
win10+only-cpu利用Caffe框架測試mnist資料集
但是從這裡下載的資料集需要進行格式轉換(轉換方法以後會說到的),所以我現在選擇下載現成的資料集如此zip檔案

解壓後得到這麼兩個資料夾:

(附:這了兩個資料夾中的內容:
將這兩個資料夾放入D:/caffe-master/examples/mnist中(因為我把caffe-master解壓在了D盤根目錄下,大家自己尋找自己的caffe-master就可以了),
效果如圖

二、修改相關檔案
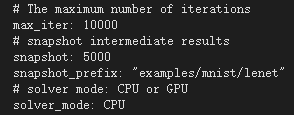
①在D:\caffe-master\examples\mnist中,用VS2013開啟lenet_solver..protptxt檔案,如圖:

,拉到最後一行做如下修改:
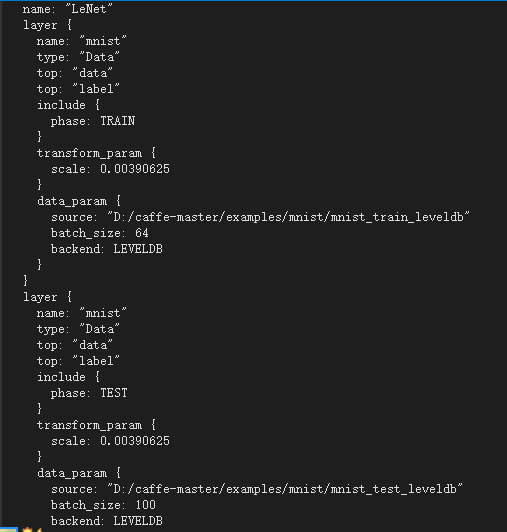
②在D:\caffe-master\examples\mnist中,用VS2013開啟lenet_train_test.prototxt檔案,如圖:
三、返回caffe-master所在目錄中,新建一個txt檔案,輸入如下程式碼,效果如圖
Build\x64\Debug\caffe.exe train --solver=examples\mnist\lenet_solver.prototxt
Pause

然後將字尾改為bat,效果如圖,然後雙擊此檔案,就進入訓練了,效果如圖

此過程caffe採用的GLOG庫內方法列印的資訊,這個庫主要是起記錄日誌的功能,方便出現問題時查詢根源,具體格式為:
【日期】【時間】【程序號】【檔名】【行號】
四、等待訓練結束,如下圖:
①
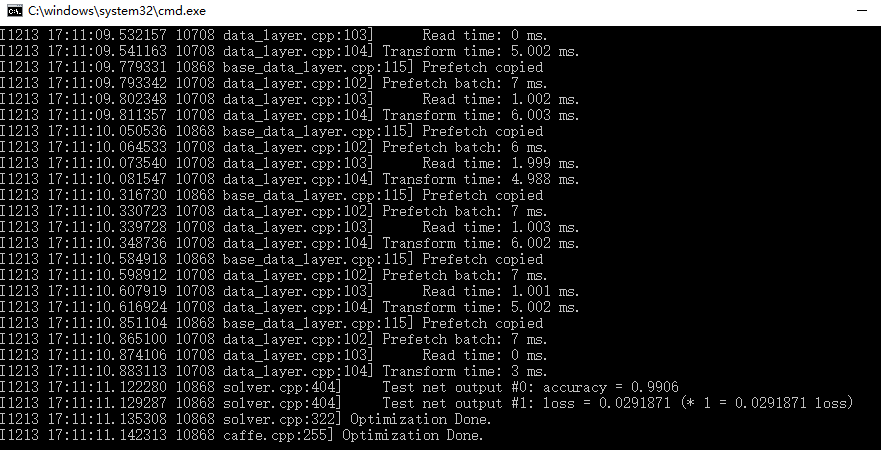
上面顯示了訓練精確率0.996
損失函式0.0291871
②在訓練過程中:
中間有些比較長的部分,可以通過拉動視窗右側小條找到

下圖:

顯示當前迭代次數和以及損失值,訓練過程中不產生精確率accuracy
③當迭代次數達到lenet_solver.prototxt定義的max_iter時,就可以認為訓練結束了,並且在訓練結束後,在D:\caffe-master\examples\mnist資料夾中會多出如下四個檔案:
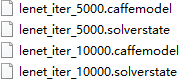
這時產生訓練出的模型(檔案字尾名為caffemodel和solverstate),它們分別是訓練至一半(
五、測試資料集(摘自網路)
接下來就可以利用模型進行測試了,關於測試的方法按照以上教程還是選擇bat檔案,當然python、matlab更為方便,比如可以迅速把識別錯誤的圖片顯示出來。
①產生均值檔案mean.binaryproto
在進行分類之前首先需要產生所有圖片平均值圖片,真正分類時的每個圖片都會先減去這張平均值圖片再進行分類。這樣的處理方式能夠提升分類的準確率。
產生均值檔案的方法是利用解決方案中的compute_image_mean.exe,位於目錄D:/caffe-master/Build/x64/Debug下。回到caffe-master根目錄下建立一個mnist_mean.txt,寫入如下內容:
Build\x64\Debug\compute_image_mean.exe examples\mnist\mnist_train_leveldb mean.binaryproto --backend=leveldb
pause
效果如圖:

然後把.txt字尾改為.bat,檔案如圖所示:

然後雙擊執行(其實寫了那麼多bat檔案也因該有體會了,只要指定的路徑正確就行,不一定非要放在caffe-master根目錄下)。正確執行的話會在根目錄下產生一個mean.binaryproto,也就是我們所需要的均值檔案,如右圖所示:

接著為了使用均值檔案需要稍微修改下層的定義(其實還是添加了如下圖兩行程式碼mean file的兩行程式碼),然後用VS2013開啟D:\caffe-master\examples\mnist\lenet_train_test.prototxt
並作如下修改,如圖所示:
儲存退出
至此,均值檔案的預處理部分處理完畢,下面就可以進行測試了(至於為什麼這樣預處理,我也在學習中,知道的朋友還麻煩在下面評論區說一下,謝謝啦)。
②利用mnist資料集進行測試
這部分比較簡單,因為之前生成的caffe.exe就可以直接用來進行測試。同樣地在caffe-master根目錄下新建mnist_test.txt,並寫入如下內容(其中間斷處都為一個空格)
內容如下:
.\Build\x64\Debug\caffe.exe test --model=examples/mnist/lenet_train_test.prototxt -weights=examples/mnist/lenet_iter_10000.caffemodel
pause
效果如圖所示:
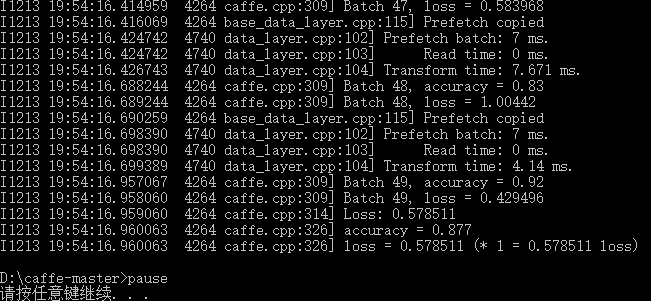
注意:這裡的測試,指的是把訓練出的模型,應用在剛才的訓練集上,看一下測試精度。
③這一步往後就比較實用了,先介紹如何製作手寫數字的單張測試樣本。
必須使用經過二值化後的圖片
把轉換好的二值影象拷貝到D:\caffe-master\examples\mnist\
在D:\caffe-master\examples\mnist下建立標籤檔案synset_words.txt,如圖所示
裡面輸入如圖所示:

④呼叫classification.exe去識別某張圖片,D:\caffe-master目錄新建mnist_class.bat
D:\caffe-master\Build\x64\Debug\classification.exe D:\caffe-master\examples\mnist\lenet.prototxt D:\caffe-master\examples\mnist\lenet_iter_10000.caffemodel D:\caffe-master\mean.binaryproto D:\caffe-master\examples\mnist\synset_words.txt D:\caffe-master\examples\mnist\binarybmp\0.bmp
pause
注意:此處使用的lenet.prototxt是一個deploy檔案,這個檔案只是高速分類程式(mnist_classification.exe)網路結構是怎麼樣子的,不需要反向計算,不需要計算誤差。
然後得到如圖所示結果:

解釋一下結果:在最後的分類結果中,一共顯示了5行(據說程式中可以控制,但是我並沒有找到),表示輸入的這張圖片與它最像的有這5類,前面的0和1表示得分,這5行前面的得分和應該為1,也就是1+0+0+0+0=1,第一項得分最高,所以識別此圖為6.
⑤接下來我打算自己用畫圖做一個試一下,
這是我用畫圖做的,如圖所示

怕格式(包括大小以及畫素問題)不正確,我用它的圖片集修改的,然後輸入到網路中,也就是在上一步中建立的mnist_class.bat中用記事本開啟,做如圖所示修改:

儲存退出,雙擊mnist_class.bat,開始執行,得到如下結果:
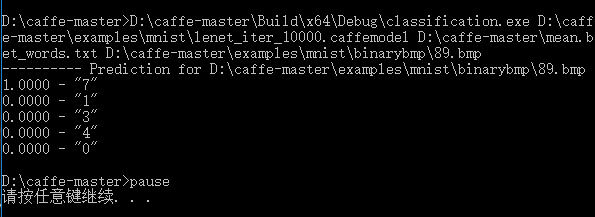
“7”得分最高,所以網路識別圖片中的數字為7
自己製作資料整合功!