是否有通道數 net = slim.conv2d(net, num_classes, [1, 1], activation_fn=None, # 無啟用函式和正則項 normalizer_fn=None, scope='logits') # 新增一個輸出通道num_classes的1*1的卷積 end_points = slim.utils.convert_collection_to_dict(end_points_collection) # 將collection轉化為python的dict if num_classes is not None: end_points['predictions'] = slim.softmax(net, scope='predictions') # 輸出網路結果 return net, end_points #------------------------------ResNet的生成函式定義好了---------------------------------------- def resnet_v2_50(inputs, # 影象尺寸縮小了32倍 num_classes=None, global_pool=True, reuse=None, # 是否重用 scope='resnet_v2_50'): blocks = [ Block('block1', bottleneck, [(256, 64, 1)] * 2 + [(256, 64, 2)]), # Args:: # 'block1':Block名稱(或scope) # bottleneck:ResNet V2殘差學習單元 # [(256, 64, 1)] * 2 + [(256, 64, 2)]:Block的Args,Args是一個列表。其中每個元素都對應一個bottleneck # 前兩個元素都是(256, 64, 1),最後一個是(256, 64, 2)。每個元素 # 都是一個三元tuple,即(depth,depth_bottleneck,stride)。 # (256, 64, 3)代表構建的bottleneck殘差學習單元(每個殘差學習單元包含三個卷積層)中,第三層輸出通道數 # depth為256,前兩層輸出通道數depth_bottleneck為64,且中間那層步長3。這個殘差學習單元結構為: # [(1*1/s1,64),(3*3/s2,64),(1*1/s1,256)] Block( 'block2', bottleneck, [(512, 128, 1)] * 3 + [(512, 128, 2)]), Block( 'block3', bottleneck, [(1024, 256, 1)] * 5 + [(1024, 256, 2)]), Block( 'block4', bottleneck, [(2048, 512, 1)] * 3)] return resnet_v2(inputs, blocks, num_classes, global_pool, include_root_block=True, reuse=reuse, scope=scope) def resnet_v2_101(inputs, # unit提升的主要場所是block3 num_classes=None, global_pool=True, reuse=None, scope='resnet_v2_101'): """ResNet-101 model of [1]. See resnet_v2() for arg and return description.""" blocks = [ Block( 'block1', bottleneck, [(256, 64, 1)] * 2 + [(256, 64, 2)]), Block( 'block2', bottleneck, [(512, 128, 1)] * 3 + [(512, 128, 2)]), Block( 'block3', bottleneck, [(1024, 256, 1)] * 22 + [(1024, 256, 2)]), Block( 'block4', bottleneck, [(2048, 512, 1)] * 3)] return resnet_v2(inputs, blocks, num_classes, global_pool, include_root_block=True, reuse=reuse, scope=scope) def resnet_v2_152(inputs, # unit提升的主要場所是block3 num_classes=None, global_pool=True, reuse=None, scope='resnet_v2_152'): """ResNet-152 model of [1]. See resnet_v2() for arg and return description.""" blocks = [ Block( 'block1', bottleneck, [(256, 64, 1)] * 2 + [(256, 64, 2)]), Block( 'block2', bottleneck, [(512, 128, 1)] * 7 + [(512, 128, 2)]), Block( 'block3', bottleneck, [(1024, 256, 1)] * 35 + [(1024, 256, 2)]), Block( 'block4', bottleneck, [(2048, 512, 1)] * 3)] return resnet_v2(inputs, blocks, num_classes, global_pool, include_root_block=True, reuse=reuse, scope=scope) def resnet_v2_200(inputs, # unit提升的主要場所是block2 num_classes=None, global_pool=True, reuse=None, scope='resnet_v2_200'): """ResNet-200 model of [2]. See resnet_v2() for arg and return description.""" blocks = [ Block( 'block1', bottleneck, [(256, 64, 1)] * 2 + [(256, 64, 2)]), Block( 'block2', bottleneck, [(512, 128, 1)] * 23 + [(512, 128, 2)]), Block( 'block3', bottleneck, [(1024, 256, 1)] * 35 + [(1024, 256, 2)]), Block( 'block4', bottleneck, [(2048, 512, 1)] * 3)] return resnet_v2(inputs, blocks, num_classes, global_pool, include_root_block=True, reuse=reuse, scope=scope) from datetime import datetime import math import time #-------------------評測函式--------------------------------- # 測試152層深的ResNet的forward效能 def time_tensorflow_run(session, target, info_string): num_steps_burn_in = 10 total_duration = 0.0 total_duration_squared = 0.0 for i in range(num_batches + num_steps_burn_in): start_time = time.time() _ = session.run(target) duration = time.time() - start_time if i >= num_steps_burn_in: if not i % 10: print ('%s: step %d, duration = %.3f' % (datetime.now(), i - num_steps_burn_in, duration)) total_duration += duration total_duration_squared += duration * duration mn = total_duration / num_batches vr = total_duration_squared / num_batches - mn * mn sd = math.sqrt(vr) print ('%s: %s across %d steps, %.3f +/- %.3f sec / batch' % (datetime.now(), info_string, num_batches, mn, sd)) batch_size = 32 height, width = 224, 224 inputs = tf.random_uniform((batch_size, height, width, 3)) with slim.arg_scope(resnet_arg_scope(is_training=False)): # is_training設定為false net, end_points = resnet_v2_152(inputs, 1000) init = tf.global_variables_initializer() sess = tf.Session() sess.run(init) num_batches=100 time_tensorflow_run(sess, net, "Forward") # forward計算耗時相比VGGNet和Inception V3大概只增加了50%,是一個實用的卷積神經網路。
跑的太慢了先來個截圖: