
Python3《機器學習實戰》學習筆記(九):支援向量機實戰篇之再撕非線性SVM
一 前言
上篇文章講解的是線性SVM的推導過程以及簡化版SMO演算法的程式碼實現。本篇文章將講解SMO演算法的優化方法以及非線性SVM。
二 SMO演算法優化
在幾百個點組成的小規模資料集上,簡化版SMO演算法的執行是沒有什麼問題的,但是在更大的資料集上的執行速度就會變慢。簡化版SMO演算法的第二個α的選擇是隨機的,針對這一問題,我們可以使用啟發式選擇第二個α值,來達到優化效果。
1 啟發選擇方式
下面這兩個公式想必已經不再陌生:
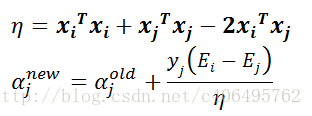
在實現SMO演算法的時候,先計算η,再更新a_j。為了加快第二個α_j乘子的迭代速度,需要讓直線的斜率增大,對於α_j的更新公式,其中η值沒有什麼文章可做,於是只能令:
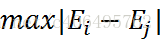
因此,我們可以明確自己的優化方法了:
- 最外層迴圈,首先在樣本中選擇違反KKT條件的一個乘子作為最外層迴圈,然後用”啟發式選擇”選擇另外一個乘子並進行這兩個乘子的優化
- 在非邊界乘子中尋找使得|E_i - E_j|最大的樣本
- 如果沒有找到,則從整個樣本中隨機選擇一個樣本
接下來,讓我們看看完整版SMO演算法如何實現。
2 完整版SMO演算法
完整版Platt SMO演算法是通過一個外迴圈來選擇違反KKT條件的一個乘子,並且其選擇過程會在這兩種方式之間進行交替:
- 在所有資料集上進行單遍掃描
- 在非邊界α中實現單遍掃描
非邊界α指的就是那些不等於邊界0或C的α值,並且跳過那些已知的不會改變的α值。所以我們要先建立這些α的列表,用於才能出α的更新狀態。
在選擇第一個α值後,演算法會通過”啟發選擇方式”選擇第二個α值。
3 編寫程式碼
我們首先構建一個僅包含init方法的optStruct類,將其作為一個數據結構來使用,方便我們對於重要資料的維護。程式碼思路和之前的簡化版SMO演算法是相似的,不同之處在於增加了優化方法,如果上篇文章已經看懂,我想這個程式碼會很好理解。建立一個svm-smo.py檔案,編寫程式碼如下:
# -*-coding:utf-8 -*-
import matplotlib.pyplot as plt
import numpy as np
import random
"""
Author:
Jack Cui
Blog:
http://blog.csdn.net/c406495762
Zhihu:
https://www.zhihu.com/people/Jack--Cui/
Modify:
2017-10-03
""" 完整版SMO演算法(左圖)與簡化版SMO演算法(右圖)執行結果對比如下圖所示:
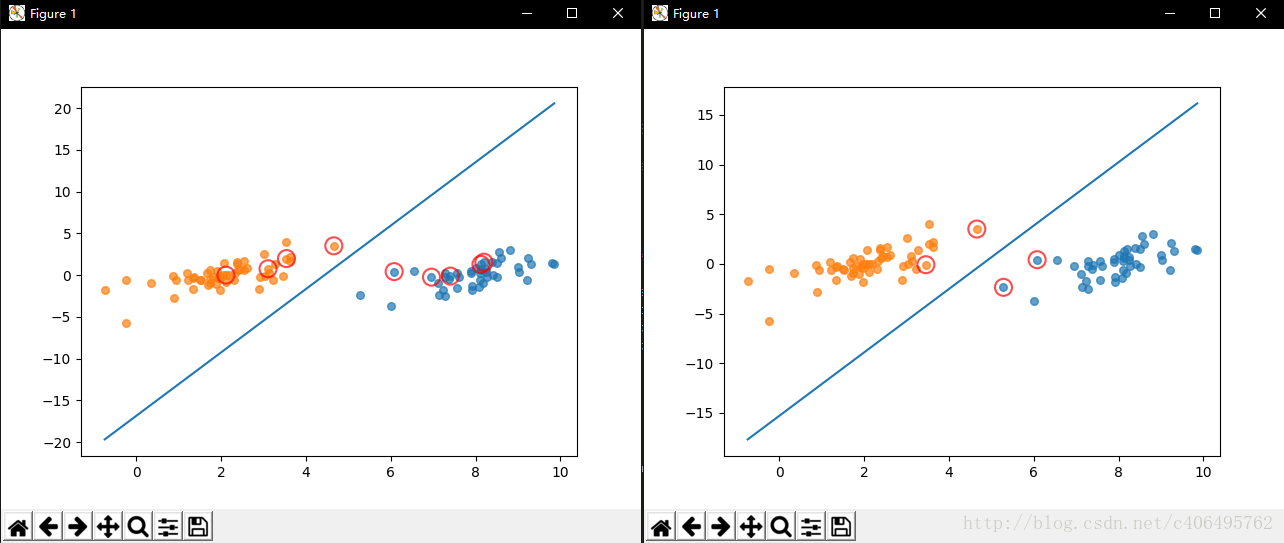
圖中畫紅圈的樣本點為支援向量上的點,是滿足演算法的一種解。完整版SMO演算法覆蓋整個資料集進行計算,而簡化版SMO演算法是隨機選擇的。可以看出,完整版SMO演算法選出的支援向量樣點更多,更接近理想的分隔超平面。
對比兩種演算法的運算時間,我的測試結果是完整版SMO演算法的速度比簡化版SMO演算法的速度快6倍左右。
其實,優化方法不僅僅是簡單的啟發式選擇,還有其他優化方法,SMO演算法速度還可以進一步提高。但是鑑於文章進度,這裡不再進行展開。感興趣的朋友,可以移步這裡進行理論學習:http://www.cnblogs.com/zangrunqiang/p/5515872.html
三 非線性SVM
1 核技巧
我們已經瞭解到,SVM如何處理線性可分的情況,而對於非線性的情況,SVM的處理方式就是選擇一個核函式。簡而言之:線上性不可分的情況下,SVM通過某種事先選擇的非線性對映(核函式)將輸入變數映到一個高維特徵空間,將其變成在高維空間線性可分,在這個高維空間中構造最優分類超平面。
根據上篇文章,線性可分的情況下,可知最終的超平面方程為:
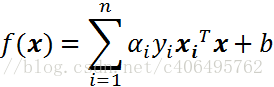
將上述公式用內積來表示:
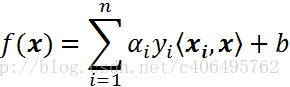
對於線性不可分,我們使用一個非線性對映,將資料對映到特徵空間,在特徵空間中使用線性學習器,分類函式變形如下:
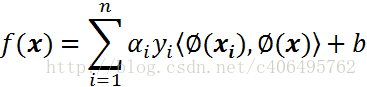
其中ϕ從輸入空間(X)到某個特徵空間(F)的對映,這意味著建立非線性學習器分為兩步:
- 首先使用一個非線性對映將資料變換到一個特徵空間F;
- 然後在特徵空間使用線性學習器分類。
如果有一種方法可以在特徵空間中直接計算內積<ϕ(x_i),ϕ(x)>,就像在原始輸入點的函式中一樣,就有可能將兩個步驟融合到一起建立一個分線性的學習器,這樣直接計算的方法稱為核函式方法。
這裡直接給出一個定義:核是一個函式k,對所有x,z∈X,滿足k(x,z)=<ϕ(x_i),ϕ(x)>,這裡ϕ(·)是從原始輸入空間X到內積空間F的對映。
簡而言之:如果不是用核技術,就會先計算線性映ϕ(x_1)和ϕ(x_2),然後計算這它們的內積,使用了核技術之後,先把ϕ(x_1)和ϕ(x_2)的一般表示式<ϕ(x_1),ϕ(x_2)>=k(<ϕ(x_1),ϕ(x_2) >)計算出來,這裡的<·,·>表示內積,k(·,·)就是對應的核函式,這個表示式往往非常簡單,所以計算非常方便。
這種將內積替換成核函式的方式被稱為核技巧(kernel trick)。
2 非線性資料處理
已經知道了核技巧是什麼,但是為什麼要這樣做呢?我們先舉一個簡單的例子,進行說明。假設二維平面x-y上存在若干點,其中點集A服從{x,y|x^2+y^2=1},點集B服從{x,y|x^2+y^2=9},那麼這些點在二維平面上的分佈是這樣的:
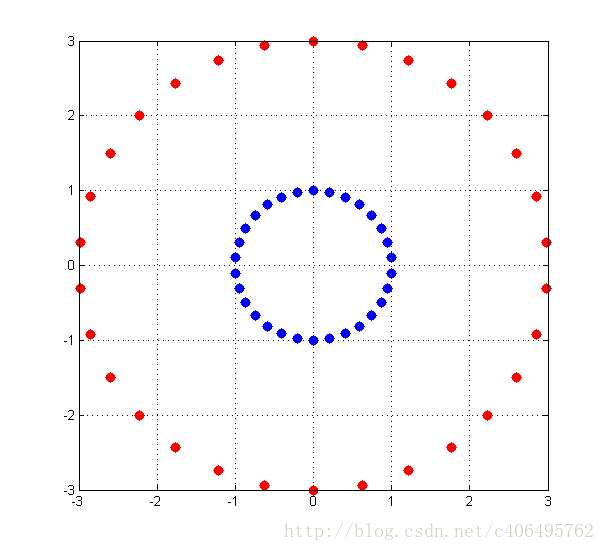
藍色的是點集A,紅色的是點集B,他們在xy平面上並不能線性可分,即用一條直線分割( 雖然肉眼是可以識別的) 。採用對映(x,y)->(x,y,x^2+y^2)後,在三維空間的點的分佈為:
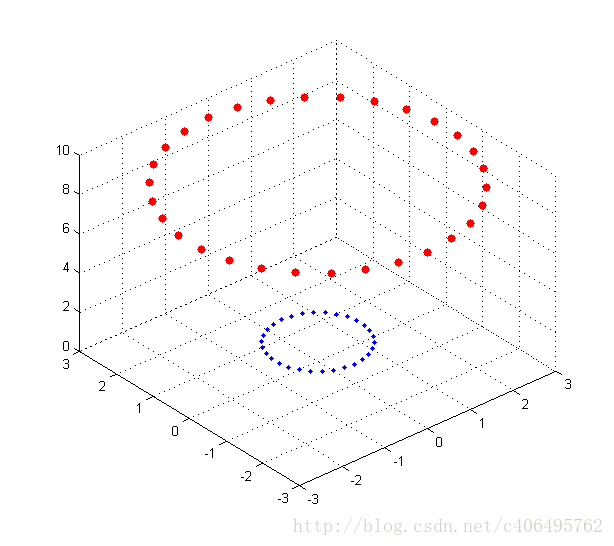
可見紅色和藍色的點被對映到了不同的平面,在更高維空間中是線性可分的(用一個平面去分割)。
上述例子中的樣本點的分佈遵循圓的分佈。繼續推廣到橢圓的一般樣本形式:
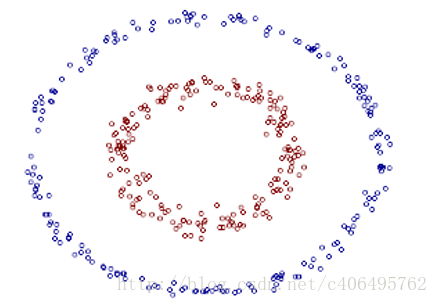
上圖的兩類資料分佈為兩個橢圓的形狀,這樣的資料本身就是不可分的。不難發現,這兩個半徑不同的橢圓是加上了少量的噪音生成得到的。所以,一個理想的分界應該也是一個橢圓,而不是一個直線。如果用X1和X2來表示這個二維平面的兩個座標的話,我們知道這個分界橢圓可以寫為:
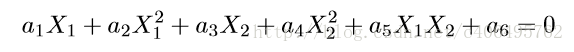
這個方程就是高中學過的橢圓一般方程。注意上面的形式,如果我們構造另外一個五維的空間,其中五個座標的值分別為:
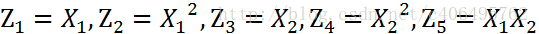
那麼,顯然我們可以將這個分界的橢圓方程寫成如下形式:
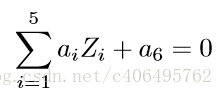
這個關於新的座標Z1,Z2,Z3,Z4,Z5的方程,就是一個超平面方程,它的維度是5。也就是說,如果我們做一個對映 ϕ : 二維 → 五維,將 X1,X2按照上面的規則對映為 Z1,Z2,··· ,Z5,那麼在新的空間中原來的資料將變成線性可分的,從而使用之前我們推導的線性分類演算法就可以進行處理了。
我們舉個簡單的計算例子,現在假設已知的對映函式為:
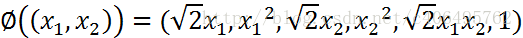
這個是一個從2維對映到5維的例子。如果沒有使用核函式,根據上一小節的介紹,我們需要先結算對映後的結果,然後再進行內積運算。那麼對於兩個向量a1=(x1,x2)和a2=(y1,y2)有:
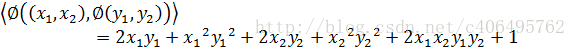
另外,如果我們不進行對映計算,直接運算下面的公式:
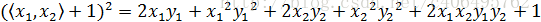
你會發現,這兩個公式的計算結果是相同的。區別在於什麼呢?
- 一個是根據對映函式,對映到高維空間中,然後再根據內積的公式進行計算,計算量大;
- 另一個則直接在原來的低維空間中進行計算,而不需要顯式地寫出對映後的結果,計算量小。
其實,在這個例子中,核函式就是:
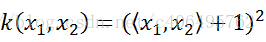
我們通過k(x1,x2)的低維運算得到了先對映再內積的高維運算的結果,這就是核函式的神奇之處,它有效減少了我們的計算量。在這個例子中,我們對一個2維空間做對映,選擇的新的空間是原始空間的所以一階和二階的組合,得到了5維的新空間;如果原始空間是3維的,那麼我們會得到19維的新空間,這個數目是呈爆炸性增長的。如果我們使用ϕ(·)做對映計算,難度非常大,而且如果遇到無窮維的情況,就根本無從計算了。所以使用核函式進行計算是非常有必要的。
3 核技巧的實現
通過核技巧的轉變,我們的分類函式變為:
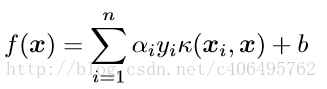
我們的對偶問題變成了:
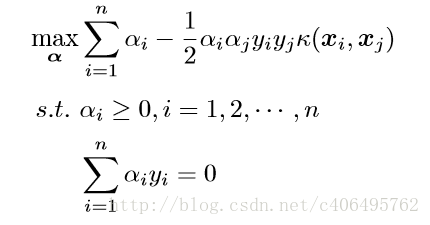
這樣,我們就避開了高緯度空間中的計算。當然,我們剛剛的例子是非常簡單的,我們可以手動構造出來對應對映的核函數出來,如果對於任意一個對映,要構造出對應的核函式就很困難了。因此,通常,人們會從一些常用的核函式中進行選擇,根據問題和資料的不同,選擇不同的引數,得到不同的核函式。接下來,要介紹的就是一個非常流行的核函式,那就是徑向基核函式。
徑向基核函式是SVM中常用的一個核函式。徑向基核函式採用向量作為自變數的函式,能夠基於向量舉例運算輸出一個標量。徑向基核函式的高斯版本的公式如下:
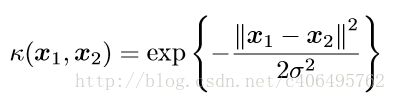
其中,σ是使用者自定義的用於確定到達率(reach)或者說函式值跌落到0的速度引數。上述高斯核函式將資料從原始空間對映到無窮維空間。關於無窮維空間,我們不必太擔心。高斯核函式只是一個常用的核函式,使用者並不需要確切地理解資料到底是如何表現的,而且使用高斯核函式還會得到一個理想的結果。如果σ選得很大的話,高次特徵上的權重實際上衰減得非常快,所以實際上(數值上近似一下)相當於一個低維的子空間;反過來,如果σ選得很小,則可以將任意的資料對映為線性可分——當然,這並不一定是好事,因為隨之而來的可能是非常嚴重的過擬合問題。不過,總的來說,通過調控引數σ,高斯核實際上具有相當高的靈活性,也是使用最廣泛的核函式之一。
四 程式設計實現非線性SVM
1 視覺化資料集
我們先編寫程式簡單看下資料集:
# -*-coding:utf-8 -*-
import matplotlib.pyplot as plt
import numpy as np
def showDataSet(dataMat, labelMat):
"""
資料視覺化
Parameters:
dataMat - 資料矩陣
labelMat - 資料標籤
Returns:
無
"""
data_plus = [] #正樣本
data_minus = [] #負樣本
for i in range(len(dataMat)):
if labelMat[i] > 0:
data_plus.append(dataMat[i])
else:
data_minus.append(dataMat[i])
data_plus_np = np.array(data_plus) #轉換為numpy矩陣
data_minus_np = np.array(data_minus) #轉換為numpy矩陣
plt.scatter(np.transpose(data_plus_np)[0], np.transpose(data_plus_np)[1]) #正樣本散點圖
plt.scatter(np.transpose(data_minus_np)[0], np.transpose(data_minus_np)[1]) #負樣本散點圖
plt.show()
if __name__ == '__main__':
dataArr,labelArr = loadDataSet('testSetRBF.txt') #載入訓練集
showDataSet(dataArr, labelArr)程式執行結果:
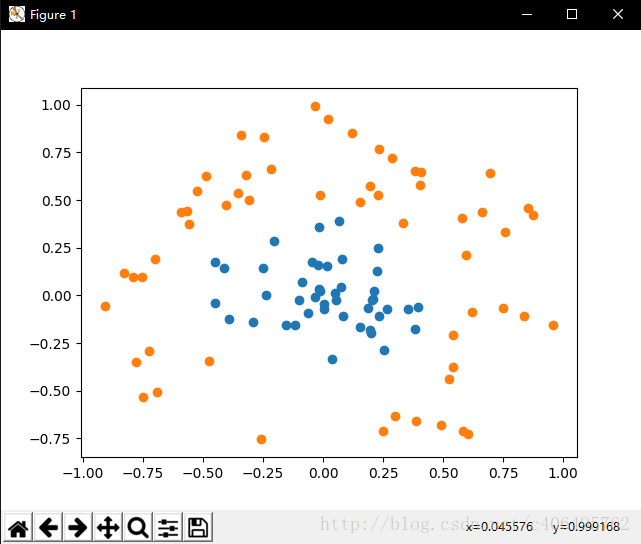
可見,資料明顯是線性不可分的。下面我們根據公式,編寫核函式,並增加初始化引數kTup用於儲存核函式有關的資訊,同時我們只要將之前的內積運算變成核函式的運算即可。最後編寫testRbf()函式,用於測試。建立svmMLiA.py檔案,編寫程式碼如下:
# -*-coding:utf-8 -*-
import matplotlib.pyplot as plt
import numpy as np
import random
"""
Author:
Jack Cui
Blog:
http://blog.csdn.net/c406495762
Zhihu:
https://www.zhihu.com/people/Jack--Cui/
Modify:
2017-10-03
"""
class optStruct:
"""
資料結構,維護所有需要操作的值
Parameters:
dataMatIn - 資料矩陣
classLabels - 資料標籤
C - 鬆弛變數
toler - 容錯率
kTup - 包含核函式資訊的元組,第一個引數存放核函式類別,第二個引數存放必要的核函式需要用到的引數
"""
def __init__(self, dataMatIn, classLabels, C, toler, kTup):
self.X = dataMatIn #資料矩陣
self.labelMat = classLabels #資料標籤
self.C = C #鬆弛變數
self.tol = toler #容錯率
self.m = np.shape(dataMatIn)[0] #資料矩陣行數
self.alphas = np.mat(np.zeros((self.m,1))) #根據矩陣行數初始化alpha引數為0
self.b = 0 #初始化b引數為0
self.eCache = np.mat(np.zeros((self.m,2))) #根據矩陣行數初始化虎誤差快取,第一列為是否有效的標誌位,第二列為實際的誤差E的值。
self.K = np.mat(np.zeros((self.m,self.m))) #初始化核K
for i in range(self.m): #計算所有資料的核K
self.K[:,i] = kernelTrans(self.X, self.X[i,:], kTup)
def kernelTrans(X, A, kTup):
"""
通過核函式將資料轉換更高維的空間
Parameters:
X - 資料矩陣
A - 單個數據的向量
kTup - 包含核函式資訊的元組
Returns:
K - 計算的核K
"""
m,n = np.shape(X)
K = np.mat(np.zeros((m,1)))
if kTup[0] == 'lin': K = X * A.T #線性核函式,只進行內積。
elif kTup[0] == 'rbf': #高斯核函式,根據高斯核函式公式進行計算
for j in range(m):
deltaRow = X[j,:] - A
K[j] = deltaRow*deltaRow.T
K = np.exp(K/(-1*kTup[1]**2)) #計算高斯核K
else: raise NameError('核函式無法識別')
return K #返回計算的核K
def loadDataSet(fileName):
"""
讀取資料
Parameters:
fileName - 檔名
Returns:
dataMat - 資料矩陣
labelMat - 資料標籤
"""
dataMat = []; labelMat = []
fr = open(fileName)
for line in fr.readlines(): #逐行讀取,濾除空格等
lineArr = line.strip().split('\t')
dataMat.append([float(lineArr[0]), float(lineArr[1])]) #新增資料
labelMat.append(float(lineArr[2])) #新增標籤
return dataMat,labelMat
def calcEk(oS, k):
"""
計算誤差
Parameters:
oS - 資料結構
k - 標號為k的資料
Returns:
Ek - 標號為k的資料誤差
"""
fXk = float(np.multiply(oS.alphas,oS.labelMat).T*oS.K[:,k] + oS.b)
Ek = fXk - float(oS.labelMat[k])
return Ek
def selectJrand(i, m):
"""
函式說明:隨機選擇alpha_j的索引值
Parameters:
i - alpha_i的索引值
m - alpha引數個數
Returns:
j - alpha_j的索引值
"""
j = i #選擇一個不等於i的j
while (j == i):
j = int(random.uniform(0, m))
return j
def selectJ(i, oS, Ei):
"""
內迴圈啟發方式2
Parameters:
i - 標號為i的資料的索引值
oS - 資料結構
Ei - 標號為i的資料誤差
Returns:
j, maxK - 標號為j或maxK的資料的索引值
Ej - 標號為j的資料誤差
"""
maxK = -1; maxDeltaE = 0; Ej = 0 #初始化
oS.eCache[i] = [1,Ei] #根據Ei更新誤差快取
validEcacheList = np.nonzero(oS.eCache[:,0].A)[0] #返回誤差不為0的資料的索引值
if (len(validEcacheList)) > 1: #有不為0的誤差
for k in validEcacheList: #遍歷,找到最大的Ek
if k == i: continue #不計算i,浪費時間
Ek = calcEk(oS, k) #計算Ek
deltaE = abs(Ei - Ek) #計算|Ei-Ek|
if (deltaE > maxDeltaE): #找到maxDeltaE
maxK = k; maxDeltaE = deltaE; Ej = Ek
return maxK, Ej #返回maxK,Ej
else: #沒有不為0的誤差
j = selectJrand(i, oS.m) #隨機選擇alpha_j的索引值
Ej = calcEk(oS, j) #計算Ej
return j, Ej #j,Ej
def updateEk(oS, k):
"""
計算Ek,並更新誤差快取
Parameters:
oS - 資料結構
k - 標號為k的資料的索引值
Returns:
無
"""
Ek = calcEk(oS, k) #計算Ek
oS.eCache[k] = [1,Ek] #更新誤差快取
def clipAlpha(aj,H,L):
"""
修剪alpha_j
Parameters:
aj - alpha_j的值
H - alpha上限
L - alpha下限
Returns:
aj - 修剪後的alpah_j的值
"""
if aj > H:
aj = H
if L > aj:
aj = L
return aj
def innerL(i, oS):
"""
優化的SMO演算法
Parameters:
i - 標號為i的資料的索引值
oS - 資料結構
Returns:
1 - 有任意一對alpha值發生變化
0 - 沒有任意一對alpha值發生變化或變化太小
"""
#步驟1:計算誤差Ei
Ei = calcEk(oS, i)
#優化alpha,設定一定的容錯率。
if ((oS.labelMat[i] * Ei < -oS.tol) and (oS.alphas[i] < oS.C)) or ((oS.labelMat[i] * Ei > oS.tol) and (oS.alphas[i] > 0)):
#使用內迴圈啟發方式2選擇alpha_j,並計算Ej
j,Ej = selectJ(i, oS, Ei)
#儲存更新前的aplpha值,使用深拷貝
alphaIold = oS.alphas[i].copy(); alphaJold = oS.alphas[j].copy();
#步驟2:計算上下界L和H
if (oS.labelMat[i] != oS.labelMat[j]):
L = max(0, oS.alphas[j] - oS.alphas[i])
H = min(oS.C, oS.C + oS.alphas[j] - oS.alphas[i])
else:
L = max(0, oS.alphas[j] + oS.alphas[i] - oS.C)
H = min(oS.C, oS.alphas[j] + oS.alphas[i])
if L == H:
print("L==H")
return 0
#步驟3:計算eta
eta = 2.0 * oS.K[i,j] - oS.K[i,i] - oS.K[j,j]
if eta >= 0:
print("eta>=0")
return 0
#步驟4:更新alpha_j
oS.alphas[j] -= oS.labelMat[j] * (Ei - Ej)/eta
#步驟5:修剪alpha_j
oS.alphas[j] = clipAlpha(oS.alphas[j],H,L)
#更新Ej至誤差快取
updateEk(oS, j)
if (abs(oS.alphas[j] - alphaJold) < 0.00001):
print("alpha_j變化太小")
return 0
#步驟6:更新alpha_i
oS.alphas[i] += oS.labelMat[j]*oS.labelMat[i]*(alphaJold - oS.alphas[j])
#更新Ei至誤差快取
updateEk(oS, i)
#步驟7:更新b_1和b_2
b1 = oS.b - Ei- oS.labelMat[i]*(oS.alphas[i]-alphaIold)*oS.K[i,i] - oS.labelMat[j]*(oS.alphas[j]-alphaJold)*oS.K[i,j]
b2 = oS.b - Ej- oS.labelMat[i]*(oS.alphas[i]-alphaIold)*oS.K[i,j]- oS.labelMat[j]*(oS.alphas[j]-alphaJold)*oS.K[j,j]
#步驟8:根據b_1和b_2更新b
if (0 < oS.alphas[i]) and (oS.C > oS.alphas[i]): oS.b = b1
elif (0 < oS.alphas[j]) and (oS.C > oS.alphas[j]): oS.b = b2
else: oS.b = (b1 + b2)/2.0
return 1
else:
return 0
def smoP(dataMatIn, classLabels, C, toler, maxIter, kTup = ('lin',0)):
"""
完整的線性SMO演算法
Parameters:
dataMatIn - 資料矩陣
classLabels - 資料標籤
C - 鬆弛變數
toler - 容錯率
maxIter - 最大迭代次數
kTup - 包含核函式資訊的元組
Returns:
oS.b - SMO演算法計算的b
oS.alphas - SMO演算法計算的alphas
"""
oS = optStruct(np.mat(dataMatIn), np.mat(classLabels).transpose(), C, toler, kTup) #初始化資料結構
iter = 0 #初始化當前迭代次數
entireSet = True; alphaPairsChanged = 0
while (iter < maxIter) and ((alphaPairsChanged > 0) or (entireSet)): #遍歷整個資料集都alpha也沒有更新或者超過最大迭代次數,則退出迴圈
alphaPairsChanged = 0
if entireSet: #遍歷整個資料集
for i in range(oS.m):
alphaPairsChanged += innerL(i,oS) #使用優化的SMO演算法
print("全樣本遍歷:第%d次迭代 樣本:%d, alpha優化次數:%d" % (iter,i,alphaPairsChanged))
iter += 1
else: #遍歷非邊界值
nonBoundIs = np.nonzero((oS.alphas.A > 0) * (oS.alphas.A < C))[0] #遍歷不在邊界0和C的alpha
for i in nonBoundIs:
alphaPairsChanged += innerL(i,oS)
print("非邊界遍歷:第%d次迭代 樣本:%d, alpha優化次數:%d" % (iter,i,alphaPairsChanged))
iter += 1
if entireSet: #遍歷一次後改為非邊界遍歷
entireSet = False
elif (alphaPairsChanged == 0): #如果alpha沒有更新,計算全樣本遍歷
entireSet = True
print("迭代次數: %d" % iter)
return oS.b,oS.alphas #返回SMO演算法計算的b和alphas
def testRbf(k1 = 1.3):
"""
測試函式
Parameters:
k1 - 使用高斯核函式的時候表示到達率
Returns:
無
"""
dataArr,labelArr = loadDataSet('testSetRBF.txt') #載入訓練集
b,alphas = smoP(dataArr, labelArr, 200, 0.0001, 100, ('rbf', k1)) #根據訓練集計算b和alphas
datMat = np.mat(dataArr); labelMat = np.mat(labelArr).transpose()
svInd = np.nonzero(alphas.A > 0)[0] #獲得支援向量
sVs = datMat[svInd]
labelSV = labelMat[svInd];
print("支援向量個數:%d" % np.shape(sVs)[0])
m,n = np.shape(datMat)
errorCount = 0
for i in range(m):
kernelEval = kernelTrans(sVs,datMat[i,:],('rbf', k1)) #計算各個點的核
predict = kernelEval.T * np.multiply(labelSV,alphas[svInd]) + b #根據支援向量的點,計算超平面,返回預測結果
if np.sign(predict) != np.sign(labelArr[i]): errorCount += 1 #返回陣列中各元素的正負符號,用1和-1表示,並統計錯誤個數
print("訓練集錯誤率: %.2f%%" % ((float(errorCount)/m)*100)) #列印錯誤率
dataArr,labelArr = loadDataSet('testSetRBF2.txt') #載入測試集
errorCount = 0
datMat = np.mat(dataArr); labelMat = np.mat(labelArr).transpose()
m,n = np.shape(datMat)
for i in range(m):
kernelEval = kernelTrans(sVs,datMat[i,:],('rbf', k1)) #計算各個點的核
predict=kernelEval.T * np.multiply(labelSV,alphas[svInd]) + b #根據支援向量的點,計算超平面,返回預測結果
if np.sign(predict) != np.sign(labelArr[i]): errorCount += 1 #返回陣列中各元素的正負符號,用1和-1表示,並統計錯誤個數
print("測試集錯誤率: %.2f%%" % ((float(errorCount)/m)*100)) #列印錯誤率
def showDataSet(dataMat, labelMat):
"""
資料視覺化
Parameters:
dataMat - 資料矩陣
labelMat - 資料標籤
Returns:
無
"""
data_plus = [] #正樣本
data_minus = [] #負樣本
for i in range(len(dataMat)):
if labelMat[i] > 0:
data_plus.append(dataMat[i])
else:
data_minus.append(dataMat[i])
data_plus_np = np.array(data_plus) #轉換為numpy矩陣
data_minus_np = np.array(data_minus) #轉換為numpy矩陣
plt.scatter(np.transpose(data_plus_np)[0], np.transpose(data_plus_np)[1]) #正樣本散點圖
plt.scatter(np.transpose(data_minus_np)[0], np.transpose(data_minus_np)[1]) #負樣本散點圖
plt.show()
if __name__ == '__main__':
testRbf()執行結果如下圖所示:
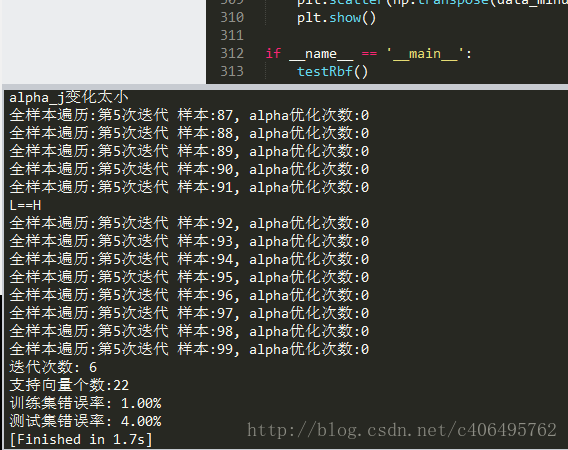
可以看到,訓練集錯誤率為1%,測試集錯誤率都是4%,訓練耗時1.7s。可以嘗試更換不同的K1引數以觀察測試錯誤率、訓練錯誤率、支援向量個數隨k1的變化情況。你會發現K1過大,會出現過擬合的情況,即訓練集錯誤率低,但是測試集錯誤率高。
五 klearn構建SVM分類器
在第一篇文章中,我們使用了kNN進行手寫數字識別。它的缺點是儲存空間大,因為要保留所有的訓練樣本,如果你的老闆讓你節約這個記憶體空間,並達到相同的識別效果,甚至更好。那這個時候,我們就要可以使用SVM了,因為它只需要保留支援向量即可,而且能獲得可比的效果。
如果對這個資料集不瞭解的,可以先看看我的第一篇文章:
首先,我們先使用自己用python寫的程式碼進行訓練。建立檔案svm-digits.py檔案,編寫程式碼如下:
# -*-coding:utf-8 -*-
import matplotlib.pyplot as plt
import numpy as np
import random
"""
Author:
Jack Cui
Blog:
http://blog.csdn.net/c406495762
Zhihu:
https://www.zhihu.com/people/Jack--Cui/
Modify:
2017-10-03
"""
class optStruct:
"""
資料結構,維護所有需要操作的值
Parameters:
dataMatIn - 資料矩陣
classLabels - 資料標籤
C - 鬆弛變數
toler - 容錯率
kTup - 包含核函式資訊的元組,第一個引數存放核函式類別,第二個引數存放必要的核函式需要用到的引數
"""
def __init__(self, dataMatIn, classLabels, C, toler, kTup):
self.X = dataMatIn #