
【論文閱讀】《GloVe: Global Vectors forWord Representation》
阿新 • • 發佈:2018-12-28
GloVe model
單詞表示模型:GloVe,用於全域性向量,全域性語料的統計資訊直接由模型獲得。
符號
:詞共現矩陣
:單詞
出現在單詞
的上下文中的次數。
:所有出現在單詞
的上下文中的單詞次數。
:單詞
出現在單詞
的上下文中的概率。
舉例:
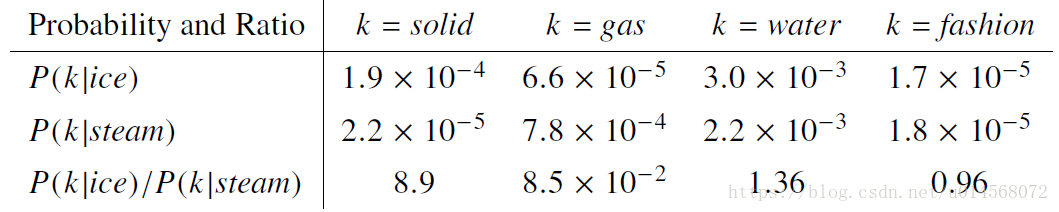
通過觀察圖中的比率(第三行)可以看出,當結果大於1時,單詞 與ice更相關,當結果小於1時,單詞 與steam更相關。
上述論點表明,單詞向量學習的適當起點應該是共現概率的比率而不是概率本身。其中,比率 取決於單詞 、 、 ,我們採用最通用的模型形式:
其中,
表示單詞向量,
表示單個的上下文詞向量。
對於F的選擇,由於向量空間本質上是線性結構,因此最自然的方法是使用向量差異。通過僅考慮兩個目標詞的差異可以修改為:
採用引數點積來防止 函式以不和需要的方式進行向量維度混合:
對於單詞共現矩陣,單詞和上下文單詞之間的區別是任意的,我們可以自由地交換這兩個角色。我們的最終模型在這種重新標記下應該是不變的,因此我們通過兩步驟來回復對稱性。
首先要求
函式在
和
之間應該是同態的。