
BiLSTM+CRF(二)命名實體識別
前言
前一篇部落格裡面,我們已經提到了如何構建一個雙向的LSTM網路,並在原來單層的RNN的基礎上,修改少數幾行程式碼即可實現。
Bi-LSTM其實就是兩個LSTM,只不過反向的LSTM是把輸入的資料先reverse 首尾轉置一下,然後跑一個正常的LSTM,然後再把輸出結果reverse一次使得與正向的LSTM的輸入對應起來。
這篇部落格,我們就來看看如何通過BiLSTM+CRF來進行命名實體識別的任務。
先介紹一下命名實體識別任務。
命名實體識別
通俗來說,命名實體識別,就是給一句話或一段話,設計某種演算法來把其中的命名實體給找出來。啥叫命名實體呢?說白了不值一提,命名實體,其實就是實際存在的具有專門名字的物體。命名實體識別,其實就是實體名字的識別。
例如:
我 們 的 藏 品 中 有 幾 十 冊 為 北 京 圖 書 館 等 國 家 級 藏 館 所 未 藏 。
其中北京圖書館就是一個專有的實體名稱。
一般命名實體有分:人名、地名、組織名、機構名等等之分,根據不同的任務有不同的劃分。
命名實體識別的解法
目前命名實體識別領域比較流行的方法都是把命名實體識別問題轉換為一個序列標註的問題,然後通過序列標註的方法來解決。
一般序列標註的解決方法有:隱馬爾科夫模型HMM或 條件隨機場 CRF 或BiLSTM+CRF 或BiLSTM+最大熵。其中前兩種是統計學習方法,後面兩種是神經網路的方法。
本文只介紹神經網路的方法。
當把命名實體識別轉換為一個序列標註的問題後,問題就簡化成了一個結構化分類的問題了。
什麼意思呢?例如,對於人名識別的任務來說,我們把每個字分類為三類:O,B-PER,I-PER。O表示這個字不是人名,B-PER表示這個字是一個人名的開頭,I-PER表示這個字是一個人名的中間,前面一定存在一個最近的B-PER使得從B-PER到I-PER形成的連續子串構成一個人名。
例如:
尤 以 收 錄 周 恩 來 總 理 、 馬 駿 烈 士 的 《 南 開 中 學 同 學 錄 》
標註語料:
O O O O B-PER I-PER I-PER O O O B-PER I-PER O O O O
其中“周恩來”是一個人名,於是這三個詞被標註為B-PER I-PER I-PER。
同理“馬駿”也是一個人名。
做了這個處理以後,這個任務就簡單的多了。
很明顯,這是一個有監督的分類問題,訓練語料一定要給出訓練文字對應的標註。基於訓練集,自然也就能學習到一個分類模型。
Bi-LSTM+最大熵 解法
Bi-LSTM+最大熵 解法是特別簡單粗暴的一種解法,它的核心思想是通過一個Bi-LSTM計算得到某個詞標註為各類標籤的勢能(其實就可以理解為概率)分佈,然後取這些標籤裡面,勢能最大的那個標籤作為分類結果輸出。
這種方法很簡單,實現也方便。但是這種方法把各個詞的標註結果獨立開來,過度“相信”神經網路會自己學到詞的標註結果之間的某種關係。
例如:
如果存在一個這樣一個標註序列:B-PER,I-LOC,I-LOC,I-LOC
自然是不合理的。
經典模型:
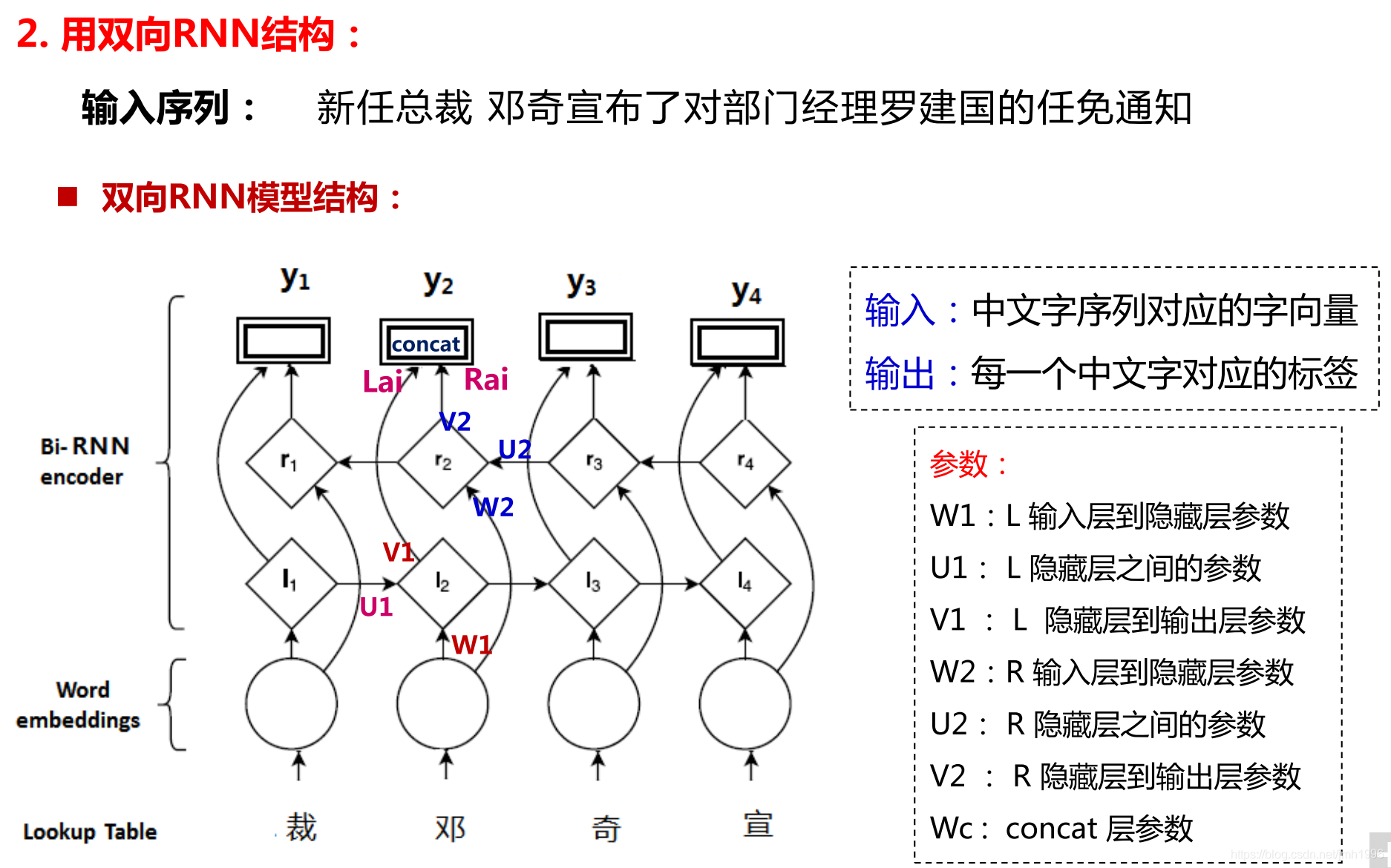
Bi-LSMT+CRF 解法
Bi-LSTM +CRF是在原來的Bi-LSTM+最大熵的基礎上優化過來的,它最大的思想就是在Bi-LSTM的上面掛了一層條件隨機場模型作為模型的解碼層,在條件隨機場模型裡面考慮預測結果之間的合理性。
經典模型:
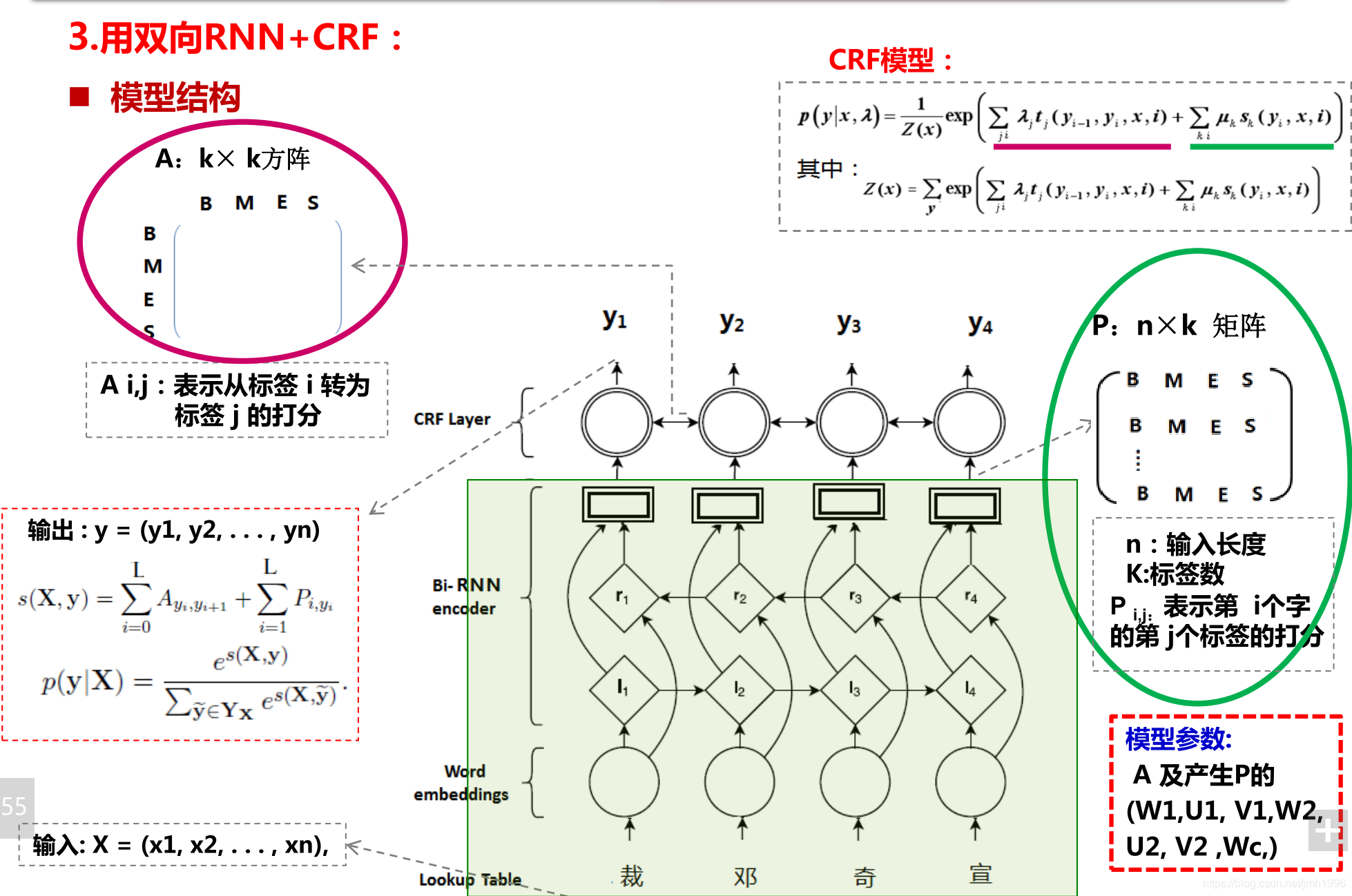
Bi-LSTM+CRF 模型的實現
模型:CRF的轉移矩陣A由神經網路的CRF層近似得到,而P矩陣 也就是發射矩陣由Bi-LSTM近似得到。
詞向量,即可以預先訓練,也可以一併訓練。
實現詳解
資料處理邏輯
__author__ = 'jmh081701'
import json
import numpy as np
import random
class DATAPROCESS:
def __init__(self,train_data_path,train_label_path,test_data_path,test_label_path,word_embedings_path,vocb_path,seperate_rate=0.1,batch_size=100,
state={'O':0,'B-LOC':1,'I-LOC':2,'B-PER':3,'I-PER':4,'B-ORG':5,'I-ORG':6}):
self.train_data_path =train_data_path
self.train_label_path =train_label_path
self.test_data_path = test_data_path
self.test_label_path = test_label_path
self.word_embedding_path = word_embedings_path
self.vocb_path = vocb_path
self.state = state
self.seperate_rate =seperate_rate
self.batch_size = batch_size
self.sentence_length = 20
#data structure to build
self.train_data_raw=[]
self.train_label_raw =[]
self.valid_data_raw=[]
self.valid_label_raw = []
self.test_data_raw =[]
self.test_label_raw =[]
self.word_embeddings=None
self.id2word=None
self.word2id=None
self.embedding_length =0
self.__load_wordebedding()
self.__load_train_data()
#self.__load_test_data()
self.last_batch=0
def __load_wordebedding(self):
self.word_embeddings=np.load(self.word_embedding_path)
self.embedding_length = np.shape(self.word_embeddings)[-1]
with open(self.vocb_path,encoding="utf8") as fp:
self.id2word = json.load(fp)
self.word2id={}
for each in self.id2word:
self.word2id.setdefault(self.id2word[each],each)
def __load_train_data(self):
with open(self.train_data_path,encoding='utf8') as fp:
train_data_rawlines=fp.readlines()
with open(self.train_label_path,encoding='utf8') as fp:
train_label_rawlines=fp.readlines()
total_lines = len(train_data_rawlines)
assert len(train_data_rawlines)==len(train_label_rawlines)
for index in range(total_lines):
data_line = train_data_rawlines[index].split(" ")[:-1]
label_line = train_label_rawlines[index].split(" ")[:-1]
#assert len(data_line)==len(label_line)
#align
if len(data_line) < len(label_line):
label_line=label_line[:len(data_line)]
elif len(data_line)>len(label_line):
data_line=data_line[:len(label_line)]
assert len(data_line)==len(label_line)
#add and seperate valid ,train set.
data=[int(self.word2id.get(each,0)) for each in data_line]
label=[int(self.state.get(each,self.state['O'])) for each in label_line]
if random.uniform(0,1) <self.seperate_rate:
# 按照一定的比例劃分
self.valid_data_raw.append(data)
self.valid_label_raw.append(label)
else:
self.train_data_raw.append(data)
self.train_label_raw.append(label)
self.train_batches= [i for i in range(int(len(self.train_data_raw)/self.batch_size) -1)]
self.train_batch_index =0
self.valid_batches=[i for i in range(int(len(self.valid_data_raw)/self.batch_size) -1) ]
self.valid_batch_index = 0
def __load_test_data(self):
pass
def pad_sequence(self,sequence,object_length,pad_value=None):
'''
:param sequence: 待填充的序列
:param object_length: 填充的目標長度
:return:
'''
if pad_value is None:
sequence = sequence*(1+int((0.5+object_length)/(len(sequence))))
sequence = sequence[:object_length]
else:
sequence = sequence+[pad_value]*(object_length- len(sequence))
return sequence
def next_train_batch(self):
#padding
output_x=[]
output_label=[]
index =self.train_batches[self.train_batch_index]
self.train_batch_index =(self.train_batch_index +1 ) % len(self.train_batches)
datas = self.train_data_raw[index*self.batch_size:(index+1)*self.batch_size]
labels = self.train_label_raw[index*self.batch_size:(index+1)*self.batch_size]
for index in range(self.batch_size):
#複製填充
data= self.pad_sequence(datas[index],self.sentence_length)
label = self.pad_sequence(labels[index],self.sentence_length)
output_x.append(data)
output_label.append(label)
return output_x,output_label
#返回的都是下標
def next_test_batch(self):
pass
def next_valid_batch(self):
output_x=[]
output_label=[]
index =self.valid_batches[self.valid_batch_index]
self.valid_batch_index =(self.valid_batch_index +1 ) % len(self.valid_batches)
datas = self.valid_data_raw[index*self.batch_size:(index+1)*self.batch_size]
labels = self.valid_label_raw[index*self.batch_size:(index+1)*self.batch_size]
for index in range(self.batch_size):
#複製填充
data= self.pad_sequence(datas[index],self.sentence_length)
label = self.pad_sequence(labels[index],self.sentence_length)
output_x.append(data)
output_label.append(label)
return output_x,output_label
if __name__ == '__main__':
pass
資料處理模組主要是為了實現兩個函式:next_train_batch和next_valid_batch,用於從訓練集和預測集獲取一個batch的資料,注意這裡的batch不是隨機的,而是序慣的。
注意這裡面的pad 填充函式,它會把序列填充到給定的sentence_length的長度,填充方法是倍增填充。
神經網路模型
__author__ = 'jmh081701'
import tensorflow as tf
from tensorflow.contrib import crf
import random
from utils import *
#超引數
batch_size=300
dataGen = DATAPROCESS(train_data_path="data/source_data.txt",
train_label_path="data/source_label.txt",
test_data_path="data/test_data.txt",
test_label_path="data/test_label.txt",
word_embedings_path="data/source_data.txt.ebd.npy",
vocb_path="data/source_data.txt.vab",
batch_size=batch_size
)
#模型超引數
tag_nums =len(dataGen.state) #標籤數目
hidden_nums = 30 #bi-lstm的隱藏層單元數目
learning_rate = 0.0005 #學習速率
sentence_len = dataGen.sentence_length #句子長度,輸入到網路的序列長度
frame_size = dataGen.embedding_length #句子裡面每個詞的詞向量長度
#網路的變數
word_embeddings = tf.Variable(initial_value=dataGen.word_embeddings,trainable=True) #參與訓練
#輸入佔位符
input_x = tf.placeholder(dtype=tf.int32,shape=[None,None],name='input_word_id')#輸入詞的id
input_y = tf.placeholder(dtype=tf.int32,shape=[None,sentence_len],name='input_labels')
sequence_lengths=tf.placeholder(dtype=tf.int32,shape=[None],name='sequence_lengths_vector')
#
with tf.name_scope('projection'):
#投影層,先將輸入的詞投影成相應的詞向量
word_id = input_x
word_vectors = tf.nn.embedding_lookup(word_embeddings,ids=word_id,name='word_vectors')
word_vectors = tf.nn.dropout(word_vectors,0.8)
with tf.name_scope('bi-lstm'):
labels = tf.reshape(input_y,shape=[-1,sentence_len],name='labels')
fw_lstm_cell =tf.nn.rnn_cell.LSTMCell(hidden_nums)
bw_lstm_cell = tf.nn.rnn_cell.LSTMCell(hidden_nums)
#雙向傳播
output,_state = tf.nn.bidirectional_dynamic_rnn(fw_lstm_cell,bw_lstm_cell,inputs=word_vectors,sequence_length=sequence_lengths,dtype=tf.float32)
fw_output = output[0]#[batch_size,sentence_len,hidden_nums]
bw_output =output[1]#[batch_size,sentence_len,hidden_nums]
contact = tf.concat([fw_output,bw_output],-1,name='bi_lstm_concat')#[batch_size,sentence_len,2*hidden_nums]
contact = tf.nn.dropout(contact,0.9)
s=tf.shape(contact)
contact_reshape=tf.reshape(contact,shape=[-1,2*hidden_nums],name='contact')
W=tf.get_variable('W',dtype=tf.float32,initializer=tf.contrib.layers.xavier_initializer(),shape=[2*hidden_nums,tag_nums],trainable=True)
b=tf.get_variable('b',initializer=tf.zeros(shape=[tag_nums]))
p=tf.matmul(contact_reshape,W)+b
logit= tf.reshape(p,shape=[-1,s[1],tag_nums],name='omit_matrix')
with tf.name_scope("crf") :
log_likelihood,transition_matrix=crf.crf_log_likelihood(logit,labels,sequence_lengths=sequence_lengths)
cost = -tf.reduce_mean(log_likelihood)
with tf.name_scope("train-op"):
global_step = tf.Variable(0,name='global_step',trainable=False)
optim = tf.train.AdamOptimizer(learning_rate)
train_op=optim.minimize(cost)
#grads_and_vars = optim.compute_gradients(cost)
#grads_and_vars = [[tf.clip_by_value(g,-5,5),v] for g,v in grads_and_vars]
#train_op = optim.apply_gradients(grads_and_vars,global_step)
#
display_step = len(dataGen.train_batches)*10
max_batch = 10000
step=1
with tf.Session() as sess:
sess.run(tf.global_variables_initializer())
while step<max_batch:
batch_x,batch_y = dataGen.next_train_batch()
_,loss,score=sess.run([train_op,cost,logit],{input_x:batch_x,input_y:batch_y,sequence_lengths:[sentence_len]*batch_size})
print({'loss':loss,'step':step})
if(step % display_step ==0):
valid_x,valid_y=dataGen.next_valid_batch()
scores,transition_matrix_out=sess.run([logit,transition_matrix],{input_x:valid_x,input_y:valid_y,sequence_lengths:[sentence_len]*batch_size})
for i in range(batch_size):
label,_=crf.viterbi_decode(scores[i],transition_params=transition_matrix_out)
print(label)
step+=1
本人沒有寫 準確率函式。
命名實體識別的準確率是判斷標準答案裡面的命名實體集
,與預測的實體集
之間交集佔各自的比例。
一個巨大的坑
這個模型不難,但是卻讓我除錯了1個月,原來的模型實現中模型始終預測出"O",除錯中看了各個詞的發射概率scores ,發現"O"標籤的概率最大,讓人如何也想不出問題所在。
後來,在一個偶然的機會中,本人意識到一個問題:那就是dynamic_rnn函式的有一個引數sequence_length 是需要正確設定的。
tf.nn.bidirectional_dynamic_rnn(fw_lstm_cell,bw_lstm_cell,inputs=word_vectors,sequence_length=sequence_lengths,dtype=tf.float32)
之前對sequence_length理解不深,後面翻閱文件知道這個引數的含義是:
sequence_length: (optional) An int32/int64 vector, size `[batch_size]`,
containing the actual lengths for each of the sequences in the batch.
If not provided, all batch entries are assumed to be full sequences; and
time reversal is applied from time `0` to `max_time` for each sequence.
也就是說,這個sequence_length反映的是序列真實的有效的長度,如果不指定就按照完整序列來迭代rnn。大家想之前為了矩陣表示的方便,最起碼在每個batch裡面我們需要讓各個序列的長度相同,不夠長度的我們採用一些填充的辦法。
我一開始的實現是讓每個句子的長度都填充或者截斷為100,於是rnn需要對每一個長度為100的序列進行迭代,大家都知道LSTM/GRU 在序列長度大於30的時候效果會急劇下降,因此我一開始把所有序列長度設定為100後,又不在dynamic_rnn函式中指定實際的序列長度,那麼模型始終輸出“O” 也就是可以解釋了。後面我把句子的長度都截斷為25後,效果裡面就好了很多,模型也能夠收斂了。
對於長度都為100的序列,LSTM的確無能為力啊!
當然這樣截斷的方式也不好,最好的方式是在dynamic_rnn函式中指定各個序列的實際有效長度。
本例,最大的啟發是,dynamic_rnn中sequence_length引數的作用,以及序列填充後需要考慮序列長度是否是lstm可有效接受的。
需要養成一個習慣:認真對待sequence_length引數,尤其是當填充後的序列特別特別長的時候。