
Hadoop學習筆記—12.MapReduce中的常見演算法
一、MapReduce中有哪些常見演算法
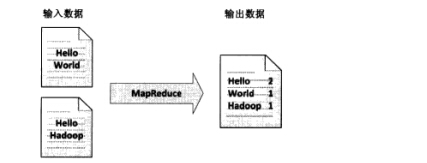
(1)經典之王:單詞計數
這個是MapReduce的經典案例,經典的不能再經典了!
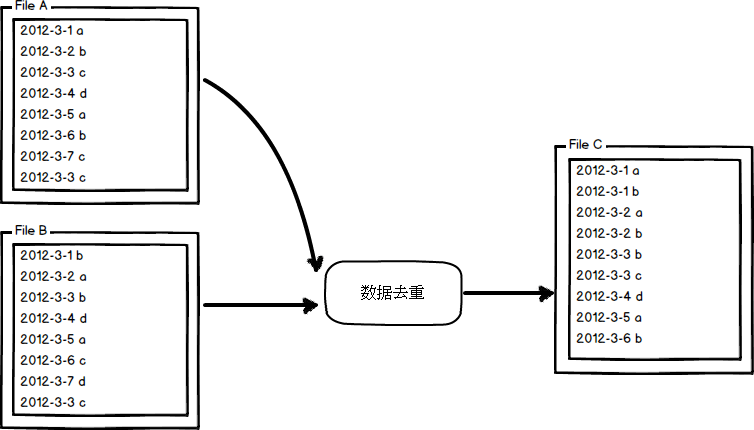
(2)資料去重
"資料去重"主要是為了掌握和利用並行化思想來對資料進行有意義的篩選。統計大資料集上的資料種類個數、從網站日誌中計算訪問地等這些看似龐雜的任務都會涉及資料去重。
(3)排序:按某個Key進行升序或降序排列
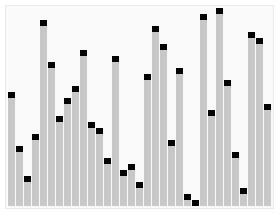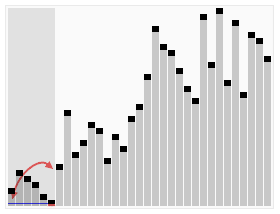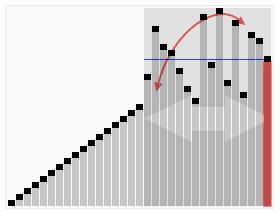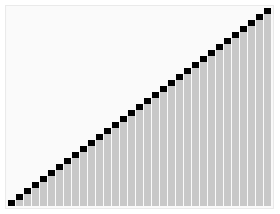
(4)TopK:對源資料中所有資料進行排序,取出前K個數據,就是TopK。
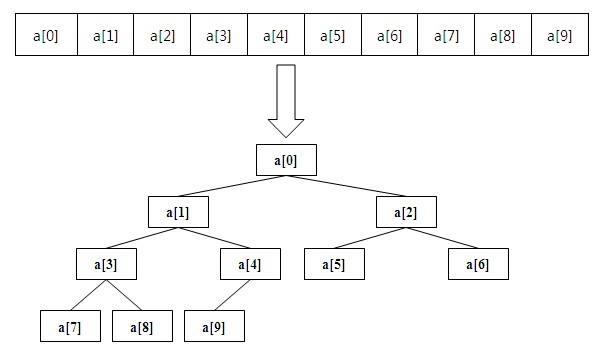
通常可以藉助堆(Heap)來實現TopK問題。
(5)選擇:關係代數基本操作再現
從指定關係中選擇出符合條件的元組(記錄)組成一個新的關係。在關係代數中,選擇運算是針對元組的運算。
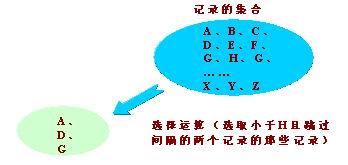
在MapReduce中,以求最大最小值為例,從N行資料中取出一行最小值,這就是一個典型的選擇操作。
(6)投影:關係代數基本操作再現
從指定關係的屬性(欄位)集合中選取部分屬性組成同類的一個新關係。由於屬性減少而出現的重複元組被自動刪除。投影運算針對的是屬性。

在MapReduce中,以前面的處理手機上網日誌為例,在日誌中的11個欄位中我們選出了五個欄位來顯示我們的手機上網流量就是一個典型的投影操作。
(7)分組:Group By XXXX
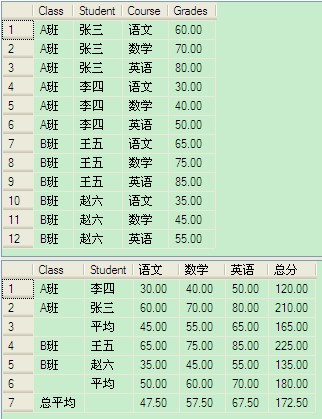
在MapReduce中,分組類似於分割槽操作,以處理手機上網日誌為例,我們分為了手機號和非手機號這樣的兩個組來分別處理。
(8)多表連線
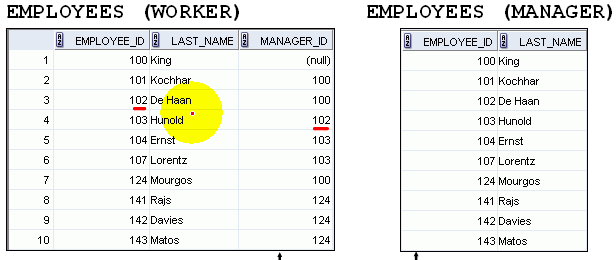
(9)單表關聯

二、TopK一般型別之前K個問題
TopK問題是一個很常見的實際問題:在一大堆的資料中如何高效地找出前K個最大/最小的資料。我們以前的做法一般是將整個資料檔案都載入到記憶體中,進行排序和統計。但是,當資料檔案達到一定量時,這時是無法直接全部載入到記憶體中的,除非你想冒著宕機的危險。
這時我們想到了分散式計算,利用計算機叢集來做這個事,打個比方:本來一臺機器需要10小時才能完成的事,現在10臺機器並行地來計算,只需要1小時就可以完成。本次我們使用一個隨機生成的100萬個數字的檔案,也就是說我們要做的就是在100萬個數中找到最大的前100個數字。
2.1 利用TreeMap儲存前K個數據
(1)紅黑樹的實現
如何儲存前K個數據時TopK問題的一大核心,這裡我們採用Java中TreeMap來進行儲存。TreeMap的實現是紅黑樹演算法的實現,紅黑樹又稱紅-黑二叉樹,它首先是一棵二叉樹,它具體二叉樹所有的特性,同時紅黑樹更是一棵自平衡的排序二叉樹。
平衡二叉樹必須具備如下特性:它是一棵空樹或它的左右兩個子樹的高度差的絕對值不超過1,並且左右兩個子樹都是一棵平衡二叉樹。也就是說該二叉樹的任何一個等等子節點,其左右子樹的高度都相近。
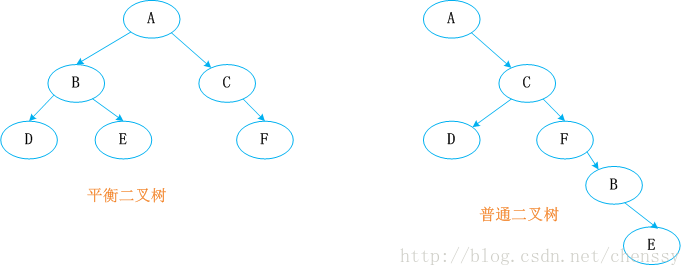
紅黑樹顧名思義就是:節點是紅色或者黑色的平衡二叉樹,它通過顏色的約束來維持著二叉樹的平衡。

About:關於TreeMap與紅黑樹的詳細介紹可以閱讀chenssy的一篇文章:TreeMap與紅黑樹 ,這裡不再贅述。
(2)TreeMap中的put方法
在TreeMap的put()的實現方法中主要分為兩個步驟,第一:構建排序二叉樹,第二:平衡二叉樹。
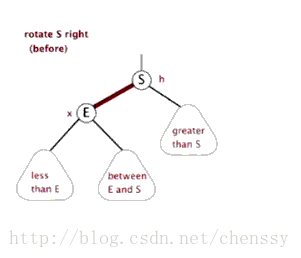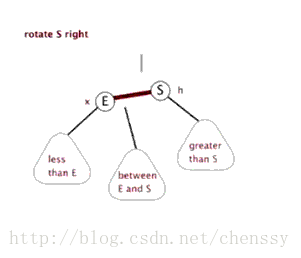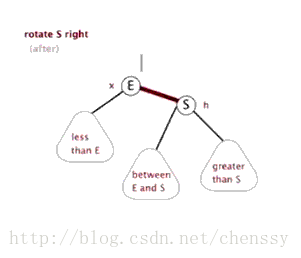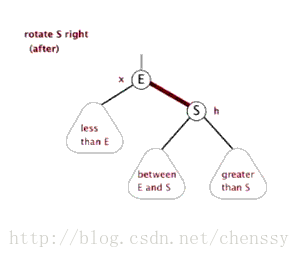
為了平衡二叉樹,往往需要進行左旋和右旋以及著色操作,這裡看看左旋和右旋操作,這些操作的目的都是為了維持平衡,保證二叉樹是有序的,可以幫助我們實現有序的效果,即資料的儲存是有序的。
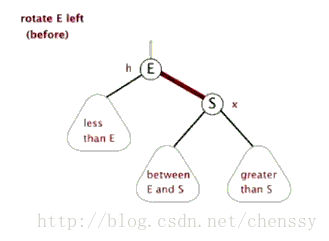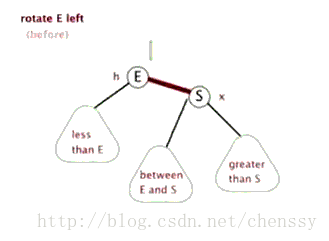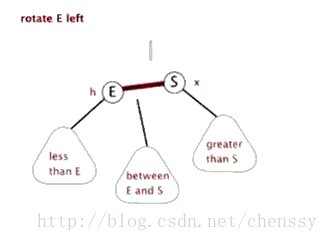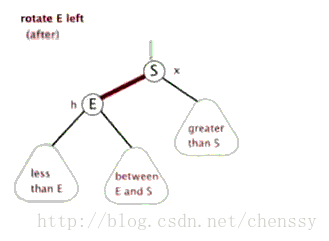
2.2 編寫map和reduce函式程式碼
(1)map函式
public static class MyMapper extends Mapper<LongWritable, Text, NullWritable, LongWritable> { public static final int K = 100; private TreeMap<Long, Long> tm = new TreeMap<Long, Long>(); protected void map( LongWritable key, Text value, Mapper<LongWritable, Text, NullWritable, LongWritable>.Context context) throws java.io.IOException, InterruptedException { try { long temp = Long.parseLong(value.toString().trim()); tm.put(temp, temp); if (tm.size() > K) { tm.remove(tm.firstKey()); // 如果是求topk個最小的那麼使用下面的語句 //tm.remove(tm.lastKey()); } } catch (Exception e) { context.getCounter("TopK", "errorLog").increment(1L); } }; protected void cleanup( org.apache.hadoop.mapreduce.Mapper<LongWritable, Text, NullWritable, LongWritable>.Context context) throws java.io.IOException, InterruptedException { for (Long num : tm.values()) { context.write(NullWritable.get(), new LongWritable(num)); } }; }
cleanup()方法是在map方法結束之後才會執行的方法,這裡我們將在該map任務中的前100個數據傳入reduce任務中;
(2)reduce函式
public static class MyReducer extends Reducer<NullWritable, LongWritable, NullWritable, LongWritable> { public static final int K = 100; private TreeMap<Long, Long> tm = new TreeMap<Long, Long>(); protected void reduce( NullWritable key, java.lang.Iterable<LongWritable> values, Reducer<NullWritable, LongWritable, NullWritable, LongWritable>.Context context) throws java.io.IOException, InterruptedException { for (LongWritable num : values) { tm.put(num.get(), num.get()); if (tm.size() > K) { tm.remove(tm.firstKey()); // 如果是求topk個最小的那麼使用下面的語句 //tm.remove(tm.lastKey()); } } // 按降序即從大到小排列Key集合 for (Long value : tm.descendingKeySet()) { context.write(NullWritable.get(), new LongWritable(value)); } }; }
在reduce方法中,依次將map方法中傳入的資料放入TreeMap中,並依靠紅黑色的平衡特性來維持資料的有序性。
(3)完整程式碼


package algorithm; import java.net.URI; import java.util.TreeMap; import mapreduce.MyWordCountJob.MyMapper; import mapreduce.MyWordCountJob.MyReducer; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.conf.Configured; import org.apache.hadoop.fs.FileSystem; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.LongWritable; import org.apache.hadoop.io.NullWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.io.compress.CompressionCodec; import org.apache.hadoop.io.compress.GzipCodec; import org.apache.hadoop.mapred.TestJobCounters.NewIdentityReducer; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.Mapper; import org.apache.hadoop.mapreduce.Reducer; import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; import org.apache.hadoop.mapreduce.lib.input.TextInputFormat; import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat; import org.apache.hadoop.mapreduce.lib.partition.HashPartitioner; import org.apache.hadoop.util.Tool; import org.apache.hadoop.util.ToolRunner; public class MyTopKNumJob extends Configured implements Tool { /** * @author Edison Chou * @version 1.0 */ public static class MyMapper extends Mapper<LongWritable, Text, NullWritable, LongWritable> { public static final int K = 100; private TreeMap<Long, Long> tm = new TreeMap<Long, Long>(); protected void map( LongWritable key, Text value, Mapper<LongWritable, Text, NullWritable, LongWritable>.Context context) throws java.io.IOException, InterruptedException { try { long temp = Long.parseLong(value.toString().trim()); tm.put(temp, temp); if (tm.size() > K) { //tm.remove(tm.firstKey()); // 如果是求topk個最小的那麼使用下面的語句 tm.remove(tm.lastKey()); } } catch (Exception e) { context.getCounter("TopK", "errorLog").increment(1L); } }; protected void cleanup( org.apache.hadoop.mapreduce.Mapper<LongWritable, Text, NullWritable, LongWritable>.Context context) throws java.io.IOException, InterruptedException { for (Long num : tm.values()) { context.write(NullWritable.get(), new LongWritable(num)); } }; } /** * @author Edison Chou * @version 1.0 */ public static class MyReducer extends Reducer<NullWritable, LongWritable, NullWritable, LongWritable> { public static final int K = 100; private TreeMap<Long, Long> tm = new TreeMap<Long, Long>(); protected void reduce( NullWritable key, java.lang.Iterable<LongWritable> values, Reducer<NullWritable, LongWritable, NullWritable, LongWritable>.Context context) throws java.io.IOException, InterruptedException { for (LongWritable num : values) { tm.put(num.get(), num.get()); if (tm.size() > K) { //tm.remove(tm.firstKey()); // 如果是求topk個最小的那麼使用下面的語句 tm.remove(tm.lastKey()); } } // 按降序即從大到小排列Key集合 for (Long value : tm.descendingKeySet()) { context.write(NullWritable.get(), new LongWritable(value)); } }; } // 輸入檔案路徑 public static String INPUT_PATH = "hdfs://hadoop-master:9000/testdir/input/seq100w.txt"; // 輸出檔案路徑 public static String OUTPUT_PATH = "hdfs://hadoop-master:9000/testdir/output/topkapp"; @Override public int run(String[] args) throws Exception { // 首先刪除輸出路徑的已有生成檔案 FileSystem fs = FileSystem.get(new URI(INPUT_PATH), getConf()); Path outPath = new Path(OUTPUT_PATH); if (fs.exists(outPath)) { fs.delete(outPath, true); } Job job = new Job(getConf(), "TopKNumberJob"); // 設定輸入目錄 FileInputFormat.setInputPaths(job, new Path(INPUT_PATH)); // 設定自定義Mapper job.setMapperClass(MyMapper.class); job.setMapOutputKeyClass(NullWritable.class); job.setMapOutputValueClass(LongWritable.class); // 設定自定義Reducer job.setReducerClass(MyReducer.class); job.setOutputKeyClass(NullWritable.class); job.setOutputValueClass(LongWritable.class); // 設定輸出目錄 FileOutputFormat.setOutputPath(job, new Path(OUTPUT_PATH)); return job.waitForCompletion(true) ? 0 : 1; } public static void main(String[] args) { Configuration conf = new Configuration(); // map端輸出啟用壓縮 conf.setBoolean("mapred.compress.map.output", true); // reduce端輸出啟用壓縮 conf.setBoolean("mapred.output.compress", true); // reduce端輸出壓縮使用的類 conf.setClass("mapred.output.compression.codec", GzipCodec.class, CompressionCodec.class); try { int res = ToolRunner.run(conf, new MyTopKNumJob(), args); System.exit(res); } catch (Exception e) { e.printStackTrace(); } } }View Code
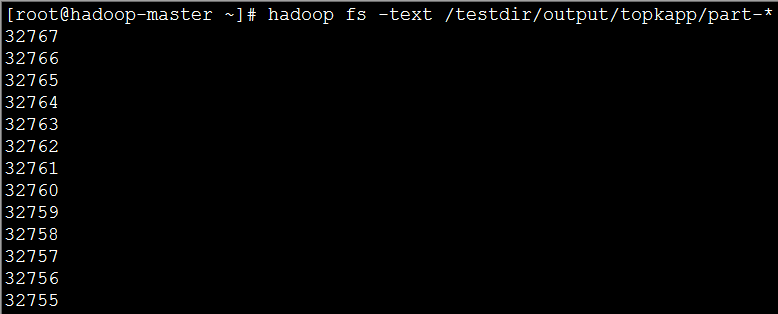
(4)實現效果:圖片大小有限,這裡只顯示了前12個;
三、TopK特殊型別之最值問題
最值問題是一個典型的選擇操作,從100萬個數字中找到最大或最小的一個數字,在本次實驗檔案中,最大的數字時32767。現在,我們就來改寫程式碼,找到32767。
3.1 改寫map函式
public static class MyMapper extends Mapper<LongWritable, Text, LongWritable, NullWritable> { long max = Long.MIN_VALUE; protected void map(LongWritable key, Text value, Mapper<LongWritable, Text, LongWritable, NullWritable>.Context context) throws java.io.IOException, InterruptedException { long temp = Long.parseLong(value.toString().trim()); if (temp > max) { max = temp; } }; protected void cleanup( org.apache.hadoop.mapreduce.Mapper<LongWritable, Text, LongWritable, NullWritable>.Context context) throws java.io.IOException, InterruptedException { context.write(new LongWritable(max), NullWritable.get()); }; }
是不是很熟悉?其實就是依次與假設的最大值進行比較。
3.2 改寫reduce函式
public static class MyReducer extends Reducer<LongWritable, NullWritable, LongWritable, NullWritable> { long max = Long.MIN_VALUE; protected void reduce( LongWritable key, java.lang.Iterable<NullWritable> values, Reducer<LongWritable, NullWritable, LongWritable, NullWritable>.Context context) throws java.io.IOException, InterruptedException { long temp = key.get(); if (temp > max) { max = temp; } }; protected void cleanup( org.apache.hadoop.mapreduce.Reducer<LongWritable, NullWritable, LongWritable, NullWritable>.Context context) throws java.io.IOException, InterruptedException { context.write(new LongWritable(max), NullWritable.get()); }; }
在reduce方法中,繼續對各個map任務傳入的資料進行比較,還是依次地與假設的最大值進行比較,最後所有reduce方法執行完成後通過cleanup方法對最大值進行輸出。
最終的完整程式碼如下:
package algorithm; import java.net.URI; import mapreduce.MyWordCountJob.MyMapper; import mapreduce.MyWordCountJob.MyReducer; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.conf.Configured; import org.apache.hadoop.fs.FileSystem; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.LongWritable; import org.apache.hadoop.io.NullWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.io.compress.CompressionCodec; import org.apache.hadoop.io.compress.GzipCodec; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.Mapper; import org.apache.hadoop.mapreduce.Reducer; import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; import org.apache.hadoop.mapreduce.lib.input.TextInputFormat; import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat; import org.apache.hadoop.mapreduce.lib.partition.HashPartitioner; import org.apache.hadoop.util.Tool; import org.apache.hadoop.util.ToolRunner; public class MyMaxNumJob extends Configured implements Tool { /** * @author Edison Chou * @version 1.0 */ public static class MyMapper extends Mapper<LongWritable, Text, LongWritable, NullWritable> { long max = Long.MIN_VALUE; protected void map(LongWritable key, Text value, Mapper<LongWritable, Text, LongWritable, NullWritable>.Context context) throws java.io.IOException, InterruptedException { long temp = Long.parseLong(value.toString().trim()); if (temp > max) { max = temp; } }; protected void cleanup( org.apache.hadoop.mapreduce.Mapper<LongWritable, Text, LongWritable, NullWritable>.Context context) throws java.io.IOException, InterruptedException { context.write(new LongWritable(max), NullWritable.get()); }; } /** * @author Edison Chou * @version 1.0 */ public static class MyReducer extends Reducer<LongWritable, NullWritable, LongWritable, NullWritable> { long max = Long.MIN_VALUE; protected void reduce( LongWritable key, java.lang.Iterable<NullWritable> values, Reducer<LongWritable, NullWritable, LongWritable, NullWritable>.Context context) throws java.io.IOException, InterruptedException { long temp = key.get(); if (temp > max) { max = temp; } }; protected void cleanup( org.apache.hadoop.mapreduce.Reducer<LongWritable, NullWritable, LongWritable, NullWritable>.Context context) throws java.io.IOException, InterruptedException { context.write(new LongWritable(max), NullWritable.get()); }; } // 輸入檔案路徑 public static String INPUT_PATH = "hdfs://hadoop-master:9000/testdir/input/seq100w.txt"; // 輸出檔案路徑 public static String OUTPUT_PATH = "hdfs://hadoop-master:9000/testdir/output/topkapp"; @Override public int run(String[] args) throws Exception { // 首先刪除輸出路徑的已有生成檔案 FileSystem fs = FileSystem.get(new URI(INPUT_PATH), getConf()); Path outPath = new Path(OUTPUT_PATH); if (fs.exists(outPath)) { fs.delete(outPath, true); } Job job = new Job(getConf(), "MaxNumberJob"); // 設定輸入目錄 FileInputFormat.setInputPaths(job, new Path(INPUT_PATH)); // 設定自定義Mapper job.setMapperClass(MyMapper.class); job.setMapOutputKeyClass(LongWritable.class); job.setMapOutputValueClass(NullWritable.class); // 設定自定義Reducer job.setReducerClass(MyReducer.class); job.setOutputKeyClass(LongWritable.class); job.setOutputValueClass(NullWritable.class); // 設定輸出目錄 FileOutputFormat.setOutputPath(job, new Path(OUTPUT_PATH)); System.exit(job.waitForCompletion(true) ? 0 : 1); return 0; } public static void main(String[] args) { Configuration conf = new Configuration(); // map端輸出啟用壓縮 conf.setBoolean("mapred.compress.map.output", true); // reduce端輸出啟用壓縮 conf.setBoolean("mapred.output.compress", true); // reduce端輸出壓縮使用的類 conf.setClass("mapred.output.compression.codec", GzipCodec.class, CompressionCodec.class); try { int res = ToolRunner.run(conf, new MyMaxNumJob(), args); System.exit(res); } catch (Exception e) { e.printStackTrace(); } } }View Code
3.3 檢視實現效果

可以看出,我們的程式已經求出了最大值:32767。雖然例子很簡單,業務也很簡單,但是我們引入了分散式計算的思想,將MapReduce應用在了最值問題之中,就是一個進步了!
參考資料
作者:周旭龍
本文版權歸作者和部落格園共有,歡迎轉載,但未經作者同意必須保留此段宣告,且在文章頁面明顯位置給出原文連結。
相關推薦
Hadoop學習筆記—12.MapReduce中的常見演算法
一、MapReduce中有哪些常見演算法 (1)經典之王:單詞計數 這個是MapReduce的經典案例,經典的不能再經典了! (2)資料去重 "資料去重"主要是為了掌握和利用並行化思想來對資料進行有意義的篩選。統計大資料集上的資料種類個數、從網站日誌中計算訪問地等這些看似龐
Hadoop學習筆記—11.MapReduce中的排序和分組
一、寫在之前的 1.1 回顧Map階段四大步驟 首先,我們回顧一下在MapReduce中,排序和分組在哪裡被執行: 從上圖中可以清楚地看出,在Step1.4也就是第四步中,需要對不同分割槽中的資料進行排序和分組,預設情況下,是按照key進行排序和分組。 1.2 實驗場景資料檔案 在一
Hadoop學習筆記:MapReduce框架詳解
object 好的 單點故障 提高 apr copy 普通 exce 代表性 開始聊mapreduce,mapreduce是hadoop的計算框架,我學hadoop是從hive開始入手,再到hdfs,當我學習hdfs時候,就感覺到hdfs和mapreduce關系的緊密。這個
PyTorch學習筆記(12)——PyTorch中的Autograd機制介紹
在《PyTorch學習筆記(11)——論nn.Conv2d中的反向傳播實現過程》[1]中,談到了Autograd在nn.Conv2d的權值更新中起到的用處。今天將以官方的說明為基礎,補充說明一下關於計算圖、Autograd機制、Symbol2Symbol等內容。 0.
Android學習筆記--GMS認證中常見的fail項及解決方法
############################################################# cts測試的一些命令: sudo chmod a+x copy_media.sh ./copy_media.sh all ad
學習筆記12——Linux中的檔案型別
1.概述 (1) Windows系統通過副檔名來區分檔案型別,而linux中副檔名和檔案型別沒有關係 (2) 為了便於區分並且相容使用者使用windows的習慣,我們也會採用副檔名來表示linux中的檔案型別 (3) Linux中一切皆檔案。 2.Linux中的
Hadoop 學習筆記 (2) -- 關於MapReduce
規模 pre 分析 bsp 學習筆記 reduce 數據中心 階段 圖例 1. MapReduce 定義: 是一種可用於數據處理的編程的模型 優勢: MapReduce 本質上是並行運行的,因此可以將大規模的數據分析任務,分發給任何一個擁有足夠多機器
Hadoop學習筆記—13.分布式集群中節點的動態添加與下架
情況 好的 當前 每次 原因 修改 輸入 task tle 開篇:在本筆記系列的第一篇中,我們介紹了如何搭建偽分布與分布模式的Hadoop集群。現在,我們來了解一下在一個Hadoop分布式集群中,如何動態(不關機且正在運行的情況下)地添加一個Hadoop節點與下架一個Had
hadoop學習筆記(十一):MapReduce數據類型
筆記 ash all 記錄 write 一個 操作 png bool 一、序列化 1 hadoop自定義了數據類型,在hadoop中,所有的key/value類型必須實現Writable接口。有兩個方法,一個是write,一個是readFileds。分別用於讀(反序列化操
Hadoop學習筆記—4.初識MapReduce 一、神馬是高大上的MapReduce MapReduce是Google的一項重要技術,它首先是一個程式設計模型,用以進行大資料量的計算。對於大資料
Hadoop學習筆記—4.初識MapReduce 一、神馬是高大上的MapReduce MapReduce是Google的一項重要技術,它首先是一個程式設計模型,用以進行大資料量的計算。對於大資料量的計算,通常採用的處理手法就是平行計算。但對許多開發
Hadoop學習筆記三 -- 決策樹演算法實現使用者風險等級分類
前言 剛剛過去的2016年被稱為人工智慧的元年,在AlphaGo大戰李世石取得里程碑式的勝利後,神經網路和深度學習的概念瞬間進入了人們的視野,各大商業巨頭也紛紛將自己的目標轉移到這個還沒有任何明確方向但所有人都知道它一旦出手將改變世界的人工智慧方向中。在這個過
機器學習筆記(12)---使用Sklearn中的SVM
svm理論太難理解了,先上個sklearn中的SVM程式碼提升點信心吧,理論後續補上。 import numpy as np from sklearn import datasets from s
Hadoop學習筆記-MapReduce工作原理
本文從一個初學者的角度出發,用通俗易懂的語言介紹Hadoop中MapReduce的工作原理。在介紹MapReduce工作原理前,本文先介紹HDFS的工作原理及架構,再介紹MapReduce的工作原理以及Shuffle的過程。 HDFS HDFS是Hado
Hadoop學習筆記—13.分散式叢集中節點的動態新增與下架
開篇:在本筆記系列的第一篇中,我們介紹瞭如何搭建偽分佈與分佈模式的Hadoop叢集。現在,我們來了解一下在一個Hadoop分散式叢集中,如何動態(不關機且正在執行的情況下)地新增一個Hadoop節點與下架一個Hadoop節點。 一、實驗環境結構 本次試驗,我們構建的叢集是一個主節點,三個從節點的結構,
淺解MapReduce與簡單MapReduce程式出包---Hadoop學習筆記(2)
淺略理解MapReduce的概念機制是開始真正使用Hadoop開發Mapreduce程式的第一步,是一個充分條件。理解和實踐並進才能讓更多的問題暴露對理論的理解的不夠。繼續學習《Hadoop基礎教程》。 1.Map與Reduce Hado
Hadoop學習筆記之初識MapReduce以及WordCount例項分析
MapReduce簡介 MapReduce是什麼? MapReduce是一種程式設計模型,用於大規模資料集的分散式運算。 Mapreduce基本原理 1、MapReduce通俗解釋 圖書館要清點圖書數量,有10個書架,管理員為了加快統計速度,找來了
Hadoop 學習筆記十 常見問題彙總
1 could only be replicated to 0 nodes instead of minReplication (=1) 執行hive時出現這個錯誤,在hadoop上執行jps,
Hadoop學習筆記—4.初識MapReduce 一、神馬是高大上的MapReduce MapReduce是Google的一項重要技術,它首先是一個程式設計模型,用以進行大資料量的計算。對於大資料
一、神馬是高大上的MapReduce MapReduce是Google的一項重要技術,它首先是一個程式設計模型,用以進行大資料量的計算。對於大資料量的計算,通常採用的處理手法就是平行計算。但對許多開發者來說,自己完完全全實現一個平行計算程式難度太大,而MapReduce就是一種簡化平行計算的程式設計模
hadoop學習筆記-HDFS的REST接口
字段 edi -o created hadoop ftw rar hdfs lang 在學習HDFS的過程中,重點關註了HDFS的REST訪問接口。以前對REST的認識非常籠統,這次通過對HDFS的REST接口進行實際操作,形成很直觀的認識。 1? 寫文件操作 寫文件
Hadoop自學筆記(一)常見Hadoop相關項目一覽
-a https class Lucene 百萬 data fcm you 轉換 本自學筆記來自於Yutube上的視頻Hadoop系列。網址: https://www.youtube.com/watch?v=-TaAVaAwZTs(當中一個) 以後不再贅述 自學筆