
利用caffe識別水杯
由於專案需求,需要識別水杯,於是我想能不能只放杯子資料,然後將輸出變為1,就可以訓練了,實際上,根本行不通,因為你的資料對應你的標籤無論怎麼變換都是隻有那個唯一標籤對應,根本找不到其他的,這樣的結果直接導致你的模型無論是杯子還是其他,都是1.0正確率的。看下面這圖片就應該懂了
無需多言,根本不存在所謂的單標籤,那麼應該怎麼辦,既然只讓我識別杯子,我想能否用others和cup兩類,但是我發現這樣的模型也不是很靠譜,主要在於對others的資料來源不好掌握,所以就決定對杯子進行分類。具體結果我們下次再講。。。我決定實驗一波
當我做了簡單的二分類,發現由於杯子種類的繁多,很難以一個模型來給出,當我將各種杯子放一起進行訓練,並且其他類是一個其他種類時,迭代結果如下:

loss一直居高不下,且accuracy很低,我們推測資料有問題,那麼我們嘗試給杯子歸歸類,來看一下迭代結果
我將杯子歸為五類,但是迭代很吃力,沒有gpu真的很慢而且loss居高不下,我想,這應該不是分類的問題了,而是資料來源的問題,可能是圖片的質量導致的,所以我將圖片resize乘50*50來看看結果。。。
這裡遇到一個錯誤:Check failed: datum_height >= crop_size (50 vs. 227) 我選用網路是alexnet,原因在於該網路預設圖片格式位227*227,而我在resize 是50,所以該網路中的crop——size資料即可。
博主在對圖片進行裁剪之後再來分類,主要為了讓目標儘可能的佔據圖片,但是做分類時出現如下錯誤
Cannot copy param 0 weights from layer 'fc6'; shape mismatch. Source param shape is 4096 256 (1048576); target param shape is 4096 9216 (37748736). To learn this layer's parameters from scratch rather than copying from a saved net, rename the layer. *** Check failure stack trace: ***
shape不匹配啊,檢視deploy檔案,修該shape,我們將圖片大小改為轉二進位制的大小,成功。。。
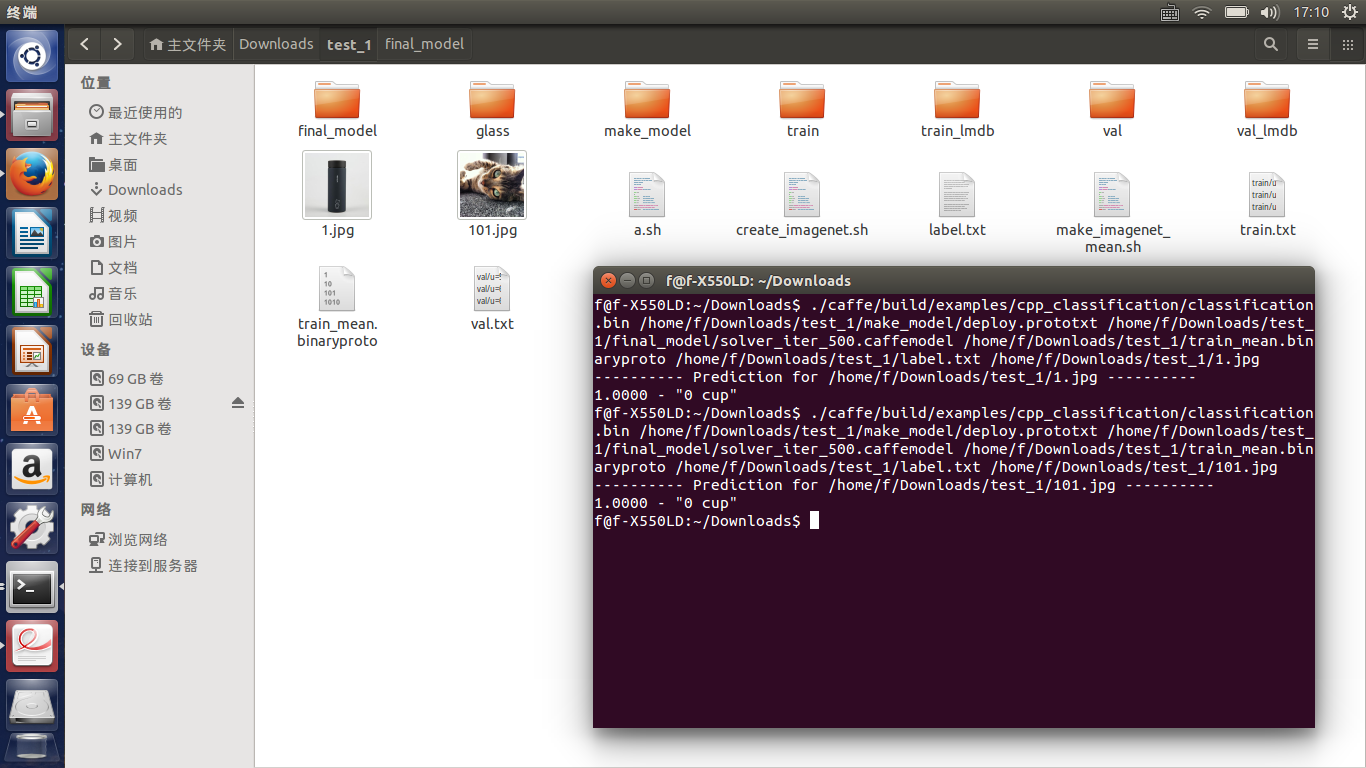
當我分類結束測試的時候,發現效果還是很不理想,請看結果,我測試的都是杯子,但會有如下:
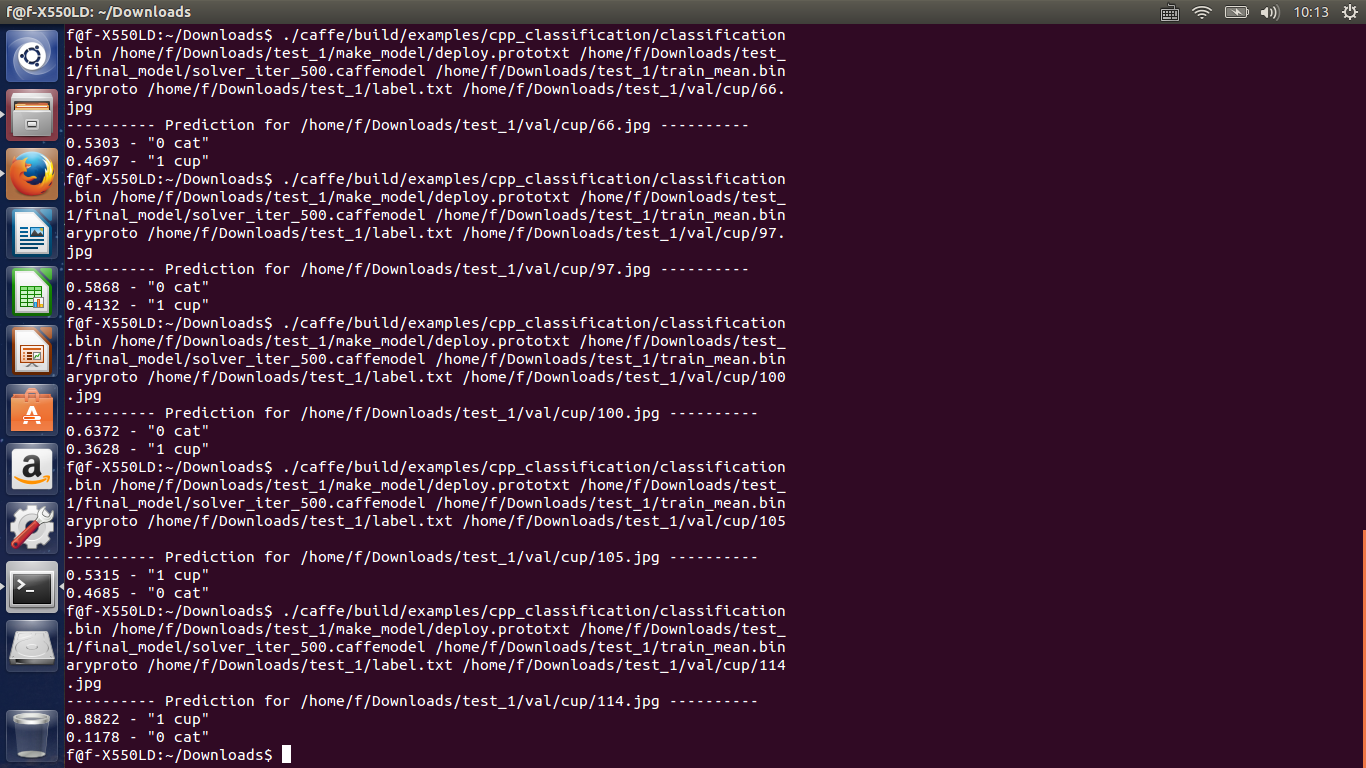
出現了大量的誤匹配以及低命中率,我把學習率一次調低依舊沒有解決,。。。一時間不知咋辦
網上看到一般可以通過data augment來增加資料從而減少過擬合,我用的網路是alexnet,也許對於二分類太複雜了,所以試著採用資料增強來看看結果。主要有一下幾類:
- 旋轉 | 反射變換(Rotation/reflection): 隨機旋轉影象一定角度; 改變影象內容的朝向;
- 翻轉變換(flip): 沿著水平或者垂直方向翻轉影象;
- 縮放變換(zoom): 按照一定的比例放大或者縮小影象;
- 平移變換(shift): 在影象平面上對影象以一定方式進行平移;
可以採用隨機或人為定義的方式指定平移範圍和平移步長, 沿水平或豎直方向進行平移. 改變影象內容的位置; - 尺度變換(scale): 對影象按照指定的尺度因子, 進行放大或縮小; 或者參照SIFT特徵提取思想, 利用指定的尺度因子對影象濾波構造尺度空間. 改變影象內容的大小或模糊程度;
- 對比度變換(contrast): 在影象的HSV顏色空間,改變飽和度S和V亮度分量,保持色調H不變. 對每個畫素的S和V分量進行指數運算(指數因子在0.25到4之間), 增加光照變化;
- 噪聲擾動(noise): 對影象的每個畫素RGB進行隨機擾動, 常用的噪聲模式是椒鹽噪聲和高斯噪聲;
- 顏色變換(color): 在訓練集畫素值的RGB顏色空間進行PCA, 得到RGB空間的3個主方向向量,3個特徵值, p1, p2, p3, λ1, λ2, λ3. 對每幅影象的每個畫素
這是參見網上的一些大佬的結果,決定試著做噪聲和對比度變換來增加資料。具體測試結果以後見。。。
我對資料分別添加了椒鹽噪聲和高斯噪聲,還對進行旋轉變換,總共增加了4倍的資料量,結果還是很喜人了,在迭代600次,accuracy是0.9還是比較不錯的,過擬合的問題得到了比較好的解決,雖然最後1000次迭代降到了0.84,初步推測是學習率的問題,整個迭代都是0.01,下次調一下看看會怎樣。測試結果如下
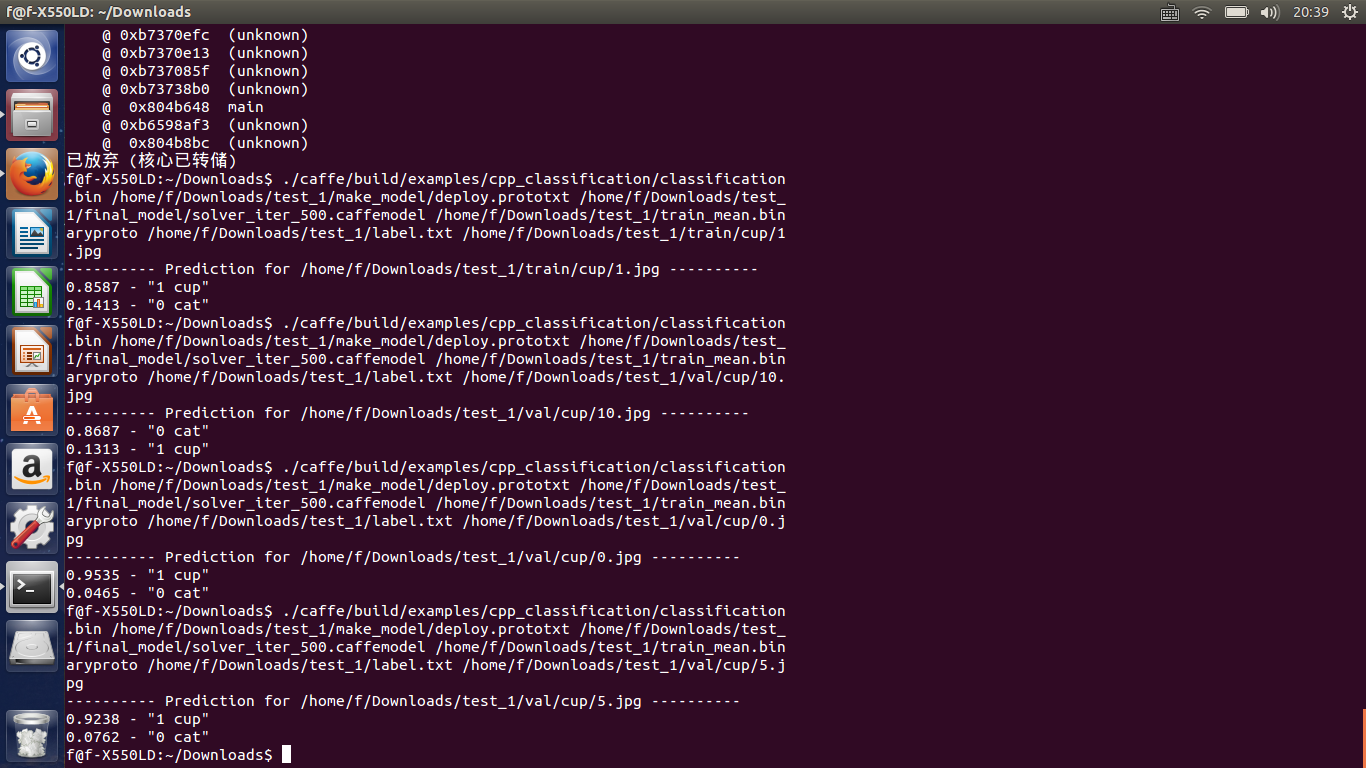
可以看到有些杯子識別率還是不錯的,但是同樣有誤識別,這有待我進一步學習深度學習後進行探究和改正,目前對此問題有的想法是調參和增加資料量。。。
怎麼說呢,經過這次嘗試,還是對深度學習有了一些體會的,也對下一步的打算有了比較好的認識,同樣,本文依舊沒有結束,對於後期專案的完善我也會第一時間的進行更新,也謝謝讀我部落格的朋友。
對於後期的處理,我調整了weight——decay引數,我改成了0.0002,我是考慮模型不夠複雜時,降低權值來得到比較好的效果,那麼迭代結果也是比較好的,1000次迭代成功率0.9還是比較好的。