
DBSCAN密度聚類演算法
DBSCAN(Density-Based Spatial Clustering of Applications with Noise,具有噪聲的基於密度的聚類方法)是一種很典型的密度聚類演算法,和K-Means,BIRCH這些一般只適用於凸樣本集的聚類相比,DBSCAN既可以適用於凸樣本集,也可以適用於非凸樣本集。下面我們就對DBSCAN演算法的原理做一個總結。
1. 密度聚類原理
DBSCAN是一種基於密度的聚類演算法,這類密度聚類演算法一般假定類別可以通過樣本分佈的緊密程度決定。同一類別的樣本,他們之間的緊密相連的,也就是說,在該類別任意樣本週圍不遠處一定有同類別的樣本存在。
通過將緊密相連的樣本劃為一類,這樣就得到了一個聚類類別。通過將所有各組緊密相連的樣本劃為各個不同的類別,則我們就得到了最終的所有聚類類別結果。
2. DBSCAN密度定義
在上一節我們定性描述了密度聚類的基本思想,本節我們就看看DBSCAN是如何描述密度聚類的。DBSCAN是基於一組鄰域來描述樣本集的緊密程度的,引數($\epsilon$, MinPts)用來描述鄰域的樣本分佈緊密程度。其中,$\epsilon$描述了某一樣本的鄰域距離閾值,MinPts描述了某一樣本的距離為$\epsilon$的鄰域中樣本個數的閾值。
假設我的樣本集是D=$(x_1,x_2,...,x_m)$,則DBSCAN具體的密度描述定義如下:
1) $\epsilon$-鄰域:對於$x_j \in D$,其$\epsilon$-鄰域包含樣本集D中與$x_j$的距離不大於$\epsilon$的子樣本集,即$N_{\epsilon}(x_j) = \{x_i \in D | distance(x_i,x_j) \leq \epsilon\}$, 這個子樣本集的個數記為$|N_{\epsilon}(x_j)|$
2) 核心物件:對於任一樣本$x_j \in D$,如果其$\epsilon$-鄰域對應的$N_{\epsilon}(x_j)$至少包含MinPts個樣本,即如果$|N_{\epsilon}(x_j)| \geq MinPts$,則$x_j$是核心物件。
3)密度直達:如果$x_i$位於$x_j$的$\epsilon$-鄰域中,且$x_j$是核心物件,則稱$x_i$由$x_j$密度直達。注意反之不一定成立,即此時不能說$x_j$由$x_i$密度直達, 除非且$x_i$也是核心物件。
4)密度可達:對於$x_i$和$x_j$,如果存在樣本樣本序列$p_1, p_2,...,p_T$,滿足$p_1 = x_i, p_T = x_j$, 且$p_{t+1}$由$p_{t}$密度直達,則稱$x_j$由$x_i$密度可達。也就是說,密度可達滿足傳遞性。此時序列中的傳遞樣本$p_1, p_2,...,p_{T-1}$均為核心物件,因為只有核心物件才能使其他樣本密度直達。注意密度可達也不滿足對稱性,這個可以由密度直達的不對稱性得出。
5)密度相連:對於$x_i$和$x_j$,如果存在核心物件樣本$x_k$,使$x_i$和$x_j$均由$x_k$密度可達,則稱$x_i$和$x_j$密度相連。注意密度相連關係是滿足對稱性的。
從下圖可以很容易看出理解上述定義,圖中MinPts=5,紅色的點都是核心物件,因為其$\epsilon$-鄰域至少有5個樣本。黑色的樣本是非核心物件。所有核心物件密度直達的樣本在以紅色核心物件為中心的超球體內,如果不在超球體內,則不能密度直達。圖中用綠色箭頭連起來的核心物件組成了密度可達的樣本序列。在這些密度可達的樣本序列的$\epsilon$-鄰域內所有的樣本相互都是密度相連的。
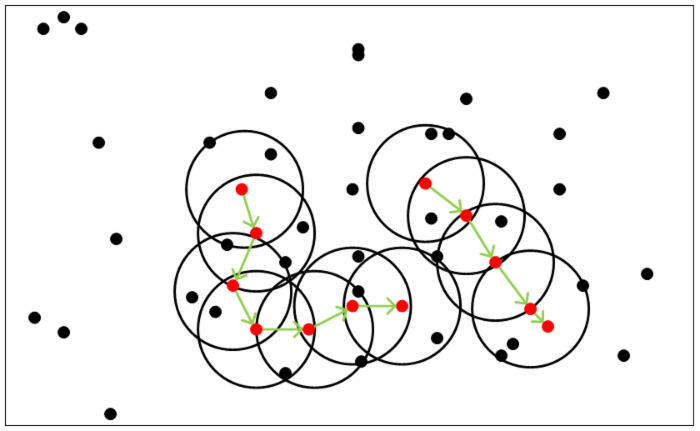
有了上述定義,DBSCAN的聚類定義就簡單了。
3. DBSCAN密度聚類思想
DBSCAN的聚類定義很簡單:由密度可達關係匯出的最大密度相連的樣本集合,即為我們最終聚類的一個類別,或者說一個簇。
這個DBSCAN的簇裡面可以有一個或者多個核心物件。如果只有一個核心物件,則簇裡其他的非核心物件樣本都在這個核心物件的$\epsilon$-鄰域裡;如果有多個核心物件,則簇裡的任意一個核心物件的$\epsilon$-鄰域中一定有一個其他的核心物件,否則這兩個核心物件無法密度可達。這些核心物件的$\epsilon$-鄰域裡所有的樣本的集合組成的一個DBSCAN聚類簇。
那麼怎麼才能找到這樣的簇樣本集合呢?DBSCAN使用的方法很簡單,它任意選擇一個沒有類別的核心物件作為種子,然後找到所有這個核心物件能夠密度可達的樣本集合,即為一個聚類簇。接著繼續選擇另一個沒有類別的核心物件去尋找密度可達的樣本集合,這樣就得到另一個聚類簇。一直執行到所有核心物件都有類別為止。
基本上這就是DBSCAN演算法的主要內容了,是不是很簡單?但是我們還是有三個問題沒有考慮。
第一個是一些異常樣本點或者說少量遊離於簇外的樣本點,這些點不在任何一個核心物件在周圍,在DBSCAN中,我們一般將這些樣本點標記為噪音點。
第二個是距離的度量問題,即如何計算某樣本和核心物件樣本的距離。在DBSCAN中,一般採用最近鄰思想,採用某一種距離度量來衡量樣本距離,比如歐式距離。這和KNN分類演算法的最近鄰思想完全相同。對應少量的樣本,尋找最近鄰可以直接去計算所有樣本的距離,如果樣本量較大,則一般採用KD樹或者球樹來快速的搜尋最近鄰。如果大家對於最近鄰的思想,距離度量,KD樹和球樹不熟悉,建議參考之前寫的另一篇文章K近鄰法(KNN)原理小結。
第三種問題比較特殊,某些樣本可能到兩個核心物件的距離都小於$\epsilon$,但是這兩個核心物件由於不是密度直達,又不屬於同一個聚類簇,那麼如果界定這個樣本的類別呢?一般來說,此時DBSCAN採用先來後到,先進行聚類的類別簇會標記這個樣本為它的類別。也就是說BDSCAN的演算法不是完全穩定的演算法。
4. DBSCAN聚類演算法
下面我們對DBSCAN聚類演算法的流程做一個總結。
輸入:樣本集D=$(x_1,x_2,...,x_m)$,鄰域引數$(\epsilon, MinPts)$, 樣本距離度量方式
輸出: 簇劃分C.
1)初始化核心物件集合$\Omega = \emptyset$, 初始化聚類簇數k=0,初始化未訪問樣本集合$\Gamma$ = D, 簇劃分C = $\emptyset$
2) 對於j=1,2,...m, 按下面的步驟找出所有的核心物件:
a) 通過距離度量方式,找到樣本$x_j$的$\epsilon$-鄰域子樣本集$N_{\epsilon}(x_j)$
b) 如果子樣本集樣本個數滿足$|N_{\epsilon}(x_j)| \geq MinPts$, 將樣本$x_j$加入核心物件樣本集合:$\Omega = \Omega \cup \{x_j\}$
3)如果核心物件集合$\Omega = \emptyset$,則演算法結束,否則轉入步驟4.
4)在核心物件集合$\Omega$中,隨機選擇一個核心物件$o$,初始化當前簇核心物件佇列$\Omega_{cur} = \{o\}$, 初始化類別序號k=k+1,初始化當前簇樣本集合$C_k = \{o\}$, 更新未訪問樣本集合$\Gamma = \Gamma - \{o\}$
5)如果當前簇核心物件佇列$\Omega_{cur} = \emptyset$,則當前聚類簇$C_k$生成完畢, 更新簇劃分C=$\{C_1,C_2,...,C_k\}$, 更新核心物件集合$\Omega = \Omega - {C_k}$, 轉入步驟3。
6)在當前簇核心物件佇列$\Omega_{cur}$中取出一個核心物件$o^{'}$,通過鄰域距離閾值$\epsilon$找出所有的$\epsilon$-鄰域子樣本集$N_{\epsilon}(o^{'})$,令$\Delta = N_{\epsilon}(o^{'}) \cap \Gamma $, 更新當前簇樣本集合$C_k =C_k \cup \Delta$, 更新未訪問樣本集合$\Gamma = \Gamma - \Delta$, 更新$\Omega_{cur} = \Omega_{cur} \cup (\Delta \cap \Omega) - {o'}$,轉入步驟5.
輸出結果為: 簇劃分C=$\{C_1,C_2,...,C_k\}$
5. DBSCAN小結
和傳統的K-Means演算法相比,DBSCAN最大的不同就是不需要輸入類別數k,當然它最大的優勢是可以發現任意形狀的聚類簇,而不是像K-Means,一般僅僅使用於凸的樣本集聚類。同時它在聚類的同時還可以找出異常點,這點和BIRCH演算法類似。
那麼我們什麼時候需要用DBSCAN來聚類呢?一般來說,如果資料集是稠密的,並且資料集不是凸的,那麼用DBSCAN會比K-Means聚類效果好很多。如果資料集不是稠密的,則不推薦用DBSCAN來聚類。
下面對DBSCAN演算法的優缺點做一個總結。
DBSCAN的主要優點有:
1) 可以對任意形狀的稠密資料集進行聚類,相對的,K-Means之類的聚類演算法一般只適用於凸資料集。
2) 可以在聚類的同時發現異常點,對資料集中的異常點不敏感。
3) 聚類結果沒有偏倚,相對的,K-Means之類的聚類演算法初始值對聚類結果有很大影響。
DBSCAN的主要缺點有:
1)如果樣本集的密度不均勻、聚類間距差相差很大時,聚類質量較差,這時用DBSCAN聚類一般不適合。
2) 如果樣本集較大時,聚類收斂時間較長,此時可以對搜尋最近鄰時建立的KD樹或者球樹進行規模限制來改進。
3) 調參相對於傳統的K-Means之類的聚類演算法稍複雜,主要需要對距離閾值$\epsilon$,鄰域樣本數閾值MinPts聯合調參,不同的引數組合對最後的聚類效果有較大影響。
(歡迎轉載,轉載請註明出處。歡迎溝通交流: [email protected])
相關推薦
DBSCAN密度聚類演算法
DBSCAN(Density-Based Spatial Clustering of Applications with Noise,具有噪聲的基於密度的聚類方法)是一種很典型的密度聚類演算法,和K-Means,BIRCH這些一般只適用於凸樣本集的聚類相比,DBSCAN既可以適用於凸樣本集,也可以適用
DBSCAN詳解(密度聚類演算法開篇)
DBSCAN詳解 第二十二次寫部落格,本人數學基礎不是太好,如果有幸能得到讀者指正,感激不盡,希望能借此機會向大家學習。這一篇作為密度聚類演算法族的開篇,主要是介紹其中最流行的一種演算法——DBSCAN,其他演算法在後續會陸續更新,連結附在該篇文章的結尾處。
【無監督學習】3:Density Peaks聚類演算法實現(區域性密度聚類演算法)
前言:密度峰聚類演算法和DBSCAN聚類演算法有相似的地方,兩者都是基於密度的聚類方式。自己是在學習無監督學習過程中,無意間見到介紹這種聚類演算法的文章,感覺密度峰聚類演算法方法很新奇,操作也很簡答,於是自己也動手寫一下了。 –—-—-—-—-—-—-—-—-
DBSCAN基於密度的聚類演算法
**DBSCAN演算法和實現 ——DBSCAN(Density-Based Spatial Clustering of Applications with Noise)是一個比較有代表性的基於密度的聚類演算法,它是一種適應性極強的聚類演算法,不同於K-mean
聚類演算法(三)——基於密度的聚類演算法(以 DBSCAN 為例)
上一篇部落格提到 K-kmeans 演算法存在好幾個缺陷,其中之一就是該演算法無法聚類哪些非凸的資料集,也就是說,K-means 聚類的形狀一般只能是球狀的,不能推廣到任意的形狀。本文介紹一種基於密度的聚類方法,可以聚類任意的形狀。 基於密度的聚類是
基於密度的聚類演算法(DBSCAN)的java實現
k-means和EM演算法適合發現凸型的聚類(大概就是圓形,橢圓形比較規則的類),而對於非凸型的聚類,這兩種方法就很難找到準確的聚類了。比如如下圖: 可能來自不同類的點反而比來自相同類的點還要靠的更近。 太多的原理和演算法介紹,大家可
聚類演算法之DBSCAN(具有噪聲的基於密度的聚類方法)
# !/usr/bin/python # -*- coding:utf-8 -*- import numpy as np import matplotlib.pyplot as plt import sklearn.datasets as ds import matpl
機器學習sklearn19.0聚類演算法——層次聚類(AGNES/DIANA)、密度聚類(DBSCAN/MDCA)、譜聚類
一、層次聚類 BIRCH演算法詳細介紹以及sklearn中的應用如下面部落格連結: http://www.cnblogs.com/pinard/p/6179132.html http://www.cnblogs.com/pinard/p/62
DBSCAN(基於高密度聚類的)演算法
DBSCAN(Density-Based Spatial Clustering of Applications with Noise)聚類演算法,它是一種基於高密度連通區域的、基於密度的聚類演算法,能夠將具有足夠高密度的區域劃分為簇,並在具有噪聲的資料中發現任意
簡單易學的機器學習演算法——基於密度的聚類演算法DBSCAN
%% DBSCAN clear all; clc; %% 匯入資料集 % data = load('testData.txt'); data = load('testData_2.txt'); % 定義引數Eps和MinPts MinPts = 5; Eps = epsilon(data, MinPts)
聚類演算法之DBSCAN演算法之二:高維資料剪枝應用NQ-DBSCAN
一、經典DBSCAN的不足 1.由於“維度災難”問題,應用高維資料效果不佳 2.執行時間在尋找每個點的最近鄰和密度計算,複雜度是O(n2)。當d>=3時,由於BCP等數學問題出現,時間複雜度會急劇上升到Ω(n的四分之三次方)。 二、DBSCAN在高維資料的改進 目前的研究有
聚類演算法之DBSCAN演算法之一:經典DBSCAN
DBSCAN是基於密度空間的聚類演算法,與KMeans演算法不同,它不需要確定聚類的數量,而是基於資料推測聚類的數目,它能夠針對任意形狀產生聚類。 1.epsilon-neighborhood epsoiln-neighborhood(簡稱e-nbhd)可理解為密度空間,表示半徑為e
DBSCAN聚類演算法難嗎?我們來看看吧~
往期經典回顧 從零開始學Python【29】--K均值聚類(實戰部分) 從零開始學Python【28】--K均值聚類(理論部分) 從零開始學Python【27】--Logistic迴歸(實戰部分) 從零開始學Python【26】--Logistic迴歸(理論部分) 從零開始學Py
DBSCAN聚類演算法
1、演算法引入及簡介 為什麼要引入DBSCAN? K均值聚類使用非常廣泛,作為古老的聚類方法,它的演算法非常簡單,而且速度很快。但是其缺點在於它不能識別非球形的簇;而DBS
聚類模型-密度聚類-DBSCAN
聚類模型 1、層次聚類 2、原型聚類-K-means 3、模型聚類-GMM 4、EM演算法-LDA主題模型 5、密度聚類-DBSCAN 6、圖聚類-譜聚類 五、密度聚類-DBSCAN DBSCAN的類表示是一簇密度可達
基於密度聚類DBSCAN
/* DBSCAN Algorithm 15S103182 Ethan */ #include <iostream> #include <sstream> #include <fstream> #include <vector>
(3)聚類演算法之DBSCAN演算法
文章目錄 1.引言 2.`DBSCAN`相關定義 3.`DBSCAN`密度聚類思想 3.1 `DBSCAN`演算法定義 3.2 DBSCAN演算法流程 4.`DBSCAN`演算法實現 4.1 使用`n
【原創】演算法分享(5)聚類演算法DBSCAN
簡介 DBSCAN:Density-based spatial clustering of applications with noise is a data clustering algorithm proposed by Martin Ester, Hans-Peter
一種改進的自適應快速AF-DBSCAN聚類演算法
本人研究生期間寫的關於聚類演算法的一篇論文,已發表,希望對大家學習機器學習、資料探勘等相關研究有所幫助! 一種改進的自適應快速AF-DBSCAN聚類演算法 An Improved Adaptive and Fast AF-DBSCAN Clustering Algorit
機器學習總結(十):常用聚類演算法(Kmeans、密度聚類、層次聚類)及常見問題
任務:將資料集中的樣本劃分成若干個通常不相交的子集。 效能度量:類內相似度高,類間相似度低。兩大類:1.有參考標籤,外部指標;2.無參照,內部指標。 距離計算:非負性,同一性(與自身距離為0),對稱性