
Stanford 224N- GloVe: Global Vectors for word representations
Window based method (direct predict method): skip gram and CBOW
Skip-gram Model:
take one window at a time,
predict probability of surrrounding words(with existing v and u matrix) 在每個視窗中做SGD
7分鐘
大部分目標函式都是非凸的(not convex),因此初始化很重要;要知道避免陷入區域性最優的技巧:使用小隨機數初始化
SGD更新梯度,sparse matrix,實際上對比的只有視窗中的詞語,其他均為0
對於每個視窗,分母需要做20000次(整個語料庫的)內積運算? 10分30秒
not efficient: 很多詞如 aardvark 和 zebra 並不同時出現,為什麼不只看一個視窗內的??
solution:train binary logistic regressions for true pairs (v and u match pair) vs. noise pairs (v paired with a random word)
正樣本 負樣本
Word2vec package保留了分子中心詞與外圍詞作內積的想法,
分母變為:從語料庫中隨機抽取幾個單詞(k negative samples,10數量級),minimize their prob of co-occuring(出現在中心詞周圍的概率) to be used as a sum prob
而不是遍歷所有不同的單詞:在分母中只使用高頻詞彙的內積和

改進的目標函式算式:見ipad筆記
另一個模型:
Continuous bag of words (CBOW):
Predict the center word from the sum of the surrounding words (instead of predict surrounding words)
what actually happens:
objective functions, take gradients, they cluster similar meanings around in space (PCA visualization)
Go through each word in corpus, try to predict the surrounding words in window
核心為抓取詞與詞共同出現的頻率
Count based method
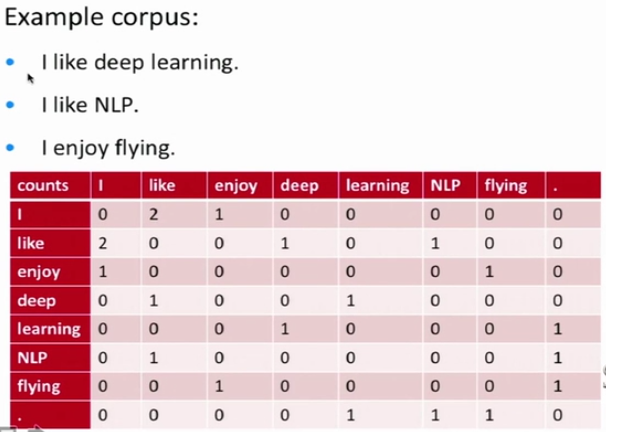
Example: small corpus -> windows -> compute word vectors
Window based co-occurrence matrices (共現頻率計數)
Symmetric window (length 1)
切換到svd分解共現矩陣???
不能真正將上表的行用成word vector: increase in size; high demensional for every word count
部分解決方案:只儲存最重要的資訊 in a fixed dimension
How to reduce dimentionality from the co-currence matrices ?
SVD (Singlar Value Decomposition)
Simple Python Code to visualize words (dimensionality reduction instead of projecting to 2D)
maximize the count at 100 or ignore a couple of very frequent words (like 'the') or 給予window不同位置的詞不同權重
很多重新處理共現矩陣的辦法,SVD superisingly works 效果很好
基於計數的方法在中小規模語料訓練很快,有效地利用了統計資訊,可視化出詞與詞之間的關係。
而預測模型必須遍歷所有的視窗進行訓練,無法有效利用單詞的全域性統計資訊
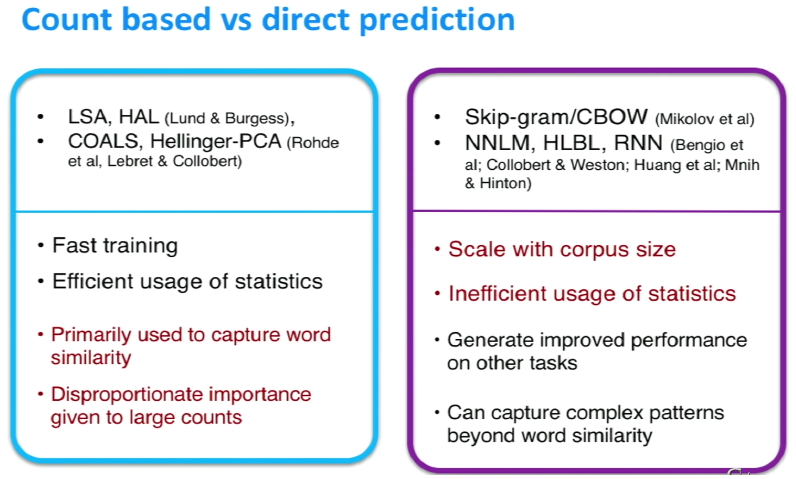
綜合兩者的優勢:GloVe 模型 Global Vectors Model
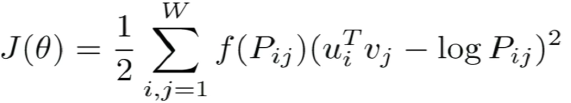
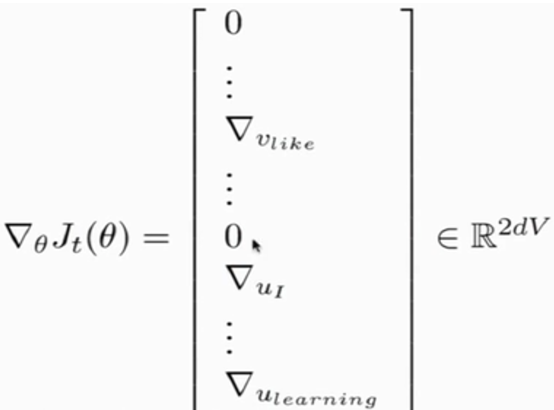
X final (vector) = U + V (vectors in column/row, 中心詞還是上下文詞)

Polysemy一詞多義
Word vectors encode similarity + Polysemy

- Polysemous vectors are superpositioned
tie-1, tie-2, tie-3 -> final combination
- Senses can be recovered by sparse coding (+ noise ) How to decomposition this vector afterwards?

How to evaluate word vectors?
For these hyperparameters. whether inner products correlate with human judgements of similarity (1 to 10, how similar)
How vector distances correlate with these human judgements. GloVe did the best!
Intrinsic evaluations:
在某個資料集上由人工標註詞語或句子相似度與模型結果對比,但可能實際上並沒有多少提高效果
on a specific subtask
fast to compute, understand how your system works
Extrinsic evaluations:
通過對外部實際應用的效果提升來體現,耗時較長
用 Pearson 相關係數替代詞頻計數,表示相關強度
take a long time to train
Word Vector cosine distance: capture semantic and syntactic analogies類比
(Semantic: man to woman, king to ? Sytactic: slow, slower, slowest) through Euclidean subtractions
無數學證明
各模型結果對比:
High dimension vector 表現並不一定好;資料越多越好
Sometimes depend on the data quality (like wikipedia is a very good dataset!)
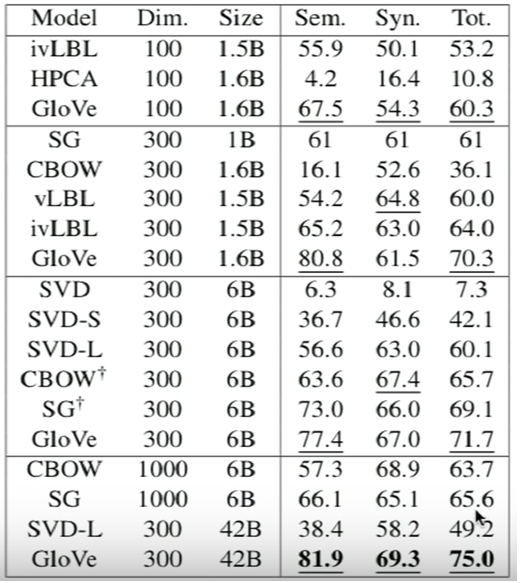
這些模型都屬於Word2Vec嗎?? Word2Vec就是Skip-Gram?
調參:How to choose these hyperparameters (plot accuracy vs. parameters change)
- Symmetric windows work better
- Dimensionality works well after 200 (accuracy flat between 300 to 600)
- Window size: about 8 (left, right) is the best
GloVe computes all the counts and then works on the counts
Skip-Gram goes one window at a time
Glove did better, 且迭代次數越多越好
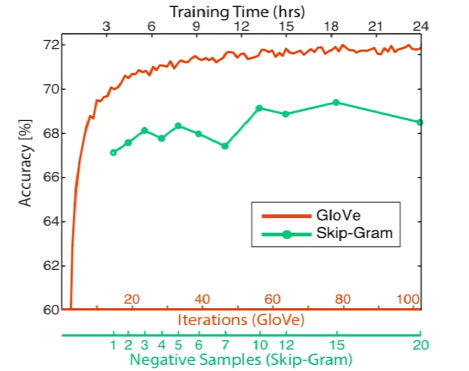
Expensive but best kinds of evaluations are extrinsic evaluations on real task
(NER task is good for that, sentiment analysis is bad, different sentiment can appear on same position)!
Simple single word classification
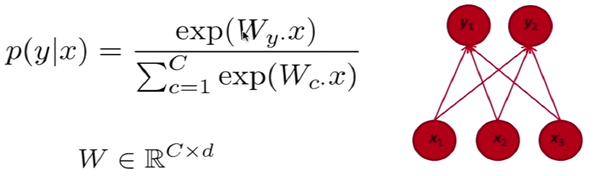
given word vector x, is it belong to class y or not (classification)?