
布隆過濾器(Bloom Filter)原理以及應用
布隆過濾器(Bloom Filter)是1970年由布隆提出的。它實際上是一個很長的二進位制向量和一系列隨機對映函式。布隆過濾器可以用於檢索一個元素是否在一個集合中。它的優點是空間效率和查詢時間都遠遠超過一般的演算法,缺點是有一定的誤識別率和刪除困難。
hash原理
Hash (雜湊,或者雜湊)函式在計算機領域,尤其是資料快速查詢領域,加密領域用的極廣。
其作用是將一個大的資料集對映到一個小的資料集上面(這些小的資料集叫做雜湊值,或者雜湊值)。
一個應用是Hash table(散列表,也叫雜湊表),是根據雜湊值 (Key value) 而直接進行訪問的資料結構。也就是說,它通過把雜湊值對映到表中一個位置來訪問記錄,以加快查詢的速度。下面是一個典型的 hash 函式 / 表示意圖:
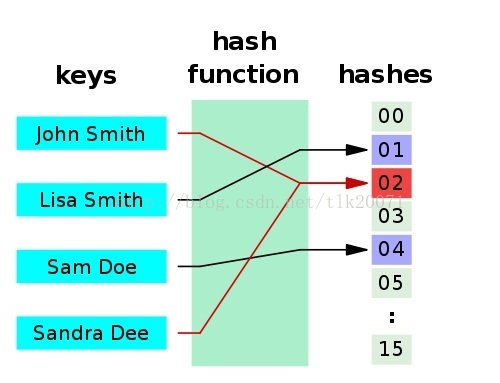
雜湊函式有以下兩個特點:
- 如果兩個雜湊值是不相同的(根據同一函式),那麼這兩個雜湊值的原始輸入也是不相同的。
- 雜湊函式的輸入和輸出不是唯一對應關係的,如果兩個雜湊值相同,兩個輸入值很可能是相同的。但也可能不同,這種情況稱為 “雜湊碰撞”(或者 “雜湊衝突”)。
缺點: 引用吳軍博士的《數學之美》中所言,雜湊表的空間效率還是不夠高。如果用雜湊表儲存一億個垃圾郵件地址,每個email地址 對應 8bytes, 而雜湊表的儲存效率一般只有50%,因此一個email地址需要佔用16bytes. 因此一億個email地址佔用1.6GB,如果儲存幾十億個email address則需要上百GB的記憶體。除非是超級計算機,一般的伺服器是無法儲存的。
所以要引入下面的 Bloom Filter。
布隆過濾器原理
如果想判斷一個元素是不是在一個集合裡,一般想到的是將集合中所有元素儲存起來,然後通過比較確定。連結串列、樹、散列表(又叫雜湊表,Hash table)等等資料結構都是這種思路。但是隨著集合中元素的增加,我們需要的儲存空間越來越大。同時檢索速度也越來越慢。
Bloom Filter 是一種空間效率很高的隨機資料結構,Bloom filter 可以看做是對 bit-map 的擴充套件, 它的原理是:
當一個元素被加入集合時,通過 K 個 Hash 函式將這個元素對映成一個位陣列(Bit array)中的 K 個點,把它們置為 1
- 如果這些點有任何一個 0,則被檢索元素一定不在;
- 如果都是 1,則被檢索元素很可能在。
布隆過濾器優點
它的優點是空間效率和查詢時間都遠遠超過一般的演算法,布隆過濾器儲存空間和插入 / 查詢時間都是常數O(k)。另外, 雜湊函式相互之間沒有關係,方便由硬體並行實現。布隆過濾器不需要儲存元素本身,在某些對保密要求非常嚴格的場合有優勢。
布隆過濾器缺點
但是布隆過濾器的缺點和優點一樣明顯。誤算率是其中之一。隨著存入的元素數量增加,誤算率隨之增加。但是如果元素數量太少,則使用散列表足矣。
(誤判補救方法是:再建立一個小的白名單,儲存那些可能被誤判的資訊。)
另外,一般情況下不能從布隆過濾器中刪除元素. 我們很容易想到把位陣列變成整數陣列,每插入一個元素相應的計數器加 1, 這樣刪除元素時將計數器減掉就可以了。然而要保證安全地刪除元素並非如此簡單。首先我們必須保證刪除的元素的確在布隆過濾器裡面. 這一點單憑這個過濾器是無法保證的。另外計數器迴繞也會造成問題。(google guava實現的布隆過濾器裡面就沒有包含刪除元素)
google guava實現的布隆過濾器簡單使用
場景描述:100W個字串資訊放入到布隆過濾器,另外隨機生成1W個字串,判斷他們在100W裡面是否存在
-
<dependency> -
<groupId>com.google.guava</groupId> -
<artifactId>guava</artifactId> -
<version>19.0</version> -
</dependency>
-
package com.tlk.guava; -
import java.util.ArrayList; -
import java.util.HashSet; -
import java.util.List; -
import java.util.Set; -
import java.util.UUID; -
import com.google.common.base.Charsets; -
import com.google.common.hash.BloomFilter; -
import com.google.common.hash.Funnels; -
/** -
* google guava 布隆過濾器的使用 -
* -
* @author tanlk 2017年10月24日 下午11:44:16 -
*/ -
public class BloomFilterTest { -
private static final int insertions = 1000000;// 100萬 -
public static void main(String[] args) { -
// 初始化一個儲存string資料的布隆過濾器,預設fpp(誤差率) 0.03 -
BloomFilter<String> bf = BloomFilter.create(Funnels.stringFunnel(Charsets.UTF_8), insertions); -
Set<String> set = new HashSet<String>(insertions); -
List<String> list = new ArrayList<String>(insertions); -
for (int i = 0; i < insertions; i++) { -
String uuid = UUID.randomUUID().toString(); -
bf.put(uuid); -
set.add(uuid); -
list.add(uuid); -
} -
int wrong = 0; // 布隆過濾器誤判的次數 -
int right = 0;// 布隆過濾器正確次數 -
for (int i = 0; i < 10000; i++) { -
String str = i % 100 == 0 ? list.get(i / 100) : UUID.randomUUID().toString(); -
if (bf.mightContain(str)) { -
if (set.contains(str)) { -
right++; -
} else { -
wrong++; -
} -
} -
} -
//right 為100 -
System.out.println("right:" + right); -
//因為誤差率為3%,所以一萬條資料wrong的值在300左右 -
System.out.println("wrong:" + wrong); -
} -
}
布隆過濾器的應用場景
1.Google著名的分散式資料庫Bigtable以及Hbase使用了布隆過濾器來查詢不存在的行或列,以減少磁碟查詢的IO次數。
2.檢查垃圾郵件地址
假定我們儲存一億個電子郵件地址,我們先建立一個十六億二進位制(位元),即兩億位元組的向量,然後將這十六億個二進位制全部設定為零。對於每一個電子郵件地址 X,我們用八個不同的隨機數產生器(F1,F2, ...,F8) 產生八個資訊指紋(f1, f2, ..., f8)。再用一個隨機數產生器 G 把這八個資訊指紋對映到 1 到十六億中的八個自然數 g1, g2, ...,g8。現在我們把這八個位置的二進位制全部設定為一。當我們對這一億個 email 地址都進行這樣的處理後。一個針對這些 email 地址的布隆過濾器就建成了。
3.Google chrome 瀏覽器使用bloom filter識別惡意連結(能夠用較少的儲存空間表示較大的資料集合,簡單的想就是把每一個URL都可以對映成為一個bit)
4.文件儲存檢索系統也採用布隆過濾器來檢測先前儲存的資料
5.爬蟲URL地址去重
A,B 兩個檔案,各存放 50 億條 URL,每條 URL 佔用 64 位元組,記憶體限制是 4G,讓你找出 A,B 檔案共同的 URL。如果是三個乃至 n 個檔案呢? 分析 :如果允許有一定的錯誤率,可以使用 Bloom filter,4G 記憶體大概可以表示 340 億 bit。將其中一個檔案中的 url 使用 Bloom filter 對映為這 340 億 bit,然後挨個讀取另外一個檔案的 url,檢查是否與 Bloom filter,如果是,那麼該 url 應該是共同的 url(注意會有一定的錯誤率)。
6.解決快取穿透問題
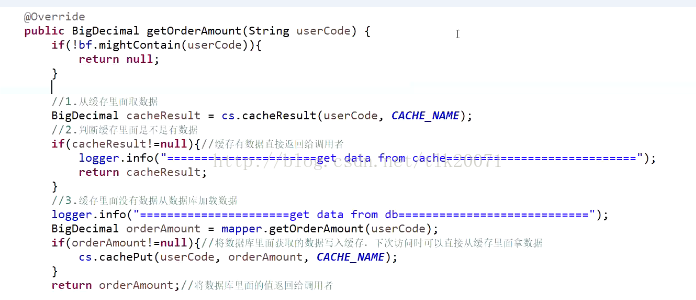
快取穿透是指查詢一個一定不存在的資料,由於快取是不命中時被動寫的,並且出於容錯考慮,如果從儲存層查不到資料則不寫入快取,這將導致這個不存在的資料每次請求都要到儲存層去查詢,失去了快取的意義。在流量大時,可能DB就掛掉了,要是有人利用不存在的key頻繁攻擊我們的應用,這就是漏洞。
虛擬碼如下:

轉自: