
Faster R-CNN演算法理解
1、文章概述
Faster r-cnn是2016年提出的文章,有兩個模型,一個是ZF模型,一個是VGG模型。在VOC07+12資料集中,ZF模型的mAP值達到59.9%,17fps; VGG模型的mAP值達到73.2%,5fps。
Faster r-cnn可以two-stage的代表,可以看做是RPN網路+Fast r-cnn的結合。Region proposal 階段由RPN網路完成,創新性地提出了“Anchor”的思路用以解決多Scale、aspect ratio影象目標的輸入問題。RPN網路提取ROI區域後,送入檢測網路(比如Fast rcnn)再進行分類和迴歸。在訓練階段提出了“four -step”來交替訓練RPN網路和detect網路,使兩個網路共享卷積層(即基礎網路的卷積層部分)。
具體的整個Faster R-CNN的結構圖如下面兩張圖,都是描述Faster R-CNN結構的:
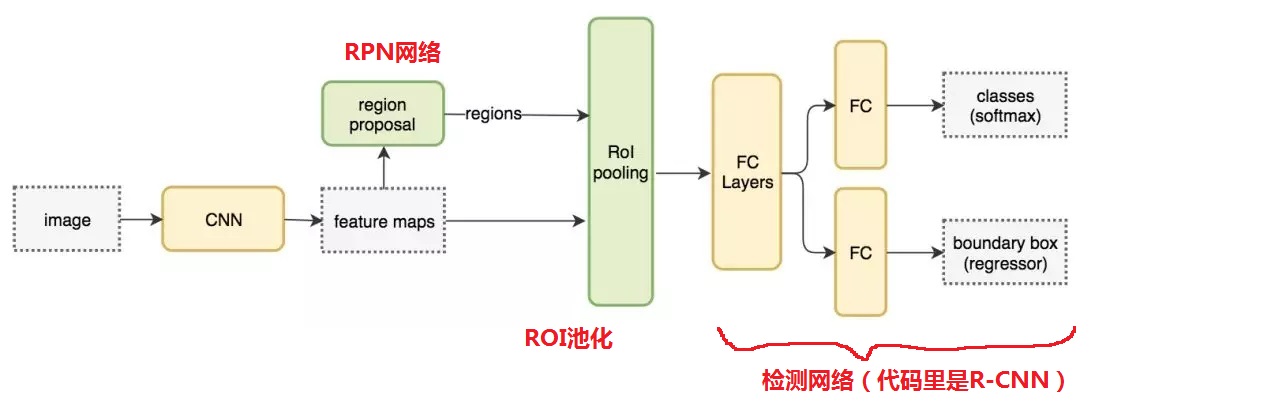

2、RPN網路
2.1 RPN網路的提出原因
Rcnn系列是典型的“two-stage”,第一個stage就是region proposal。SPPnet和Fast r-cnn在region proposal階段的時間太長,導致region proposal階段的耗時成了two-stage方法的瓶頸。SPPnet和Fast r-cnn的region proposal階段均沒有利用卷積神經網路來完成region proposal,因此效果差耗時長成了必然。 Faster r-cnn的RPN網路(卷積神經網路)用來完成region proposal提取合適的ROI區域,且RPN網路能和整個檢測網路共享卷積層,使得region proposal階段在GPU上完成,且幾乎不花費時間。
2.2 RPN網路的結構
下圖是RPN網路的結構:

其中RPN和後面的檢測網路(比如RCNN)將要共享的卷積層就是基礎網路(ZF/VGG)中的卷積層,這個所謂的“共享”在後面訓練過程中體現。
2.3 PRN的流程
RPN網路在最後卷積得到的特徵圖上(即基礎網路的最後一層)進行掃描,RPN每次與特徵圖上的3*3視窗連線,然後對映到一個低維向量(256d for ZF/512d for VGG),這個操作是在RPN網路的第一個3*3的卷積層上完成的。(具體如何對映的我沒有看原始碼,具體過程我也不清楚,看了網上的講解這一部分也沒有詳細說明,請知道的大佬賜教!

在RPN網路的每次3*3卷積滑窗的中心處產生9個anchor,用來生成RPN其網路的訓練所需要的anchor樣本。實際上anchor在40*60的卷積特徵圖上的每一個單元點上都生成。將低維向量送入兩個1*1的卷積層(一個是bbox的迴歸層reg),一個是bbox的分類層(cls)。如果RPN網路作用的卷積層的特徵圖大小是40*60,則reg層最後得到40*60*(9*4)個座標,cls層最後得到40*60*(9*2)個分類得分。這個資料不明白的可以參考部落格中最後給出的參考部落格。具體的RPN流程可以參考下圖(來自部落格:https://blog.csdn.net/qq_17448289/article/details/52871461):
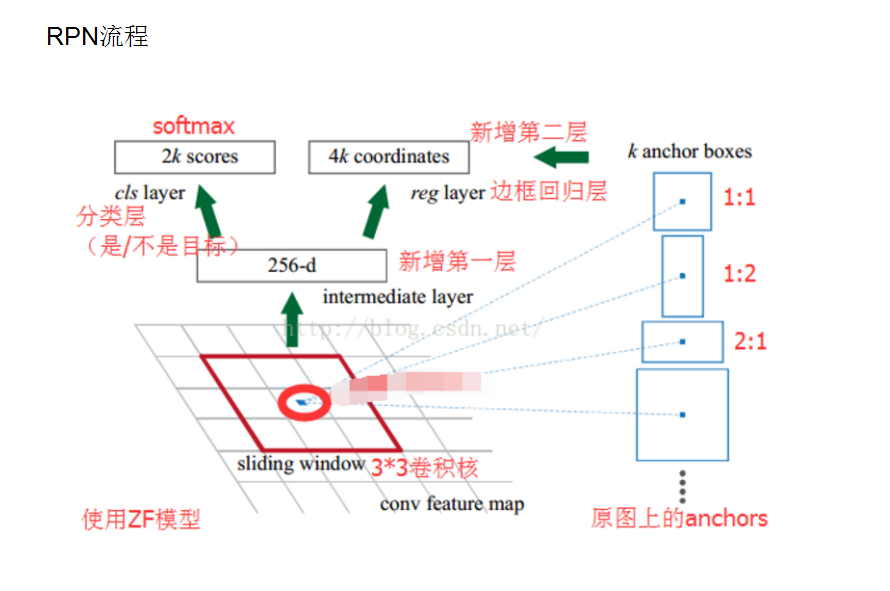
需要注意的是,上面提到的cls層和reg層後面,還要連線RPN網路相對應的損失函式層(就是文中濃墨重彩介紹的損失函式),而RPN網路提取到region proposal再送入到後面的檢測網路(程式碼裡是R-CNN網路)訓練時,損失函式是對應的檢測網路的損失函式。也就是說,全程訓練時,有兩個不同的損失函式指導整個Faster R-CNN網路的訓練。具體網路結構可閱讀作者提供的Caffe程式碼裡的train.prototxt:Caffe程式碼裡的對應的train.prototxt
3、Anchors
anchors被翻譯成了“錨點”,後面的SSD的default boxes的思想應該是借鑑了anchor的思想。區別在於:Faster R-CNN的anchors僅在60*40的那一層的feature maps上提取,特徵圖的尺度單一;而SSD的default boxes在多個卷積層的feature maps上提取,且default boxes的scale和aspect ratio隨著卷積層層數的不同而不同,也可以看成是特徵金字塔的一種形式。
3.1 Anchors的生成
Anchors是為了訓練RPN網路提供樣本的。說是在RPN網路的每個3*3的視窗中心生成一系列anchors,實際上60*40的卷積特徵圖上每個點都生成了一系列的anchors。文中anchors預設有9個不同的形態:三種面積{128*128,256*256,512*512} * 三種長寬比例{1:1, 1:2, 2:1}。注意這裡的面積是對應到“短邊resize到600的重新縮放的原始影象”。這一步在60*40的feature maps上會生成60*40*9=21600,大約2W個anchors。附一張每個部落格都會提到的描述anchors的圖:
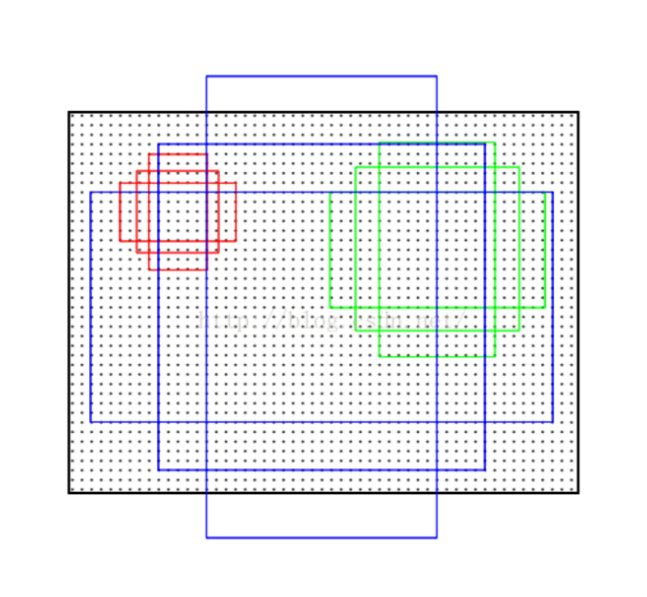
上圖的這些類似火龍果的籽的點就是生成anchors的中心,一種顏色的框對應一個生成anchor的中心,上圖三種顏色的框對應的三個不同的生成anchors的中心。
3.2 anchors的正負類別標定
既然用Anchors訓練RPN,生成了2W多個anchors肯定有正類、負類之分,具體的正、負類別標定方法是:
Positive Labels:
(1)Anchors與GT(Ground Truth)有最高IOU重疊的anchors標為正類(也許IOU不到0.7);
(2)與任意GT的IOU大於0.7的anchors均可標為正類;
Negative Labels:
(1)與所有GT的IOU均小於0.3的anchors標為負類;
注意:對於既不是正類也不是負類的anchors,以及跨越影象邊界的anchors(cross - boundary anchors)均捨棄,對訓練目標不起作用。經過去掉“跨越影象邊界的anchors”這一操作後,anchors的數目由2W變為了6000(對於一副feature map)。
3.3 Anchors訓練選擇
得到上面6000個正負類別標籤的anchors後,要將anchors再進行挑選用來訓練RPN。為了減少計算量,從上面3.2中提到的6000個anchors中隨機挑選256個anchors,作為一個mini-batch的計算量,且256個anchors中,正負樣例的比例為1:1.如果一個mini-batch中正例太少,則由負例填充,湊足256個anchors作為更新一次RPN網路權重的mini-batch。
3.4 生成的ROI區域的過濾
RPN網路訓練好後,由RPN網路生成的ROI送入後面的檢測網路(Faster R-CNN程式碼中是RCNN網路)。但是生成的region proposals中有很多是與周圍的ROI高度重疊的。解決方法是用NMS(非極大值抑制),根據cls的scores。NMS中的IOU的閾值設定為0.7,NMS後大約剩下2000個ROIs。之後,再在這2000個ROIs中選取前N個ROIS(根據得分取前N個)用於檢測網路。
注意:剛讀論文的時候要區分anchors和RPN生成的ROIs。anchors僅用來訓練RPN網路,訓練好的RPN網路根據原圖生成對應的ROIs送入檢測網路。
3.5 ROI pooling
RPN網路生成的ROI區域和之前的feature maps一起作用完成ROI pooling過程,說簡單點,就是根據ROI將feature maps中的對應區域摳出來,再resize到相應的輸出尺寸,以下面的例子為例:
為簡潔起見,我們先將 8×8 特徵圖轉換為預定義的 2×2 大小。
- 下圖左上角:特徵圖。
- 右上角:將 ROI(藍色區域)與特徵圖重疊。
- 左下角:將 ROI 拆分為目標維度。例如,對於 2×2 目標,我們將 ROI 分割為 4 個大小相似或相等的部分。
- 右下角:找到每個部分的最大值,得到變換後的特徵圖。

輸入特徵圖(左上),輸出特徵圖(右下),ROI (右上,藍色框)。
按上述步驟得到一個 2×2 的特徵圖塊,可以饋送至分類器和邊界框迴歸器中。
注意:每個anchor經過迴歸後對應到原圖,然後再對應到feature map經過roi pooling後輸出7*7的大小的map;anchors要對應到feature map上。
3.6 三種尺度
(1)原圖尺度:原始輸入影象大小,不受限制,不影響效能。即製作好的VOC格式的資料集的訓練影象大小;
(2)歸一化尺度:就是文中提到的“短邊resize到600”,在上面原圖的基礎上好像resize到了1000*600,。anchors就是根據這個尺度確定的最終大小三種面積{128*128,256*256,512*512},後面生成的ROIs也是對映到的這個尺度上;
(3)網路輸入尺度:輸入進基礎網路的尺度,程式碼中是224*224。應該也是由原圖尺度resize得到的。
注意:anchor對映的尺度是歸一化尺度1000*600,而不是網路輸入尺度224*224,可以參照文中Tabel 1中的資料。
4、Faster R-CNN的損失函式
介紹了Fast rcnn的多工損失函式和Fast rcnn的損失函式。

引數解釋:

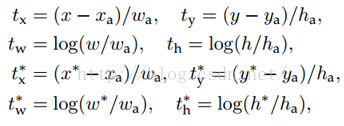

5、訓練整個網路(RPN網路+檢測網路)
參見figure2可知,RPN和檢測網路結構上前面都共有一個基礎網路,因此RPN和檢測網路訓練時應共享基礎網路卷積引數層,用交替訓練(alternating training),達到卷積層特徵共享。文中作者提出了“四步”訓練法,具體地:
(1)訓練RPN,RPN網路由ImageNet預訓練的模型初始化;
(2)利用RPN生成ROIs,訓練檢測網路。檢測網路(R-CNN)同樣也由ImageNet預訓練的模型初始化,此時RPN和RCNN還沒有共享卷積層;這一步是對檢測網路層的引數微調;
(3)用RCNN初始化RPN,初始化RCNN和RPN共享的卷積層的引數,微調不共享的和其他層的引數(即微調RPN獨有的層),到這一步RPN和RCNN共享引數了;
(4)訓練R-CNN,保持其與RPN共享的卷積層引數不變,微調不共享層(即R-CNN層)的引數;
訓練超引數設定和實驗結果請參照原文。
參考文章:
這兩篇是目標檢測的綜述,其中第一篇詳細對比了R-CNN、Fast R-CNN、Faster R-CNN和R-FCN。
下面幾篇是閱讀文章時看的部落格: