
基於密度的聚類演算法(Clustering by fast search and find of density peaksd)
一、概述
“Clustering by fast search and find of density peaks”(下面簡稱CFDP)是在《Science》期刊上發表的的一篇論文,論文中提出了一種非常巧妙的聚類演算法-基於密度的聚類演算法。雖然文章出來後遭到了許多人的質疑,但是作為一個小白,該演算法的思想是非常值得學習的。新聚類演算法的基本思想很新穎,且簡單明快,值得學習。下面將對該演算法的基本原理進行介紹,並對其中的若干實現細節進行分析。
二、演算法的基本假設
經典的聚類演算法K-means是通過指定聚類中心,再通過迭代的方式更新聚類中心的方式,由於每個點都被指派到距離最近的聚類中心,所以導致其不能檢測非球面類別的資料分佈。雖然有DBSCAN(density-based spatial clustering of applications with noise)對於任意形狀分佈的進行聚類,但是必須指定一個密度閾值,從而去除低於此密度閾值的噪音點。
基於以上分析,在CFDP演算法是基於這樣的假設:聚類中心周圍都是密度比其低的點,同時這些點距離該聚類中心的距離相比於其他聚類中心來說是最近的。
三、聚類演算法流程
對於每一個數據點,要計算兩個量:點的區域性密度和該點到具有更高區域性密度的點的距離,而這兩個值都取決於資料點間的距離。
1、計算區域性密度
資料點的區域性密度計算有兩種方法:Cut-off kernal和Gaussian kernel
- Cut-off kernal
Cut-off kernal的計算公式如下:

關於dc的確定,文章指出,dc可以選擇為平均每個點的鄰居區域性密度為資料總數的1-2%(具體做實驗時還得調整,但是結果可能不是特別讓人滿意)。
- 注意
在該演算法中Dc需要人工設定,是一個可變引數。從某種程度上來講,Dc的選取決定著這個聚類演算法的成敗,取得太大和太小都不行。如果Dc去的太大,將使得每個資料點的區域性密度值都很大,導致區分度不高。極端情況是Dc的值大於所有點的最大距離值,這樣演算法的最終結果就是所有點都屬於同一個聚類中心。如果Dc取值太小,那麼同一個分組有可能被拆分為多個。極端情況是Dc比所有點的距離值都要小,這樣將導致每一個點都是一個聚類中心。在文中作者給出的參考方法是選取一個Dc,使得每個資料點的平均鄰居個數約為資料點總數的1%-2%,這裡的鄰居是指與之距離不超過Dc的資料點。
- Gaussian kernel
Gaussian kernel的計算公示如下:

2、計算距離
距離定義如下:
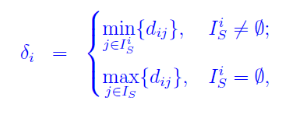
對於非區域性密度最大點,計算距離δi實際上分兩步
- 找到所有區域性密度比i點高的點;
- 在這些點中找到距離i點最近的那個點j,i和j的距離就是δi的值。
對於區域性密度最大點,δi實際上是該點和其他所有點距離值的最大值。
3、找出聚類中心
圖1.中的簡單示例展示了演算法的核心思想。圖1.A展示了二維空間中的28個點。可以發現點1和點10的區域性密度最大,故將其作為類簇中心。圖1.B展示了對於每一個點函式的圖示(區域性密度為橫軸,距離為縱軸),稱其為決策圖。點9和點10的區域性密度值相似,但距離值卻有很大差別:點9屬於點1的類簇,其它幾個有更高的區域性密度的點距離其很近,然而點10的有更高密度的最近鄰屬於其它的類簇。所以,正如預期的那樣,只有具有高區域性密度和相對較高的距離的點才是類簇中心。因為點26、27、28是孤立的,所以有相對較高的距離值和低區域性密度值,它們可以被看作是由單個點做成的類簇,也就是異常點。
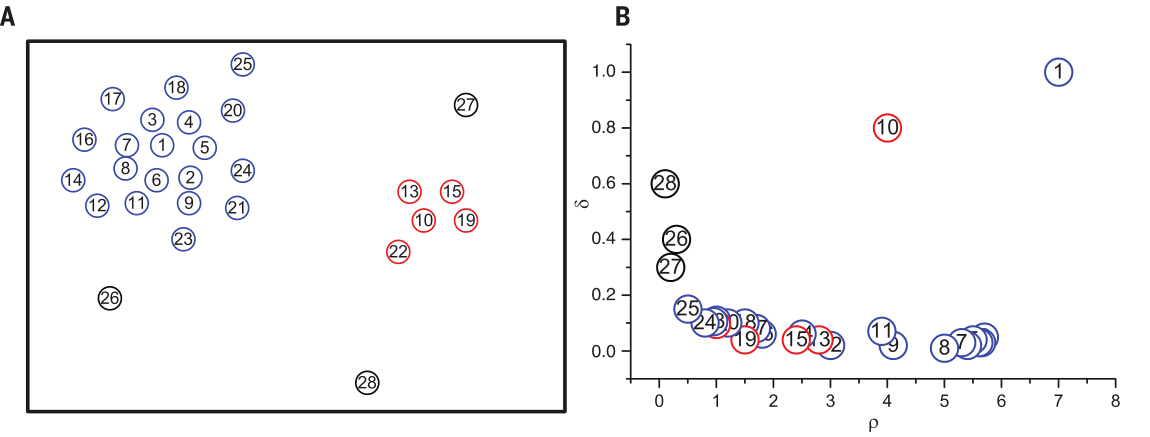
圖1.演算法在二維空間的展示
(A)中點的分佈 資料點按照密度降序排列。不同的顏色代表不同的類簇。
類簇中心找到後,剩餘的每個點被歸屬到它的有更高密度的最近鄰所屬類簇。類簇分配只需一步即可完成,不像其它演算法要對目標函式進行迭代優化。
4、剩餘點的類別指派
當聚類中心確定之後,剩下的點的類別標籤指定按照以下原則:
- 首先規定:當前點的類別標籤(也就是屬於哪個聚類中心)和高於當前點密度的最近的點的標籤一致。
- 根據上面的規定對所有點的類別進行了指定。如下圖所示,編號表示密度高低,“1”表示密度最高,以此類推。“1”和“2”均為聚類中心,”3”號點的類別標籤應該為與距離其最近的密度高於其的點一致,因此“3”號點屬於聚類中心1,由於距離“4”號點最近的密度比其高的點為“3”號點,因此其類別標籤與”3“號相同,也為聚類中心1,以此類推。

在對每一個點指派所屬類別之後,該演算法並沒有人為的直接用噪音訊號截斷的方法去除噪音點,而是先算出類別之間的邊界,然後找出邊界中密度值最高的點的密度作為閾值,只保留前類別中大於或等於此密度值的點。
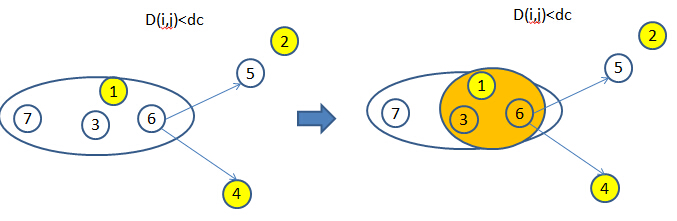
5、類別間邊界確定
首先為每個類簇定義一個邊界區域,即分配到該類簇但於其它類簇的點的距離小於dc(截斷距離)的點的集合。然後為每個類簇找到其邊界區域中密度最高的點,並以該點的密度作為閥值來篩選類簇。
以下圖為例,對於類別1中的所有點(1,3,6,7),計算與其他類別中所有點距離小於等於截斷距離DC的最大密度值,例如“1”號點由於其距離其他類別的點的距離均大於DC,因此不予考慮。由下圖可以看出密度第6的值距離其他類別最近所以選定密度=(6),由於“7”號點的密度(7)<(6), 因此將其作為噪音點去除,最後得到的類別1的點為綠色圈所示“1”、“3”和“6”。
四、總結
演算法優點
該聚類演算法可以得到非球形的聚類結果,可以很好地描述資料分佈,同時在演算法複雜度上也比一般的K-means演算法的複雜度低。同時此演算法的只考慮點與點之間的距離,因此不需要將點對映到一個向量空間中。演算法缺點
需要事先計算好所有點與點之間的距離。如果樣本太大則整個距離矩陣的記憶體開銷特別大,因此如果只需要得到最終聚類中心,則可以考慮犧牲速度的方式計算每一個樣本點的和,避免直接載入距離矩陣。