
[目標檢測] Faster R-CNN 深入理解 && 改進方法彙總
Faster R-CNN 從2015年底至今已經有接近兩年了,但依舊還是Object Detection領域的主流框架之一,雖然推出了後續 R-FCN,Mask R-CNN 等改進框架,但基本結構變化不大。同時不乏有SSD,YOLO等骨骼清奇的新作,但精度上依然以Faster R-CNN為最好。對於一般的通用檢測問題(例如行人檢測,車輛檢測,文字檢測),只需在ImageNet pre-train model上進行若干次 fine-tune,就能得到非常好的效果。相比於刷pascal voc,Imagenet,coco 等benchmarks,大多數人感興趣的可能是如何應用到自己的檢測目標上。
PS: 一作任少卿大神人挺帥的,回答問題還很耐心。
Faster R-CNN 主要由三個部分組成:(1)基礎特徵提取網路(2)RPN (Region Proposal Network) (3)Fast-RCNN 。其中RPN和Fast-RCNN共享特徵提取卷積層,思路上依舊延續提取proposal + 分類的思想。後人在此框架上,推出了一些更新,也主要是針對以上三點。
1. 更好的特徵網路
(1)ResNet,PVANet
ResNet CVPR2016 oral
ResNet 依然是現在最好的基礎網路,ResNeXT可能效能上比他好一點,但不是很主流,通過將Faster-RCNN中的VGG16替換成ResNet可以提高performance,不僅是detection,在segmentation,video analysis,recognition等其他領域,使用更深的ResNet都可以得到穩定的提升。
PASCAL VOC 2007 上,通過將VGG-16替換成ResNet-101,mAP從73.2%提高到76.4%, PASACAL 2012 上從70.4%提高到73.8%
值得注意的是,ResNet版本的Faster-RCNN連線方法和Baseline 版本不太一致,具體見任少卿在PAMI 2015中提到 https://arxiv.org/abs/1504.06066。以ResNet-101為例,參考下圖方式,其中res5c,atrous + fc4096 + fc4096 + fcn+1 的方式是和baseline版本一致的方式,而res4b22+res5a+res5b+rec5c+fcn+1 是最終採取的方式。這種連線方式使得ResNet-faster-rcnn成為全卷積結構,大大減少模型大小,同時在效能上有一定提升。
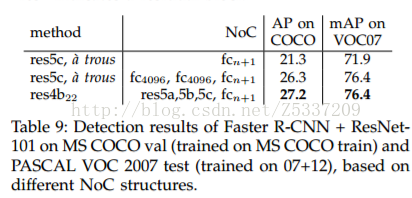
在速度方面,ResNet比VGG16更慢,同時需要訓練的次數也更多,個人實驗結果vgg16 baseline版本訓練一輪耗時1.5s,ResNet版本一輪耗時2.0s,同時記憶體佔用量也遠遠大於VGG16,大概四五倍,沒有12G的GPU就不要想用了。
PVANet NIPS2016 workshop
PVANet是幾個韓國人鼓搗出來的一個更深但快速的基礎網路,在VOC2012上效果達到82.5%,接近Faster R-CNN + ResNet-101 +++ 和 R-FCN的結果,但是速度上快非常多。實際驗證結果,訓練和測試速度都比baseline版本快一倍左右。不過,這個網路非常難訓練,收斂困難,loss會比較大,選用的訓練方法是plateau,在一些比較困難的任務上,大概得好幾倍的迭代次數才能達到和VGG16效能相當程度。另外,82.5%這個效能也並非全部得益於PVANet,文章中把anchor數量增加到40多個,還做了一些小改動。個人認為,PVANet的速度廣受認可,但效能頂多和VGG16相當,不如ResNet。

(2) Hierarchy Feature
代表作有HyperNet,同樣的思想在SSD和FCN中也有用到,將多層次的卷積網路feature map接在一起
HpyerNet
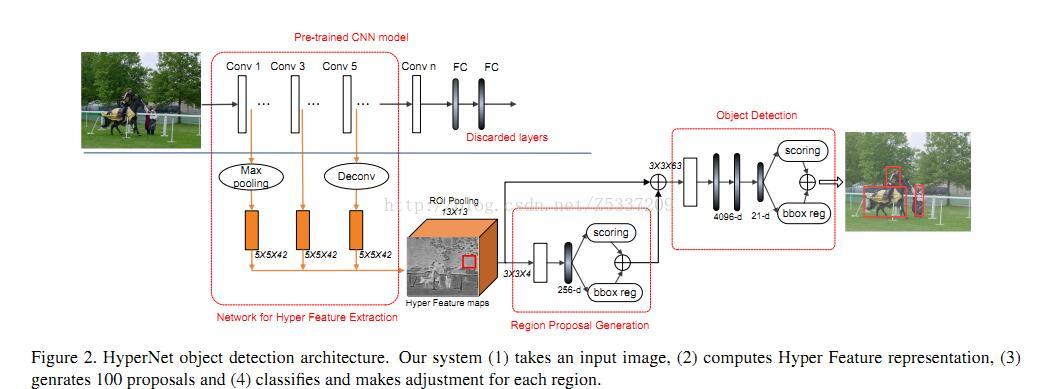
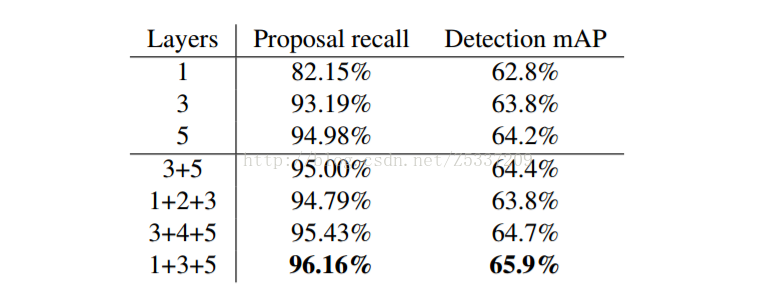
以VGG-16為例,將conv1,conv3,conv5三層接在一起,形成一個Hyper Feature,以Hpyer Feature maps 代替原有的conv5_3,用於RPN和Fast-RCNN。該文章問題出發點針對小目標和定位精度,由於CNN的本身特點,隨著層數加深,特徵變得越來越抽象和語義,但解析度卻隨之下降。Conv5_3 每一個畫素點對應的stride = 16 pixel,如果能在conv3_3上做預測,一個畫素點對應的stride = 4 pixel,相當於可以獲得更好的精度,而conv5_3代表的語義資訊對分類有幫助,結合下來,相當於一個定位精度和分類精度的折中。下圖是以AlexNet為例,不同層接法在Pascal VOC 2007上的結果,可以看到,1+3+5會取得不錯的效果。
2. 更精準更精細的RPN
(1)FPN
(2)more anchors
3. ROI分類方法
(1)PS-ROI-POOLING
R-FCN:
(2)ROI-Align & multi-task benefits
Mask R-CNN :
(3)multi-layer roi-pooling
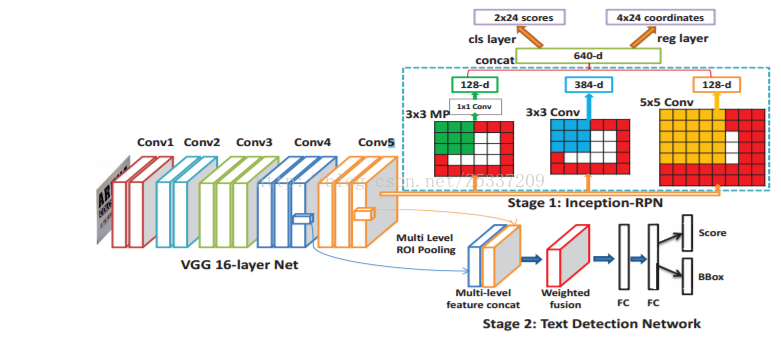
DeepText:
一篇將Faster RCNN應用在文字檢測的文章,裡面的contribution比較瑣碎,但有一點小改進經驗證過相當有效,就是roi分別在conv4,conv5上做roi-pooling,合併後再進行分類。這樣基本不增加計算量,又能利用更高解析度的conv4。
4. sample and post-process
(1)Hard example mining
OHEM
Paper: Code:
(2)GAN
A-Fast-RCNN
這篇文章比較新穎,蹭上了GAN的熱點,利用GAN線上產生一些遮擋形變的positive sample。與Fast-RCNN比較,在VOC2007上,mAP增加了2.3%,VOC2012上增加了2.6%。
(3)soft-NMS
Soft-NMS (Improving Object Detection With One Line of Code)
該篇文章主要focus在後處理NMS上,不得不承認,對於很多問題,後處理的方法會對結果產生幾個點的影響。雖然我自己試驗過,在我的任務上,Soft-NMS得到的結果和NMS完全一致,該後處理方式可能不具備推廣性,但是好在嘗試起來非常容易,代價也很小,只需要替換一個函式就可以,所以大家不妨可以試驗一下。