
Hadoop學習筆記—11.MapReduce中的排序和分組
一、寫在之前的
1.1 回顧Map階段四大步驟
首先,我們回顧一下在MapReduce中,排序和分組在哪裡被執行:
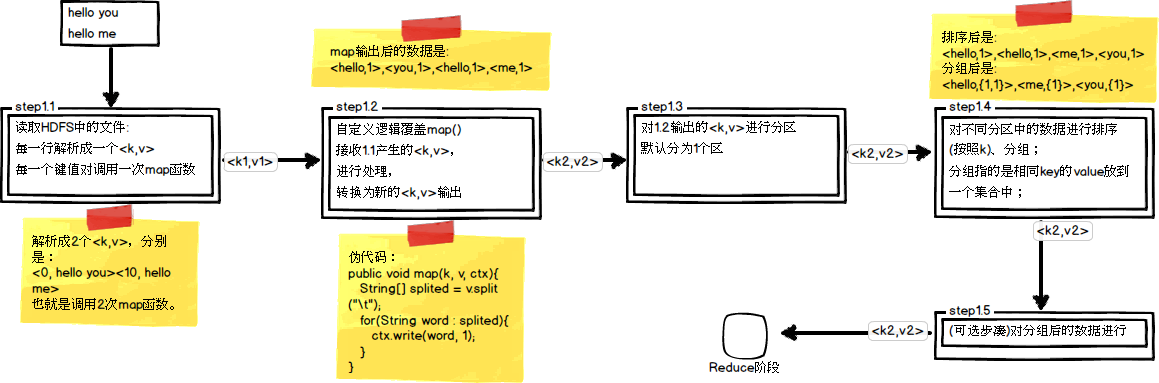
從上圖中可以清楚地看出,在Step1.4也就是第四步中,需要對不同分割槽中的資料進行排序和分組,預設情況下,是按照key進行排序和分組。
1.2 實驗場景資料檔案
在一些特定的資料檔案中,不一定都是類似於WordCount單次統計這種規範的資料,比如下面這類資料,它雖然只有兩列,但是卻有一定的實踐意義。
3 3 3 2 3 1 2 2 2 1 1 1
(1)如果按照第一列升序排列,當第一列相同時,第二列升序排列,結果如下所示
1 1 2 1 2 2 3 1 3 2 3 3
(2)如果當第一列相同時,求出第二列的最小值,結果如下所示
3 1 2 1 1 1
接著,我們會針對這個資料檔案,進行排序和分組的實踐嘗試,以求達到結果所示的效果。
二、初步探索排序
2.1 預設的排序
在Hadoop預設的排序演算法中,只會針對key值進行排序,我們最初的程式碼如下(這裡只展示了map和reduce函式):
public class MySortJob extends Configured implements Tool {public static class MyMapper extends Mapper<LongWritable, Text, LongWritable, LongWritable> { protected void map( LongWritable key, Text value, Mapper<LongWritable, Text, LongWritable, LongWritable>.Context context)throws java.io.IOException, InterruptedException { String[] spilted = value.toString().split("\t"); long firstNum = Long.parseLong(spilted[0]); long secondNum = Long.parseLong(spilted[1]); context.write(new LongWritable(firstNum), new LongWritable( secondNum)); }; } public static class MyReducer extends Reducer<Text, LongWritable, Text, LongWritable> { protected void reduce( LongWritable key, java.lang.Iterable<LongWritable> values, Reducer<LongWritable, LongWritable, LongWritable, LongWritable>.Context context) throws java.io.IOException, InterruptedException { for (LongWritable value : values) { context.write(key, value); } }; } }
這裡我們將第一列作為了key,第二列作為了value。
可以檢視一下執行後的結果,如下所示:
1 1 2 2 2 1 3 3 3 2 3 1
從執行結果來看,並沒有達到我們最初的目的,於是,我們需要拋棄預設的排序規則,因此我們要自定義排序。
2.2 自定義排序
(1)封裝一個自定義型別作為key的新型別:將第一列與第二列都作為key
private static class MyNewKey implements WritableComparable<MyNewKey> { long firstNum; long secondNum; public MyNewKey() { } public MyNewKey(long first, long second) { firstNum = first; secondNum = second; } @Override public void write(DataOutput out) throws IOException { out.writeLong(firstNum); out.writeLong(secondNum); } @Override public void readFields(DataInput in) throws IOException { firstNum = in.readLong(); secondNum = in.readLong(); } /* * 當key進行排序時會呼叫以下這個compreTo方法 */ @Override public int compareTo(MyNewKey anotherKey) { long min = firstNum - anotherKey.firstNum; if (min != 0) { // 說明第一列不相等,則返回兩數之間小的數 return (int) min; } else { return (int) (secondNum - anotherKey.secondNum); } } }
PS:這裡為什麼需要封裝一個新型別呢?因為原來只有key參與排序,現在將第一個數和第二個數都參與排序,作為一個新的key。
(2)改寫最初的MapReduce方法函式程式碼:(只展示了map和reduce函式,還需要修改map和reduce輸出的型別設定)
public static class MyMapper extends Mapper<LongWritable, Text, MyNewKey, LongWritable> { protected void map( LongWritable key, Text value, Mapper<LongWritable, Text, MyNewKey, LongWritable>.Context context) throws java.io.IOException, InterruptedException { String[] spilted = value.toString().split("\t"); long firstNum = Long.parseLong(spilted[0]); long secondNum = Long.parseLong(spilted[1]); // 使用新的型別作為key參與排序 MyNewKey newKey = new MyNewKey(firstNum, secondNum); context.write(newKey, new LongWritable(secondNum)); }; } public static class MyReducer extends Reducer<MyNewKey, LongWritable, LongWritable, LongWritable> { protected void reduce( MyNewKey key, java.lang.Iterable<LongWritable> values, Reducer<MyNewKey, LongWritable, LongWritable, LongWritable>.Context context) throws java.io.IOException, InterruptedException { context.write(new LongWritable(key.firstNum), new LongWritable( key.secondNum)); }; }
從上面的程式碼中我們可以發現,新型別MyNewKey實現了一個叫做WritableComparable的介面,該介面中有一個compareTo()方法,當對key進行比較時會呼叫該方法,而我們將其改為了我們自己定義的比較規則,從而實現我們想要的效果。
其實,這個WritableComparable還實現了兩個介面,我們看看其定義:
public interface WritableComparable<T> extends Writable, Comparable<T> { }
Writable介面是為了實現序列化,而Comparable則是為了實現比較。
(3)現在看看執行結果:
1 1 2 1 2 2 3 1 3 2 3 3
執行結果與預期的已經一致,自定義排序生效!
三、初步探索分組
3.1 預設的分組
在Hadoop中的預設分組規則中,也是基於Key進行的,會將相同key的value放到一個集合中去。這裡以上面的例子繼續看看分組,因為我們自定義了一個新的key,它是以兩列資料作為key的,因此這6行資料中每個key都不相同,也就是說會產生6組,它們是:1 1,2 1,2 2,3 1,3 2,3 3。而實際上只可以分為3組,分別是1,2,3。
現在首先改寫一下reduce函式程式碼,目的是求出第一列相同時第二列的最小值,看看它會有怎麼樣的分組:
public static class MyReducer extends Reducer<MyNewKey, LongWritable, LongWritable, LongWritable> { protected void reduce( MyNewKey key, java.lang.Iterable<LongWritable> values, Reducer<MyNewKey, LongWritable, LongWritable, LongWritable>.Context context) throws java.io.IOException, InterruptedException { long min = Long.MAX_VALUE; for (LongWritable number : values) { long temp = number.get(); if (temp < min) { min = temp; } } context.write(new LongWritable(key.firstNum), new LongWritable(min)); }; }
其執行結果為:
1 1 2 1 2 2 3 1 3 2 3 3
但是我們預期的結果為:
#當第一列相同時,求出第二列的最小值 3 3 3 2 3 1 2 2 2 1 1 1 ------------------- #預期結果應該是 3 1 2 1 1 1
3.2 自定義分組
為了針對新的key型別作分組,我們也需要自定義一下分組規則:
(1)編寫一個新的分組比較型別用於我們的分組:
private static class MyGroupingComparator implements RawComparator<MyNewKey> { /* * 基本分組規則:按第一列firstNum進行分組 */ @Override public int compare(MyNewKey key1, MyNewKey key2) { return (int) (key1.firstNum - key2.firstNum); } /* * @param b1 表示第一個參與比較的位元組陣列 * * @param s1 表示第一個參與比較的位元組陣列的起始位置 * * @param l1 表示第一個參與比較的位元組陣列的偏移量 * * @param b2 表示第二個參與比較的位元組陣列 * * @param s2 表示第二個參與比較的位元組陣列的起始位置 * * @param l2 表示第二個參與比較的位元組陣列的偏移量 */ @Override public int compare(byte[] b1, int s1, int l1, byte[] b2, int s2, int l2) { return WritableComparator.compareBytes(b1, s1, 8, b2, s2, 8); } }
從程式碼中我們可以知道,我們自定義了一個分組比較器MyGroupingComparator,該類實現了RawComparator介面,而RawComparator介面又實現了Comparator介面,下面看看這兩個介面的定義:
首先是RawComparator介面的定義:
public interface RawComparator<T> extends Comparator<T> { public int compare(byte[] b1, int s1, int l1, byte[] b2, int s2, int l2); }
其次是Comparator介面的定義:
public interface Comparator<T> { int compare(T o1, T o2); boolean equals(Object obj); }
在MyGroupingComparator中分別對這兩個介面中的定義進行了實現,RawComparator中的compare()方法是基於位元組的比較,Comparator中的compare()方法是基於物件的比較。
在基於位元組的比較方法中,有六個引數,一下子眼花了:
Params:
* @param arg0 表示第一個參與比較的位元組陣列
* @param arg1 表示第一個參與比較的位元組陣列的起始位置
* @param arg2 表示第一個參與比較的位元組陣列的偏移量
*
* @param arg3 表示第二個參與比較的位元組陣列
* @param arg4 表示第二個參與比較的位元組陣列的起始位置
* @param arg5 表示第二個參與比較的位元組陣列的偏移量
由於在MyNewKey中有兩個long型別,每個long型別又佔8個位元組。這裡因為比較的是第一列數字,所以讀取的偏移量為8位元組。
(2)新增對分組規則的設定:
// 設定自定義分組規則 job.setGroupingComparatorClass(MyGroupingComparator.class);
(3)現在看看執行結果:

參考資料
作者:周旭龍
本文版權歸作者和部落格園共有,歡迎轉載,但未經作者同意必須保留此段宣告,且在文章頁面明顯位置給出原文連結。
相關推薦
Hadoop學習筆記—11.MapReduce中的排序和分組
一、寫在之前的 1.1 回顧Map階段四大步驟 首先,我們回顧一下在MapReduce中,排序和分組在哪裡被執行: 從上圖中可以清楚地看出,在Step1.4也就是第四步中,需要對不同分割槽中的資料進行排序和分組,預設情況下,是按照key進行排序和分組。 1.2 實驗場景資料檔案 在一
Hadoop學習筆記—12.MapReduce中的常見演算法
一、MapReduce中有哪些常見演算法 (1)經典之王:單詞計數 這個是MapReduce的經典案例,經典的不能再經典了! (2)資料去重 "資料去重"主要是為了掌握和利用並行化思想來對資料進行有意義的篩選。統計大資料集上的資料種類個數、從網站日誌中計算訪問地等這些看似龐
Hadoop學習筆記:MapReduce框架詳解
object 好的 單點故障 提高 apr copy 普通 exce 代表性 開始聊mapreduce,mapreduce是hadoop的計算框架,我學hadoop是從hive開始入手,再到hdfs,當我學習hdfs時候,就感覺到hdfs和mapreduce關系的緊密。這個
【學習筆記】JAVA中replace和replaceAll的區別
replaceAll()&&replace區別: 1、replaceA(regex,replace)引數是regex,是基於正則表示式的替換; 2、replace(oldChar, newChar)可以支援字元的替換,也可以支援字串的替換; PS
前端學習筆記之js中apply()和call()方法詳解
經過網上的大量搜尋,漸漸明白了apply()和call方法的使用,為此寫一篇文章記錄一下。 定義 apply()方法: Function.apply(obj,args)
MySQL資料庫學習06-查詢資料:排序和分組
一、對查詢結果排序 MySQL中可以使用ORDER BY子句對查詢到的結果進行排序。 1.單列排序 a.查詢f_name欄位,按照字母排序 2.多列排序 ORDER BY子句也可以實現對多列資料進行排序,需要將待排序的列之間用逗號隔開。對多列排序是
sqlite學習筆記11:C語言中使用sqlite之刪除記錄
false done mta ase rom real not null -a ubun 最後一節,這裏記錄下怎樣刪除數據。 前面全部的代碼都繼承在這裏了,在Ubuntu14.04和Mac10.9上親測通過。 #include <stdio.h> #in
Hadoop 學習筆記 (2) -- 關於MapReduce
規模 pre 分析 bsp 學習筆記 reduce 數據中心 階段 圖例 1. MapReduce 定義: 是一種可用於數據處理的編程的模型 優勢: MapReduce 本質上是並行運行的,因此可以將大規模的數據分析任務,分發給任何一個擁有足夠多機器
Hadoop學習筆記—13.分布式集群中節點的動態添加與下架
情況 好的 當前 每次 原因 修改 輸入 task tle 開篇:在本筆記系列的第一篇中,我們介紹了如何搭建偽分布與分布模式的Hadoop集群。現在,我們來了解一下在一個Hadoop分布式集群中,如何動態(不關機且正在運行的情況下)地添加一個Hadoop節點與下架一個Had
學習筆記11 EF查詢相當於sql 中的 where in
lec sql blog contains 學習筆記 [] HERE var sel 兩種寫法 1、 int[] Ids={1,2,3} DBContainer db=new DBContainer(); var list=db.表明.where(a=>Ids.
hadoop學習筆記(十一):MapReduce數據類型
筆記 ash all 記錄 write 一個 操作 png bool 一、序列化 1 hadoop自定義了數據類型,在hadoop中,所有的key/value類型必須實現Writable接口。有兩個方法,一個是write,一個是readFileds。分別用於讀(反序列化操
Kali學習筆記11:nmap在二層發現中的應用
clas conf DC echo broadcast col 9.png ace arping nmap在二層發現中的使用: nmap只需要一行即可實現arping的一個腳本:並且速度更快 #!/bin/bash if [ "$#" -ne 1 ];then ec
hadoop學習筆記(三):hdfs體系結構和讀寫流程(轉)
sim 百萬 服務器 發表 繼續 什麽 lose 基於 一次 原文:https://www.cnblogs.com/codeOfLife/p/5375120.html 目錄 HDFS 是做什麽的 HDFS 從何而來 為什麽選擇 HDFS 存儲數據 HDFS
Hadoop學習筆記—4.初識MapReduce 一、神馬是高大上的MapReduce MapReduce是Google的一項重要技術,它首先是一個程式設計模型,用以進行大資料量的計算。對於大資料
Hadoop學習筆記—4.初識MapReduce 一、神馬是高大上的MapReduce MapReduce是Google的一項重要技術,它首先是一個程式設計模型,用以進行大資料量的計算。對於大資料量的計算,通常採用的處理手法就是平行計算。但對許多開發
SpringBoot學習筆記(10)-----SpringBoot中使用Redis/Mongodb和快取Ehcache快取和redis快取
1. 使用Redis 在使用redis之前,首先要保證安裝或有redis的伺服器,接下就是引入redis依賴。 pom.xml檔案如下 <dependency> <groupId>org.springframework.boot</
【java學習筆記】MyBatis中當實體類中的屬性名和表中的欄位名不一樣時的解決方法
在使用MyBatis開發DAO層時,當實體類中的屬性名和表中的欄位名不一樣時,查詢出來的值為null,此時有3種解決方法 解決方法1 在Mapper.xml對映檔案中,寫SQL語句時起別名 解決
PyTorch學習筆記(11)——論nn.Conv2d中的反向傳播實現過程
0. 前言 眾所周知,反向傳播(back propagation)演算法 (Rumelhart et al., 1986c),經常簡稱為backprop,它允許來自代價函式的資訊通過網路向後流動,以便計算梯度。它是神經網路之所以可以進行學習的最根本因素。在如PyTorch、Tenso
hadoop二次排序 (Map/Reduce中分割槽和分組的問題)
1.二次排序概念:首先按照第一欄位排序,然後再對第一欄位相同的行按照第二欄位排序,注意不能破壞第一次排序的結果 。如: 輸入檔案:20 21 50 51 50 52 50 53 50 54 60 51 60 53 60 52 60 56 60 57 70 58 60 61 70 54 70 55 70 56
Hadoop學習筆記-MapReduce工作原理
本文從一個初學者的角度出發,用通俗易懂的語言介紹Hadoop中MapReduce的工作原理。在介紹MapReduce工作原理前,本文先介紹HDFS的工作原理及架構,再介紹MapReduce的工作原理以及Shuffle的過程。 HDFS HDFS是Hado
Hadoop 學習研究(八): 多Job任務和hadoop中的全域性變數
/* * 重寫Mapper的setup方法,獲取分散式快取中的檔案 */ @Override protected void setup(Mapper<LongWritable, Text, Text, Text>.Context context)