
Tensorflow學習——利用Object Detection api訓練自己的資料集
環境:Windows 10+tensorflow-gpu-1.6.0
前期準備:完成Object Detection api配置
檔案目錄結構
├─Annotation│ └─XML檔案
├─data
│ ├─csv檔案
│ └─Record檔案
├─images
│ └─圖片
├─eval
│ └─測試集結果
├─training
│ ├─pbtxt檔案
│ ├─config檔案
│ └─model.ckpt檔案
├─model
│ └─輸出模型
一、準備圖片
利用labelImg擷取圖片中的物件並新增標籤,生成XML檔案儲存在Annotation目錄下,注意檔案命名與圖片對應同時命名遵從以一定規律。
labelImg下載地址:https://github.com/tzutalin/labelImg/releases
批量命名可參考下面命令,用法cd到當前目錄並執行:
@echo off&setlocal EnableDelayedExpansion
set a=1
for /f "delims=" %%i in ('dir /b *.jpg') do (
if not "%%~ni"=="%~n0" (
ren "%%i" "20180609(data)!a!.jpg"
set/a a+=1
)
)二、xml轉換到csv
因在製作用於訓練的.record格式檔案時用到的是csv格式檔案,所以需要將xml轉換到csv,轉換可以通過下面的python程式處理,其中程式中的xml_df = xml_to_csv(image_path) image_path為xml目錄路徑,生成的csv檔案預設儲存在程式目錄下。
import os import glob import pandas as pd import xml.etree.ElementTree as ET def xml_to_csv(path): xml_list = [] for xml_file in glob.glob(path + '/*.xml'): tree = ET.parse(xml_file) root = tree.getroot() for member in root.findall('object'): value = (root.find('filename').text, int(root.find('size')[0].text), int(root.find('size')[1].text), member[0].text, int(member[4][0].text), int(member[4][1].text), int(member[4][2].text), int(member[4][3].text) ) xml_list.append(value) column_name = ['filename', 'width', 'height', 'class', 'xmin', 'ymin', 'xmax', 'ymax'] xml_df = pd.DataFrame(xml_list, columns=column_name) return xml_df def main(): image_path = os.path.join(os.getcwd(), 'annotations') xml_df = xml_to_csv(image_path) xml_df.to_csv('raccoon_labels.csv', index=None) print('Successfully converted xml to csv.') main()
三、資料集整理

在使用資料集進行訓練前需將資料集分為訓練集和測試集。訓練集的作用在於訓練模型,測試集的作用在於測試訓練後模型,對資料集分離的目的在於避免產生過擬合使得訓練出來的模型難以泛化到新的資料,兩者的比例一般為9:1,可根據實際進行調整。
訓練集 - 用於訓練模型的子集。
測試集 - 用於測試訓練後模型的子集。
四、生成tfrecord格式檔案
官方在教程中提供了生成自己的tfrecord格式檔案,參考其方法及國外論壇的資料,編寫generate_tfrecord.py用於生成自己的tfrecord格式檔案,其中#TO-DO replace this with label map下的內容需要根據自己的資料集進行修改,修改為自己資料集的標籤。
"""
Usage:
# From tensorflow/models/
# Create train data:
python generate_tfrecord.py --csv_input=data/train_labels.csv --output_path=train.record
# Create test data:
python generate_tfrecord.py --csv_input=data/test_labels.csv --output_path=test.record
"""
from __future__ import division
from __future__ import print_function
from __future__ import absolute_import
import os
import io
import pandas as pd
import tensorflow as tf
from PIL import Image
from object_detection.utils import dataset_util
from collections import namedtuple, OrderedDict
flags = tf.app.flags
flags.DEFINE_string('csv_input', '', 'Path to the CSV input')
flags.DEFINE_string('output_path', '', 'Path to output TFRecord')
FLAGS = flags.FLAGS
# TO-DO replace this with label map
def class_text_to_int(row_label):
if row_label == 'cola':
return 1
elif row_label == 'milk':
return 2
else:
None
def split(df, group):
data = namedtuple('data', ['filename', 'object'])
gb = df.groupby(group)
return [data(filename, gb.get_group(x)) for filename, x in zip(gb.groups.keys(), gb.groups)]
def create_tf_example(group, path):
with tf.gfile.GFile(os.path.join(path, '{}'.format(group.filename)), 'rb') as fid:
encoded_jpg = fid.read()
encoded_jpg_io = io.BytesIO(encoded_jpg)
image = Image.open(encoded_jpg_io)
width, height = image.size
filename = group.filename.encode('utf8')
image_format = b'jpg'
xmins = []
xmaxs = []
ymins = []
ymaxs = []
classes_text = []
classes = []
for index, row in group.object.iterrows():
xmins.append(row['xmin'] / width)
xmaxs.append(row['xmax'] / width)
ymins.append(row['ymin'] / height)
ymaxs.append(row['ymax'] / height)
classes_text.append(row['class'].encode('utf8'))
classes.append(class_text_to_int(row['class']))
tf_example = tf.train.Example(features=tf.train.Features(feature={
'image/height': dataset_util.int64_feature(height),
'image/width': dataset_util.int64_feature(width),
'image/filename': dataset_util.bytes_feature(filename),
'image/source_id': dataset_util.bytes_feature(filename),
'image/encoded': dataset_util.bytes_feature(encoded_jpg),
'image/format': dataset_util.bytes_feature(image_format),
'image/object/bbox/xmin': dataset_util.float_list_feature(xmins),
'image/object/bbox/xmax': dataset_util.float_list_feature(xmaxs),
'image/object/bbox/ymin': dataset_util.float_list_feature(ymins),
'image/object/bbox/ymax': dataset_util.float_list_feature(ymaxs),
'image/object/class/text': dataset_util.bytes_list_feature(classes_text),
'image/object/class/label': dataset_util.int64_list_feature(classes),
}))
return tf_example
def main(_):
writer = tf.python_io.TFRecordWriter(FLAGS.output_path)
path = os.path.join(os.getcwd(), 'images')
examples = pd.read_csv(FLAGS.csv_input)
grouped = split(examples, 'filename')
for group in grouped:
tf_example = create_tf_example(group, path)
writer.write(tf_example.SerializeToString())
writer.close()
output_path = os.path.join(os.getcwd(), FLAGS.output_path)
print('Successfully created the TFRecords: {}'.format(output_path))
if __name__ == '__main__':
tf.app.run()執行格式如下,預設圖片在當前資料夾images檔案下。
python generate_tfrecord.py --csv_input=csv檔案路徑
--output_path=輸出record檔名字(**.record)五、準備訓練檔案
1、.pbtxt檔案,檔案內容根據標籤確定。
item {
id: 1
name: 'cola'
}
item {
id: 2
name: 'milk'
}
2、model.ckpt檔案為訓練模型,一般採用預訓練模型,可降低訓練所需時間,根據實際需求選擇適合自己的模型,下載完成後解壓,將名字帶有model.ckpt的三個檔案移動到training目錄下。
各種模型下載連結:
https://github.com/tensorflow/models/blob/master/research/object_detection/g3doc/detection_model_zoo.md
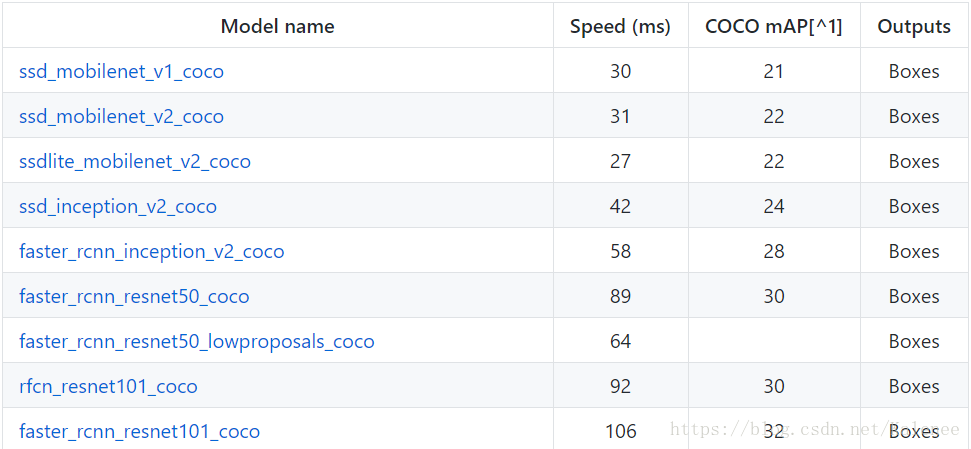
3、.config檔案在目錄models-master\research\object_detection\samples\configs下選擇,根據選擇的預訓練模型選擇對應.config檔案,同時修改檔案中路徑為對應目錄
fine_tune_checkpoint: "../training/model.ckpt"
train_input_reader: {
tf_record_input_reader {
input_path: "../data/train.record"
}
label_map_path: "../training/*.pbtxt"
}
eval_input_reader: {
tf_record_input_reader {
input_path: "../data/eval.record"
}
label_map_path: "../training/*.pbtxt"同時根據硬體條件選定合適的批次(batch_size)和初始學習速率(initial_learning_rate)。
批次(batch)是每一次迭代中模型訓練使用的樣本集,批次規模(batch_size)為一個批次中的樣本數量。一般情況下對於小資料集批次規模越大越好,這樣可以提高計算的速度和效率,同時降低訓練震盪,若資料集足夠小,可採用全資料集的形式進行訓練,但這種情況容易造成計算量增長過大導致溢位,因此批次規模的大小需根據實際情況進行設定。
學習速率(learning rate)是在訓練模型過程中用於梯度下降的一個變數,在訓練過程中,每次迭代梯度下降法都會將學習速率與梯度相乘,因此其值是隨著訓練進行不斷變化。而初始學習速率(initial_learning rate)是模型開始訓練前設定的最開始的學習速率,在訓練過程中,模型會根據學習率變化策略以初始學習速率為起點設定學習速率,初始學習速率一般情況下應設定為一個較小的值,然後在之後訓練過程中逐步調大。
train_config: {
batch_size: 6
optimizer {
rms_prop_optimizer: {
learning_rate: {
exponential_decay_learning_rate {
initial_learning_rate: 0.004
decay_steps: 800720
decay_factor: 0.95
}
}
momentum_optimizer_value: 0.9
decay: 0.9
epsilon: 1.0
}
}六、訓練模型
建議:windows環境下建議採用git base
訓練所用python檔案都在..\models-master\research\object_detection目錄下,可複製到資料集資料夾中,執行時需cd到python檔案路徑下。
模型訓練命令,訓練結果保存於training目錄下。
python train.py \
--logtostderr \
--pipeline_config_path=${定義的Config} \
--train_dir=${訓練結果要存放的目錄}監視訓練狀況命令,建議cd 到training目錄上一級然後執行,執行後將視窗中顯示的連結複製到瀏覽器位址列。
tensorboard --logdir=training模型驗證命令,輸出結果保存於eval目錄下。
python eval.py \
--logtostderr \
--pipeline_config_path=${定義的Config} \
--checkpoint_dir=${訓練結果存放的目錄}
--eval_dir=${輸出結果目錄}
模型驗證視覺化命令,建議cd 到eval目錄上一級然後執行
tensorboard --logdir=eval七、模型匯出
模型匯出命令,model.ckpt需選定training目錄下其中一個model.ckpt,因為在訓練過程中,程式會定期進行儲存,路徑建議採用絕對路徑。
python export_inference_graph.py \
--input_type image_tensor
--pipeline_config_path config檔案path \
--trained_checkpoint_prefix model.ckpt-*檔案path \
--output_directory 輸出結果路徑
在output_directory路徑下會生成三個檔案:
frozen_inference_graph.pb、model.ckpt.data-00000-of-00001、model.ckpt.meta、model.ckpt.data
參考資料
https://developers.google.com/machine-learning/crash-course/prereqs-and-prework