
以太坊資料結構、儲存、區塊頭的關係與分析
在Ethereum的世界裡,資料的最終儲存形式是[k,v]鍵值對,目前使用的[k,v]型底層資料庫是LevelDB;所有與交易,操作相關的資料,其呈現的集合形式是Block(Header);如果以Block為單位連結起來,則構成更大粒度的BlockChain(HeaderChain);若以Block作切割,那麼Transaction和Contract就是更小的粒度;所有交易或操作的結果,將以各個個體賬戶的狀態(state)存在,賬戶的呈現形式是stateObject,所有賬戶的集合受StateDB管理。下圖描繪了上述各資料單元的層次關係:
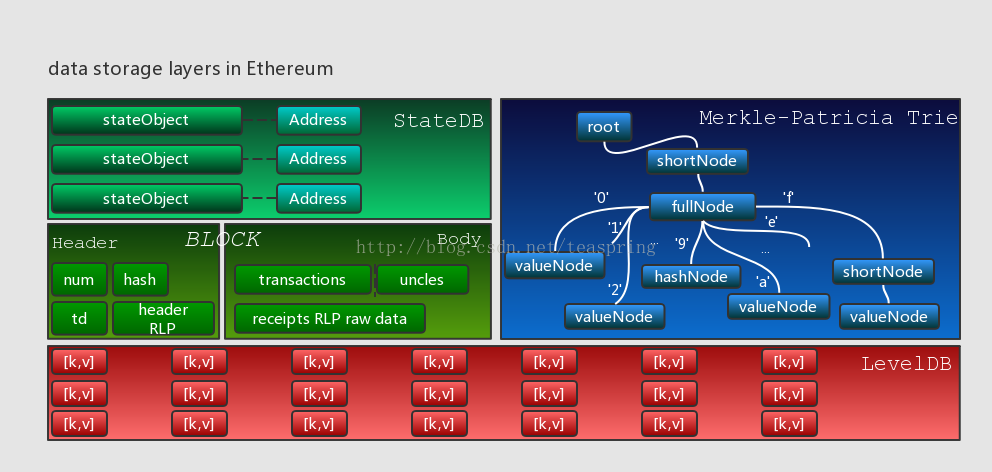
另一方面,上述資料單元如Block,stateObject,StateDB等,均大量使用Merkle-PatriciaTrie(MPT)資料結構以組織和管理[k,v]型資料。利用MPT高效的分段雜湊驗證機制和靈活的節點(Node)插入/載入設計,呼叫方均可快速且高效的實現對資料的插入、刪除、更新、壓縮和加密。以下各章節會對以上內容分別展開詳細介紹。
1. Block和Header
Block(區塊)是Ethereum的核心資料結構之一。所有賬戶的相關活動,以交易(Transaction)的格式儲存,每個Block有一個交易物件的列表;每個交易的執行結果,由一個Receipt物件與其包含的一組Log物件記錄;所有交易執行完後生成的Receipt列表,儲存在Block中(經過壓縮加密)。不同Block之間,通過前向指標ParentHash一個一個串聯起來成為一個單向連結串列,BlockChain 結構體管理著這個連結串列。
Block結構體基本可分為Header和Body兩個部分,其UML關係族如下圖所示:
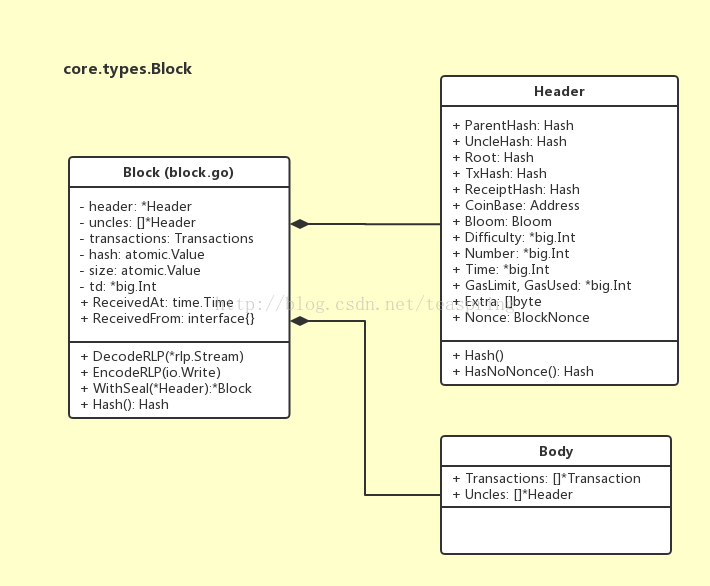
Header部分
Header是Block的核心,注意到它的成員變數全都是公共的,這使得它可以很方便的向呼叫者提供關於Block屬性的操作。Header的成員變數全都很重要,值得細細理解:
- ParentHash:指向父區塊(parentBlock)的指標。除了創世塊(Genesis Block)外,每個區塊有且只有一個父區塊。
- Coinbase:挖掘出這個區塊的作者地址。在每次執行交易時系統會給與一定補償的Ether,這筆金額就是發給這個地址的。
- UncleHash:Block結構體的成員uncles的RLP雜湊值。uncles是一個Header陣列,它的存在,頗具匠心。
- Root:StateDB中的“state Trie”的根節點的RLP雜湊值。Block中,每個賬戶以stateObject物件表示,賬戶以Address為唯一標示,其資訊在相關交易(Transaction)的執行中被修改。所有賬戶物件可以逐個插入一個Merkle-PatricaTrie(MPT)結構裡,形成“state Trie”。
- TxHash: Block中 “tx Trie”的根節點的RLP雜湊值。Block的成員變數transactions中所有的tx物件,被逐個插入一個MPT結構,形成“tx Trie”。
- ReceiptHash:Block中的 "Receipt Trie”的根節點的RLP雜湊值。Block的所有Transaction執行完後會生成一個Receipt陣列,這個陣列中的所有Receipt被逐個插入一個MPT結構中,形成"Receipt Trie"。
- Bloom:Bloom過濾器(Filter),用來快速判斷一個引數Log物件是否存在於一組已知的Log集合中。
- Difficulty:區塊的難度。Block的Difficulty由共識演算法基於parentBlock的Time和Difficulty計算得出,它會應用在區塊的‘挖掘’階段。
- Number:區塊的序號。Block的Number等於其父區塊Number +1。
- Time:區塊“應該”被建立的時間。由共識演算法確定,一般來說,要麼等於parentBlock.Time + 10s,要麼等於當前系統時間。
- GasLimit:區塊內所有Gas消耗的理論上限。該數值在區塊建立時設定,與父區塊有關。具體來說,根據父區塊的GasUsed同GasLimit * 2/3的大小關係來計算得出。
- GasUsed:區塊內所有Transaction執行時所實際消耗的Gas總和。
- Nonce:一個64bit的雜湊數,它被應用在區塊的"挖掘"階段,並且在使用中會被修改。
Merkle-PatriciaTrie(MPT)是Ethereum用來儲存區塊資料的核心資料結構。最簡單理解是一個倒置的樹形結構,每個節點可能有若干個子節點,關於MPT在Ethereum中的實現細節在下文有專門介紹。
Root,TxHash和ReceiptHash,分別取自三個MPT型別物件:stateTrie, txTrie, 和receiptTrie的根節點雜湊值。用一個32byte的雜湊值,來代表一個有若干節點的樹形結構(或若干元素的陣列),這是為了加密。比如在Block的同步過程中,通過比對收到的TxHash,可以確認陣列成員transactions是否同步完整。
三者當中,TxHash和ReceiptHash的生成稍微特殊一點,因為這兩的資料來源是陣列,而不像stateTrie原本就存在。如何將陣列轉化成MPT結構?考慮到MPT專門儲存[k,v]型別資料,程式碼裡利用了點小技巧:將陣列中每個元素的索引作為k,該元素的RLP編碼值作為v,組成一個[k,v]鍵值對作為一個節點,這樣所有陣列元素作為節點逐個插入一個初始化為空的MPT,形成MPT結構。
在stateTrie,txTrie,receiptTrie這三個MPT結構的產生時間上,receiptTrie 必須在Block的所有交易執行完成才能生成;txTrie 理論上只需tx陣列transactions即可,不過依然被限制在所有交易執行完後才生成;最有趣的是stateTrie,由於它儲存了所有賬戶的資訊,比如餘額,發起交易次數,虛擬機器指令陣列等等,所以隨著每次交易的執行,stateTrie 其實一直在變化,這就使得Root值也在變化中。於是StateDB 定義了一個函式IntermediateRoot(),用來生成那一時刻的Root值:- // core/state/statedb.go
- func (s *StateDB) IntermediateRoot(deleteEmptyObjects bool) common.Hash
這個函式的返回值,代表了所有賬戶資訊的一個即時狀態。
關於Header.Root的生成時間,在上篇帖子提到的交易執行過程中,交易執行的入口函式StateProcessor.Process()在返回前呼叫了Engine.Finalize()。正是這個Finalize(),在內部呼叫上述IntermediateRoot()函式並賦值給header.Root。所以Root值就是在該區塊所有交易完成後,所有賬戶資訊的即時狀態。
Body結構體
Block的成員變數td 表示的是整個區塊連結串列從源頭創世塊開始,到當前區塊截止,累積的所有區塊Difficulty之和,td 取名totalDifficulty。從概念上可知,某個區塊與父區塊的td之差,就等於該區塊Header帶有的Difficulty值。
Body可以理解為Block裡的陣列成員集合,它相對於Header需要更多的記憶體空間,所以在資料傳輸和驗證時,往往與Header是分開進行的。
Uncles是Body非常特別的一個成員,從業務功能上說,它並不是Block結構體必須的,它的出現當然會佔用整個Block計算雜湊值時更長的時間,目的是為了抵消整個Ethereum網路中那些計算能力特別強大的節點會對區塊的產生有過大的影響力,防止這些節點破壞“去中心化”這個根本宗旨。官方描述可見ethereum-wiki
Block的唯一識別符號
同Ethereum世界裡的其他物件類似,Block物件的唯一識別符號,就是它的(RLP)雜湊值。需要注意的是,Block的雜湊值,等於其Header成員的(RLP)雜湊值。
- // core/types/Block.go
- func (b *Block) Hash() common.Hash {
- if hash := b.hash.Load(); hash != nil {
- return hash.(common.Hash)
- }
- v := b.header.Hash()
- b.hash.Store(v)
- return v
- }
- func (h *Header) Hash() common.Hash {
- return rlpHash(h)
- }
Block的雜湊值等於其Header的(RLP)雜湊值,這就從根本上明確了Block(結構體)和Header表示的是同一個區塊物件。考慮到這兩種結構體所佔記憶體空間的差異,這種設計可以帶來很多便利。比如在資料傳輸時,完全可以先傳輸Header物件,驗證通過後再傳輸Block物件,收到後還可以利用二者的成員雜湊值做相互驗證。
成員分散儲存在底層資料庫
Header和Block的主要成員變數,最終還是要儲存在底層資料庫中。Ethereum 選用的是LevelDB, 屬於非關係型資料庫,儲存單元是[k,v]鍵值對。我們來看看具體的儲存方式(core/database_util.go)
| key | value |
| 'h' + num + hash | header's RLP raw data |
| 'h' + num + hash + 't' | td |
| 'h' + num + 'n' | hash |
| 'H' + hash | num |
| 'b' + num + hash | body's RLP raw data |
| 'r' + num + hash | receipts RLP |
| 'l' + hash | tx/receipt lookup metadata |
這裡的hash就是該Block(或Header)物件的RLP雜湊值,在程式碼中也被稱為canonical hash;num是Number的uint64型別,大端(big endian)整型數。可以發現,num 和 hash是key中出現最多的成分;同時num和hash還分別作為value被單獨儲存,而每當此時則另一方必組成key。這些資訊都在強烈的暗示,num(Number)和hash是Block最為重要的兩個屬性:num用來確定Block在整個區塊鏈中所處的位置,hash用來辨識惟一的Block/Header物件。
通過以上的設計,Block結構體的所有重要成員,都被儲存進了底層資料庫。當所有Block物件的資訊都已經寫進資料庫後,我們就可以使用BlockChain結構體來處理整個塊鏈。
2. HeaderChain和BlockChain
BlockChain結構體被用來管理整個區塊單向連結串列,在一個Ethereum客戶端軟體(比如錢包)中,只會有一個BlockChain物件存在。同Block/Header的關係類似,BlockChain還有一個成員變數型別是HeaderChain, 用來管理所有Header組成的單向連結串列。當然,HeaderChain在全域性範圍內也僅有一個物件,並被BlockChain持有(準確說是HeaderChain只會被BlockChain和LightChain持有,LightChain類似於BlockChain,但預設只處理Headers,不過依然可以下載bodies和receipts)。它們的UML關係圖如下所示:
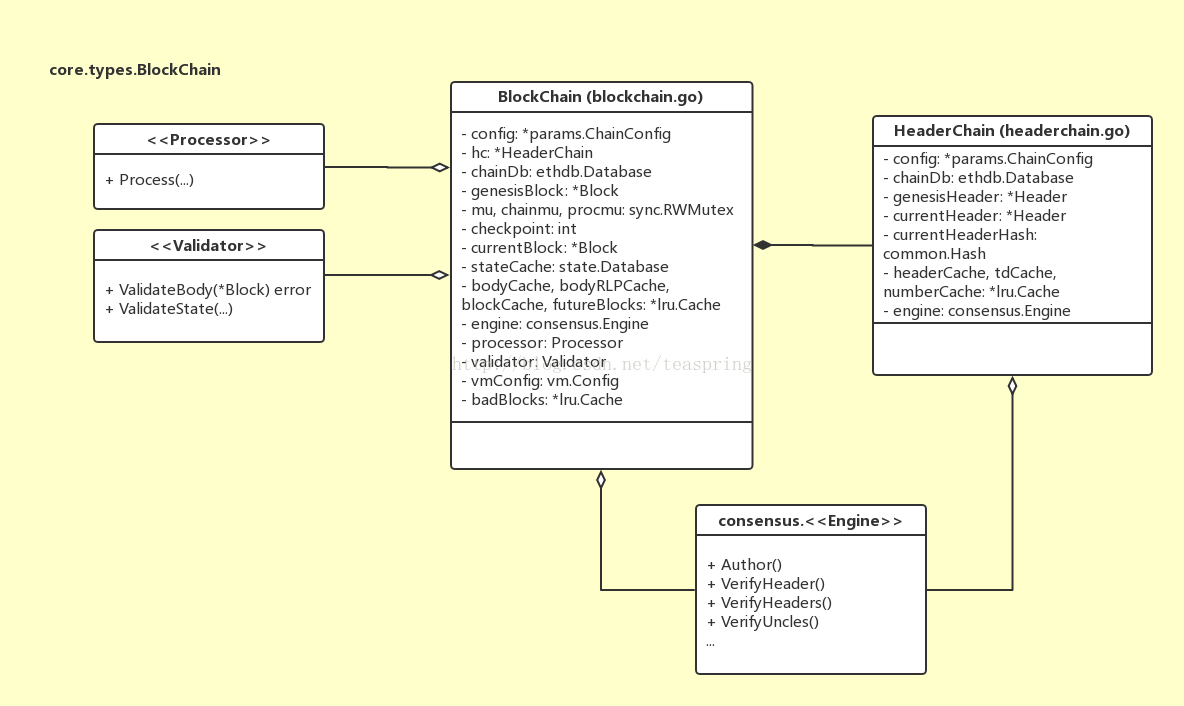
在結構體的設計上,BlockChain 同HeadeChain有諸多類似之處。比如二者都有相同的ChainConfig物件,有相同的Database介面行為變數以提供[k,v]資料的讀取和寫入;BlockChain 有成員genesisBlock和currentBlock,分別對應創世塊和當前塊,而HeaderChain則有genesisHeader和currentHeader;BlockChain 有bodyCache,blockCache 等成員用以快取高頻呼叫物件,而HeaderChain則有headerCache, tdCache, numberCache等快取成員變數。除此之外,BlockChain 相對於HeaderChain主要增多了Processor和Validator兩個介面行為變數,前者用以執行所有交易物件,後者可以驗證諸如Body等資料成員的有效性。
Engine是共識演算法定義的行為介面。共識演算法是整個數字貨幣體系最重要的概念之一,它在理論上的完整性,有力的支撐了“去中心化”這個偉大設想的實現。落實在程式碼層面,consensus.Engine就是Ethereum系統裡共識演算法的一個主要行為介面,它基於符合某種共識演算法規範的演算法庫,提供包括VerifyHeaders(),VerifyUncles()等一系列涉及到資料合法性的關鍵函式。不僅僅BlockChain和HeaderChain結構體,在Ethereum系統裡,所有跟驗證區塊物件相關的操作都會呼叫Engine行為介面來完成。目前存在兩種共識演算法規範,一種是基於運算能力(proof-of-work),叫Ethash;另一種基於某個投票機制(proof-of-authority),叫Clique。具體內容在之後的文章中會有更多展開。
區塊鏈的操作
從邏輯上講,既然BlockChain和HeaderChain都管理著一個類似單向連結串列的結構,那麼它們提供的操作方法肯定包括插入,刪除,和查詢。
查詢比較簡單,以BlockChain為例,它有一個成員currentBlock,指向當前最新的Block,而HeaderChain也有一個類似的成員currentHeader。除此之外,底層資料庫裡還分別存有當前最新Block和Header的canonical hash:
| key | value |
| "LastHeader" | hash |
| "LastBlock" | hash |
| "LastFast" | hash |
以BlockChain為例,通過"LastBlock"為key從資料庫中獲取最新的Block之後,用num逐一遍歷,得到目標Block的num後,用'h'+num+'n'作key,就可以從資料庫中獲取目標canonical hash。
插入和刪除。區塊鏈跟普通單向連結串列有一點非常明顯的不同,在於Header的前向指標ParentHash是不能修改的,即當前區塊的父區塊是不能修改的。所以在插入的實現中,當決定寫入一個新的Header進底層資料庫時,從這個Header開始回溯,要保證它的parent,以及parent的parent等等,都已經寫入資料庫了。只有這樣,才能確保從創世塊(num為0)起始,直到當前新寫入的區塊,整個鏈式結構是完整的,沒有中斷或分叉。刪除的情形也類似,要從num最大的區塊開始,逐步回溯。在BlockChain的操作裡,刪除一般是伴隨著插入出現的,即當需要插入新區塊時,才可能有舊的區塊需要被刪除,這種情形在程式碼裡被稱為reorg。
3. 精巧的Merkle-PatriciaTrie
Ethereum 使用的Merkle-PatriciaTrie(MPT)結構,源自於Trie結構,又分別繼承了PatriciaTrie和MerkleTree的優點,並基於內部資料的特性,設計了全新的節點體系和插入/載入機制。
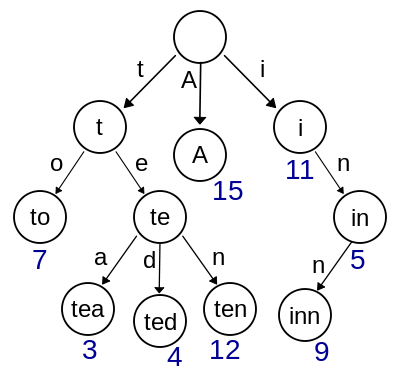
Trie,又稱為字典樹或者字首樹(prefix tree),屬於查詢樹的一種。它與平衡二叉樹的主要不同點包括:每個節點資料所攜帶的key不會儲存在Trie的節點中,而是通過該節點在整個樹形結構裡位置來體現;同一個父節點的子節點,共享該父節點的key作為它們各自key的字首,因此根節點key為空;待儲存的資料只存於葉子節點中,非葉子節點幫助形成葉子節點key的字首。下圖來自wiki-Trie,展示了一個簡單的Trie結構。
PatriciaTrie,又被稱為RadixTree或緊湊字首樹(compact prefix tree),是一種空間使用率經過優化的Trie。與Trie不同的是,PatriciaTrie裡如果存在一個父節點只有一個子節點,那麼這個父節點將與其子節點合併。這樣可以縮短Trie中不必要的深度,大大加快搜索節點速度。
MerkleTree,也叫雜湊樹(hash tree),是密碼學的一個概念,注意理論上它不一定是Trie。在雜湊樹中,葉子節點的標籤是它所關聯資料塊的雜湊值,而非葉子節點的標籤是它的所有子節點的標籤拼接而成字串的雜湊值。雜湊樹的優勢在於,它能夠對大量的資料內容迅速作出高效且安全的驗證。假設一個hash tree中有n個葉子節點,如果想要驗證其中一個葉子節點是否正確-即該節點資料屬於源資料集合並且資料本身完整,所需雜湊計算的時間複雜度是是O(log(n)),相比之下hash list大約需要時間複雜度O(n)的雜湊計算,hash tree的表現無疑是優秀的。
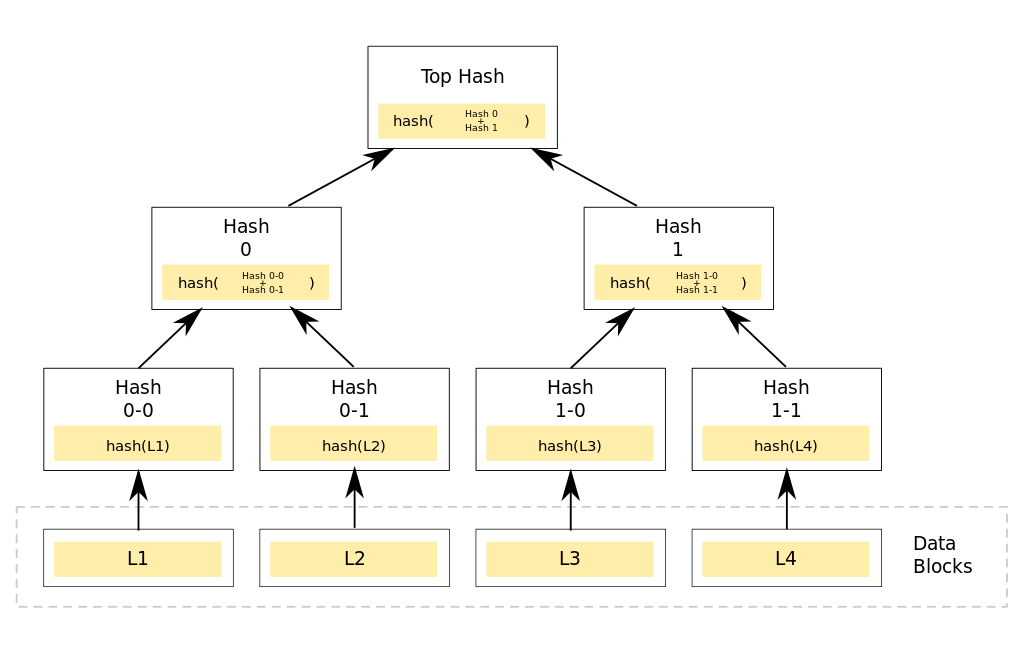
上圖來自wiki-MerkleTree,展示了一個簡單的二叉雜湊樹。四個有效資料塊L1-L4,分別被關聯到一個葉子節點上。Hash0-0和Hash0-1分別等於資料塊L1和L2的雜湊值,而Hash0則等於Hash0-0和Hash0-1二者拼接成的新字串的雜湊值,依次類推,根節點的標籤topHash等於Hash0和Hash1二者拼接成的新字串的雜湊值。
雜湊樹最主要的應用場景是p2p網路中的資料傳輸。因為p2p網路中可能存在未知數目的不可信資料來源,所以確保下載到的資料正確可信並且無損壞無改動,就顯得非常重要。雜湊樹可用來解決這個問題:每個待下載檔案按照某種方式分割成若干小塊後,組成類似上圖的雜湊樹。首先從一個絕對可信的資料來源獲取該檔案對應雜湊樹的根節點雜湊值(top hash),有了這個可靠的top hash後,就可以開始從整個p2p網路下載檔案。不同的資料部分可以從不同的源下載,由於雜湊樹中任意的分支樹都可以單獨驗證雜湊值,所以一旦發現任何資料部分無法通過驗證,都可以切換到其他資料來源進行下載那部分資料。最終,完整下載檔案所對應雜湊樹的top hash值,一定要與我們的可靠top hash相等。
Merkle-Patricia Trie(MPT)的實現
MPT是Ethereum自定義的Trie型資料結構。在程式碼中,trie.Trie結構體用來管理一個MPT結構,其中每個節點都是行為介面Node的實現類。下圖是Trie結構體和node介面族的UML關係圖:
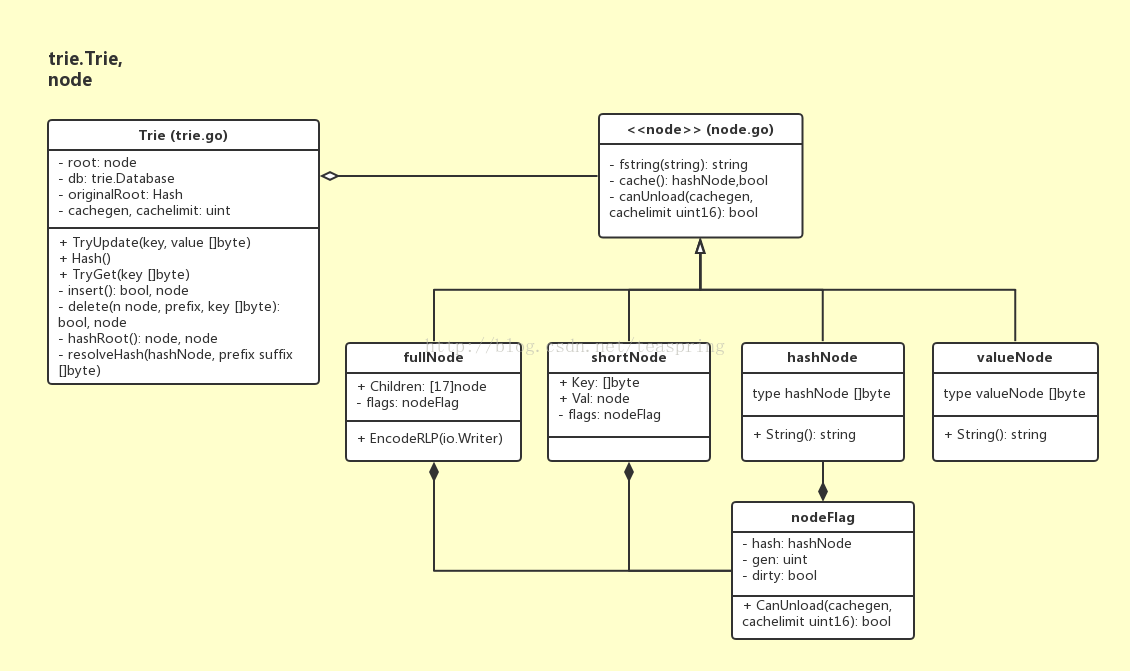
在Trie結構體中,成員root始終作為整個MPT的根節點;originalRoot的作用是在建立Trie物件時承接入參hashNode;cacheGen是cache次數的計數器,每次Trie的變動提交後(寫入的物件可由外部引數傳入),cacheGen自增1。Trie結構體提供包括對節點的插入、刪除、更新,所有節點改動的提交(寫入到傳入引數),以及返回整個MPT的雜湊值。
node介面族擔當整個MPT中的各種節點,node介面分四種實現: fullNode,shortNode,valueNode,hashNode,其中只有fullNode和shortNode可以帶有子節點。
fullNode 是一個可以攜帶多個子節點的父(枝)節點。它有一個容量為17的node陣列成員變數Children,陣列中前16個空位分別對應16進位制(hex)下的0-9a-f,這樣對於每個子節點,根據其key值16進位制形式下的第一位的值,就可掛載到Children陣列的某個位置,fullNode本身不再需要額外key變數;Children陣列的第17位,留給該fullNode的資料部分。fullNode明顯繼承了原生trie的特點,而每個父節點最多擁有16個分支也包含了基於總體效率的考量。
shortNode 是一個僅有一個子節點的父(枝)節點。它的成員變數Val指向一個子節點,而成員Key是一個任意長度的字串(位元組陣列[]byte)。顯然shortNode的設計體現了PatriciaTrie的特點,通過合併只有一個子節點的父節點和其子節點來縮短trie的深度,結果就是有些節點會有長度更長的key。
valueNode 充當MPT的葉子節點。它其實是位元組陣列[]byte的一個別名,不帶子節點。在使用中,valueNode就是所攜帶資料部分的RLP雜湊值,長度32byte,資料的RLP編碼值作為valueNode的匹配項儲存在資料庫裡。
這三種類型覆蓋了一個普通Trie(也許是PatriciaTrie)的所有節點需求。任何一個[k,v]型別資料被插入一個MPT時,會以k字串為路徑沿著root向下延伸,在此次插入結束時首先成為一個valueNode,k會以自頂點root起到到該節點止的key path形式存在。但之後隨著其他節點的不斷插入和刪除,根據MPT結構的要求,原有節點可能會變化成其他node實現型別,同時MPT中也會不斷裂變或者合併出新的(父)節點。比如:
- 假設一個shortNode S已經有一個子節點A,現在要新插入一個子節點B,那麼會有兩種可能,要麼新節點B沿著A的路徑繼續向下,這樣S的子節點會被更新;要麼S的Key分裂成兩段,前一段分配給S作為新的Key,同時裂變出一個新的fullNode作為S的子節點,以同時容納B,以及需要更新的A。
- 如果一個fullNode原本只有兩個子節點,現在要刪除其中一個子節點,那麼這個fullNode就會退化為shortNode,同時保留的子節點如果是shortNode,還可以跟它再合併。
- 如果一個shortNode的子節點是葉子節點同時又被刪除了,那麼這個shortNode就會退化成一個valueNode,成為一個葉子節點。
諸如此類的情形還有很多,提前設想過這些案例,才能正確實現MPT的插入/刪除/查詢等操作。當然,所有查詢樹(search tree)結構的操作,免不了用到遞迴。
特殊的那個 - hashNode
hashNode 跟valueNode一樣,也是字元陣列[]byte的一個別名,同樣存放32byte的雜湊值,也沒有子節點。不同的是,hashNode是fullNode或者shortNode物件的RLP雜湊值,所以它跟valueNode在使用上有著莫大的不同。
在MPT中,hashNode幾乎不會單獨存在(有時遍歷遇到一個hashNode往往因為原本的node被摺疊了),而是以nodeFlag結構體的成員(nodeFlag.hash)的形式,被fullNode和shortNode間接持有。一旦fullNode或shortNode的成員變數(包括子結構)發生任何變化,它們的hashNode就一定需要更新。所以在trie.Trie結構體的insert(),delete()等函式實現中,可以看到除了新建立的fullNode、shortNode,那些子結構有所改變的fullNode、shortNode的nodeFlag成員也會被重設,hashNode會被清空。在下次trie.Hash()呼叫時,整個MPT自底向上的遍歷過程中,所有清空的hashNode會被重新賦值。這樣trie.Hash()結束後,我們可以得到一個根節點root的hashNode,它就是此時此刻這個MPT結構的雜湊值。上文中提到的,Block的成員變數Root、TxHash、ReceiptHash的生成,正是源出於此。
明顯的,hashNode體現了MerkleTree的特點:每個父節點的雜湊值來源於所有子節點雜湊值的組合,一個頂點的雜湊值能夠代表一整個樹形結構。valueNode加上之前的fullNode,shortNode,valueNode,構成了一個完整的Merkle-PatriciaTrie結構,很好的融合了各種原型結構的優點,又根據Ethereum系統的實際情況,作了實際的優化和平衡。MPT這個資料結構在設計中的種種細節,的確值得好好品味。
函式實現
程式碼方面,建立新nodeFlag物件的函式叫newFlags()。在nodeFlag初始化過程中,bool成員dirty置為true,表明了所代表的父節點有改動需要提交,同時hashNode成員hash,直接設空。
- // trie/trie.go
- func (t *Trie) newFlag() nodeFlag {
- return nodeFlag{dirty: true, gen: t.cacheGen}
- }
每個hashNode被賦值的過程,就是它所代表的fullNode或shortNode被摺疊(collapse)的過程。基於效率和資料安全考慮,trie.Trie僅提供整個MPT結構的摺疊操作Hash()函式,它預設從頂點root開始遍歷。
- func (t *Trie) Hash() common.Hash {
- hash, cached, _ := t.hashRoot(db:nil)
- t.root = hash
- return ...
- }
- func (t *Trie) hashRoot(db DatabaseWriter) (node, node, error) {
- if (t.root == nil) {...}
- h := newHasher(t.cachegen, t.cachelimit)
- return h.hash(t.root, db, force:true)
- }
- // trie/hasher.go
- func (h *hasher) hash(n node, db DatabaseWriter, force bool) (hash node, cached node, error)
- func (h *hasher) hashChildren(original node, db DatabaseWriter) (hash node, cached node, error)
- func (h *hasher) store(n node, db DatabaseWriter, force bool) (node, error)
注意到hash()和hashChildren()返回兩個node型別物件,第一個@hash是入參n經過摺疊的hashNode雜湊值,第二個@cached是沒有經過摺疊的n,並且n的hashNode還被賦值了。
由於Hasher.hash()有一個數據庫介面型別的引數,這樣在摺疊MPT過程中,如果db不為空,就把每次計算hashNode時的雜湊值和它對應的節點RLP編碼值一起存進資料庫裡,這也正是Commit()的邏輯。
- func (t *Trie) Commit() (root hash, error) {
- if t.db == nil {...}
- return t.CommitTo(t.db)
- }
- func (t *Trie) CommitTo(db DatabaseWriter) (root common.Hash, error) {
- hash, cached, error := t.hashRoot(db)
- t.root = cached
- ...
- }
在MPT的查詢,插入,刪除中,如果遍歷過程中遇到一個hashNode,首先需要從資料庫裡以這個雜湊值為k,讀取出相匹配的v,然後再將v解碼恢復成fullNode或shortNode。在程式碼中這個過程叫resolve。
- // trie/trie.go
- func (t *trie) resolve(n, prefix) (node,error) {
- if n, ok := n.(hashNode); ok {
- return resolveHash(n, prefix)
- }
- return n, nil
- }
- func (t *Trie) resolveHash(n hashNode, prefix []byte) (node,error) {
- enc, err := t.db.Get(n)
- ...
- dec := mustDecodeNode(n, enc, t.cachegen)
- return dec, nil
- }
MPT中對key的編碼
當[k,v]資料插入MPT時,它們的k(key)都必須經過編碼。這時對key的編碼,要保證原本是[]byte型別的key能夠以16進位制形式按位進入fullNode.Children[],因為Children[]陣列最多隻能容納16個子節點。相應的,Ethereum程式碼中在這裡定義了一種編碼方式叫Hex,將1byte的字元大小限制在4bit(16進位制)以內。
先來看Hex編碼的實現,這裡將原本[]byte形式稱之為keybytes,Hex編碼的基本邏輯如下圖:
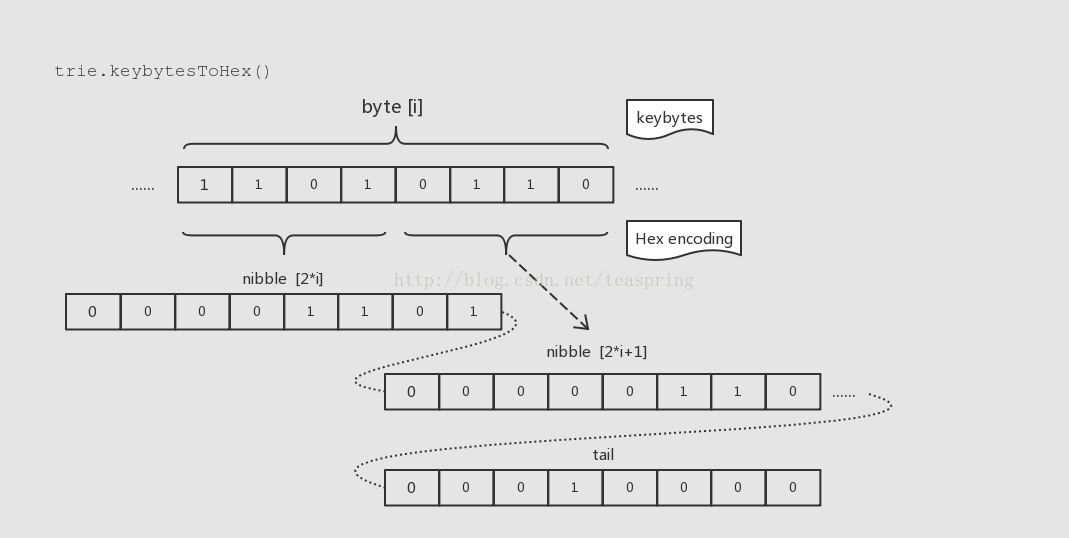
很簡單,就是將keybytes中的1byte資訊,將高4bit和低4bit分別放到兩個byte裡,最後在尾部加1byte標記當前屬於Hex格式。這樣新產生的key雖然形式還是[]byte,但是每個byte大小已經被限制在4bit以內,程式碼中把這種新資料的每一位稱為nibble。這樣經過編碼之後,帶有[]nibble格式的key的資料就可以順利的進入fullNode.Children[]陣列了。
Hex編碼雖然解決了key是keybytes形式的資料插入MPT的問題,但代價也很大,就是資料冗餘。典型的如shortNode,目前Hex格式下的Key,長度會變成是原來keybytes格式下的兩倍。這一點對於節點的雜湊計算,比如計算hashNode,影響很大。所以Ethereum又定義了另一種編碼格式叫Compact,用來對Hex格式進行優化。
Compact編碼又叫hex prefix編碼,它的主要意圖是將Hex格式的字串恢復到keybytes的格式,同時要加入當前Compact格式的標記位,還要考慮在奇偶不同長度Hex格式字串下,避免引入多餘的byte。
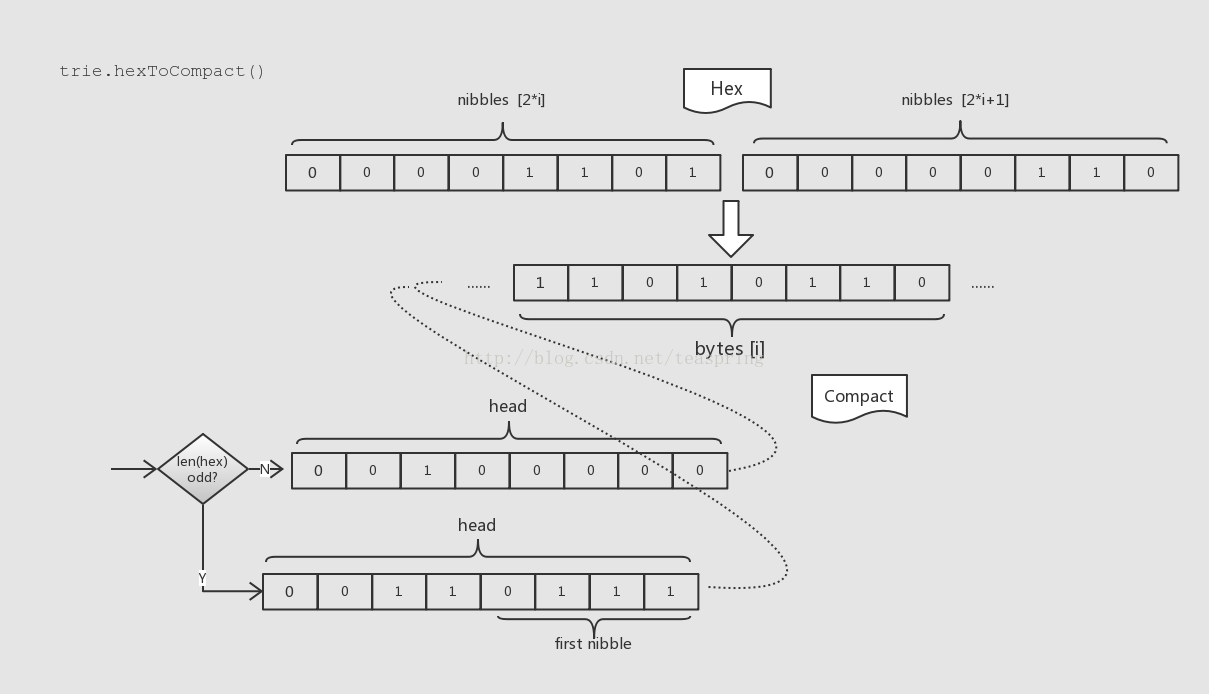
如上圖所示,Compact編碼首先將Hex尾部標記byte去掉,然後將原本每2 nibble的資料合併到1byte;增添1byte在輸出資料頭部以放置Compact格式標記位;如果輸入Hex格式字串有效長度為奇數,還可以將Hex字串的第一個nibble放置在標記位byte裡的低4bit。
Key編碼的設計細節,也體現出MPT整個資料結構設計的思路很完整。
4. 資料庫體系
到目前為止,Ethereum系統中區塊資料的呈現,組織管理已經介紹了不少,我們可以開始探討儲存部分了。先來看看資料儲存部分的UML關係圖。
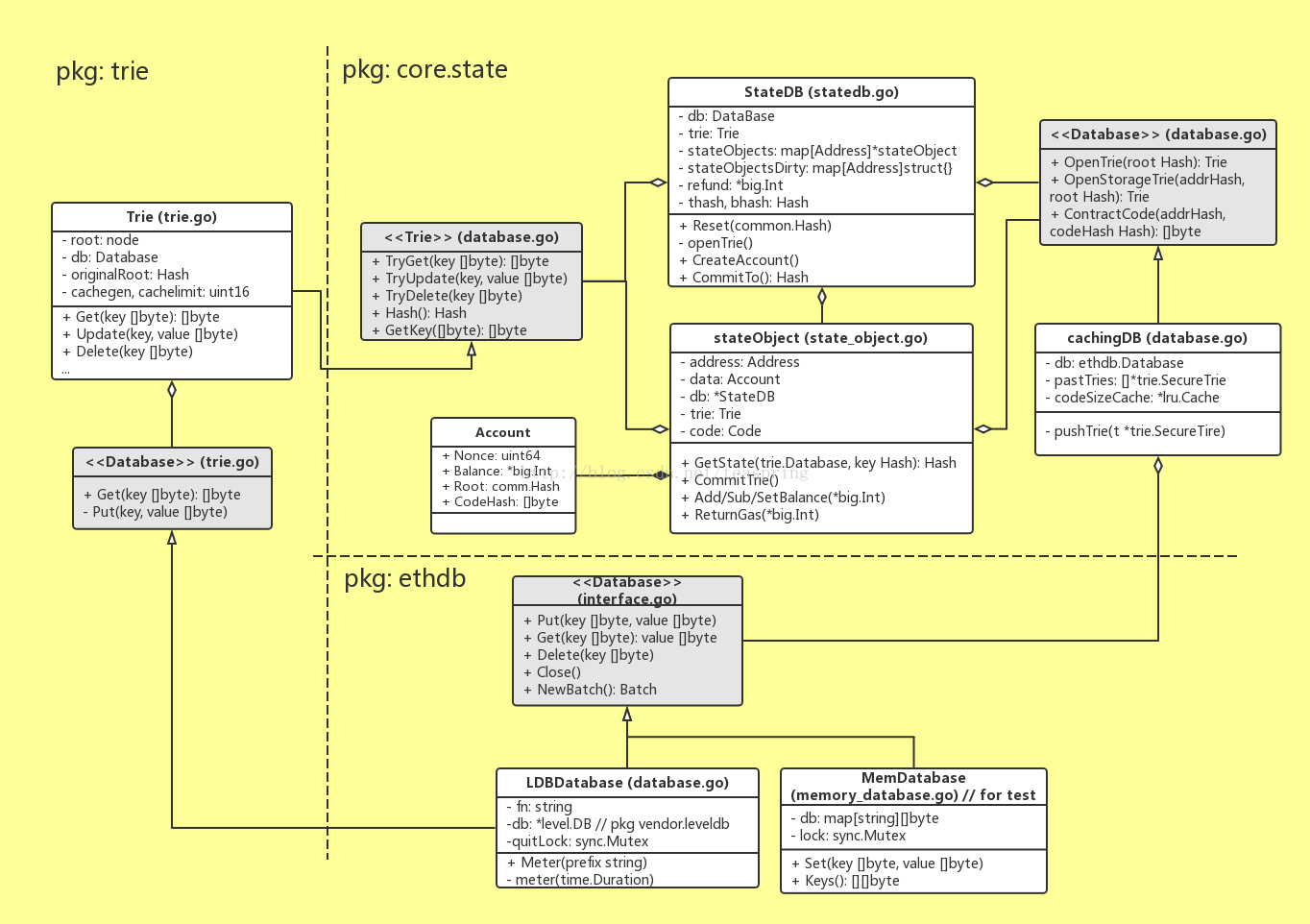
屬於Ethereum程式碼範圍內的最底層資料庫是ethdb.LDBDatabase,它通過持有一個levelDB的物件,最終為Ethereum世界裡所有需要儲存/讀取[k,b]的需求提供服務。
留意到圖中多次出現一種類似的設計模式,比如trie.Trie持有一個本地介面trie.<<Database>>,而後者的具體實現是ethdb.LDBDatabase。這種設計模式其實是golang的語法帶來的。在golang中,一個結構體(類)要實現另一個介面的所有方法,不必在結構體宣告時顯式繼承那個介面,只要完全實現那些方法。這樣,當一個結構體想呼叫另一個包路徑下結構體的多個方法時,可以宣告一個本地介面,帶有幾個同想要呼叫方法完全一樣的方法,就可以了,這種方式的優點是不同包之間的程式碼更充分的解耦合。所以在上圖中,這些輔助性的本地介面全都被標為灰色,只需要關注實際呼叫的實現類就好了。
系統設計中,在底層資料庫模組和業務模型之間,往往需要設定本地儲存模組,它面向業務模型,可以根據業務需求靈活的設計各種儲存格式和單元,同時又連線底層資料庫,如果底層資料庫(或者第三方API)有變動,可以大大減少對業務模組的影響。在Ethereum世界裡,StateDB就擔任這個角色,它通過大量的stateObject物件集合,管理所有“賬戶”資訊。
面向業務的儲存模組 - StateDB
StateDB有一個trie.Trie型別成員trie,它又被稱為storage trie或stte trie,這個MPT結構中儲存的都是stateObject物件,每個stateObject物件以其地址(20 bytes)作為插入節點的Key;每次在一個區塊的交易開始執行前,trie由一個雜湊值(hashNode)恢復出來。另外還有一個map結構,也是存放stateObject,每個stateObject的地址作為map的key。那麼問題來了,這些資料結構之間是怎樣的關係呢?
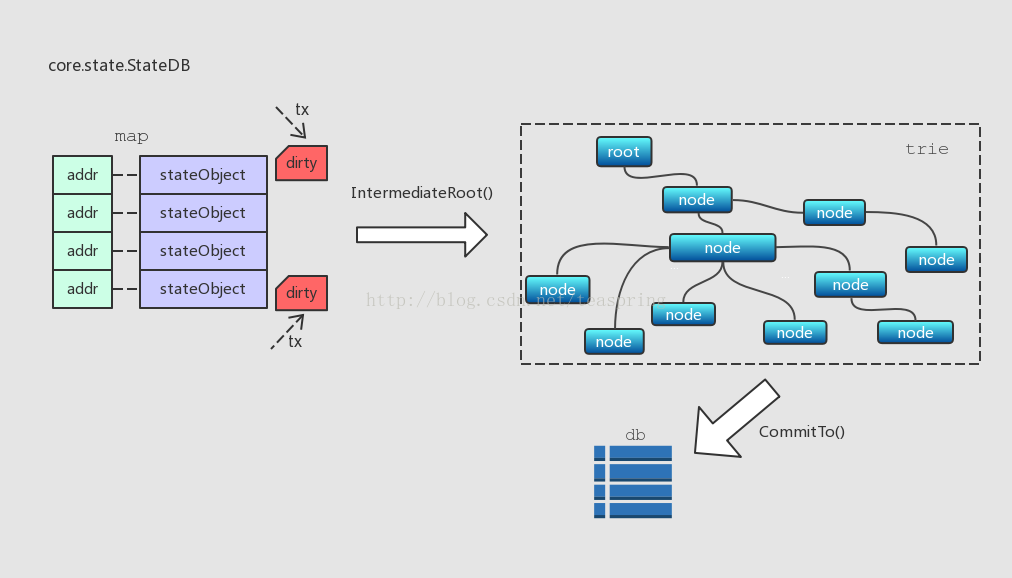
如上圖所示,每當一個stateObject有改動,亦即“賬戶”資訊有變動時,這個stateObject物件會更新,並且這個stateObject會標為dirty,此時所有的資料改動還僅僅儲存在map裡。當IntermediateRoot()呼叫時,所有標為dirty的stateObject才會被一起寫入trie。而整個trie中的內容只有在CommitTo()呼叫時被一起提交到底層資料庫。可見,這個map被用作本地的一級快取,trie是二級快取,底層資料庫是第三級,各級資料結構的界限非常清晰,這樣逐級快取資料,每一級資料向上一級提交的時機也根據業務需求做了合理的選擇。
StateDB中賬戶狀態的版本管理
StateDB還可以管理賬戶狀態的版本。這個功能用到了幾個結構體:journal,revision,先來看看UML關係圖:
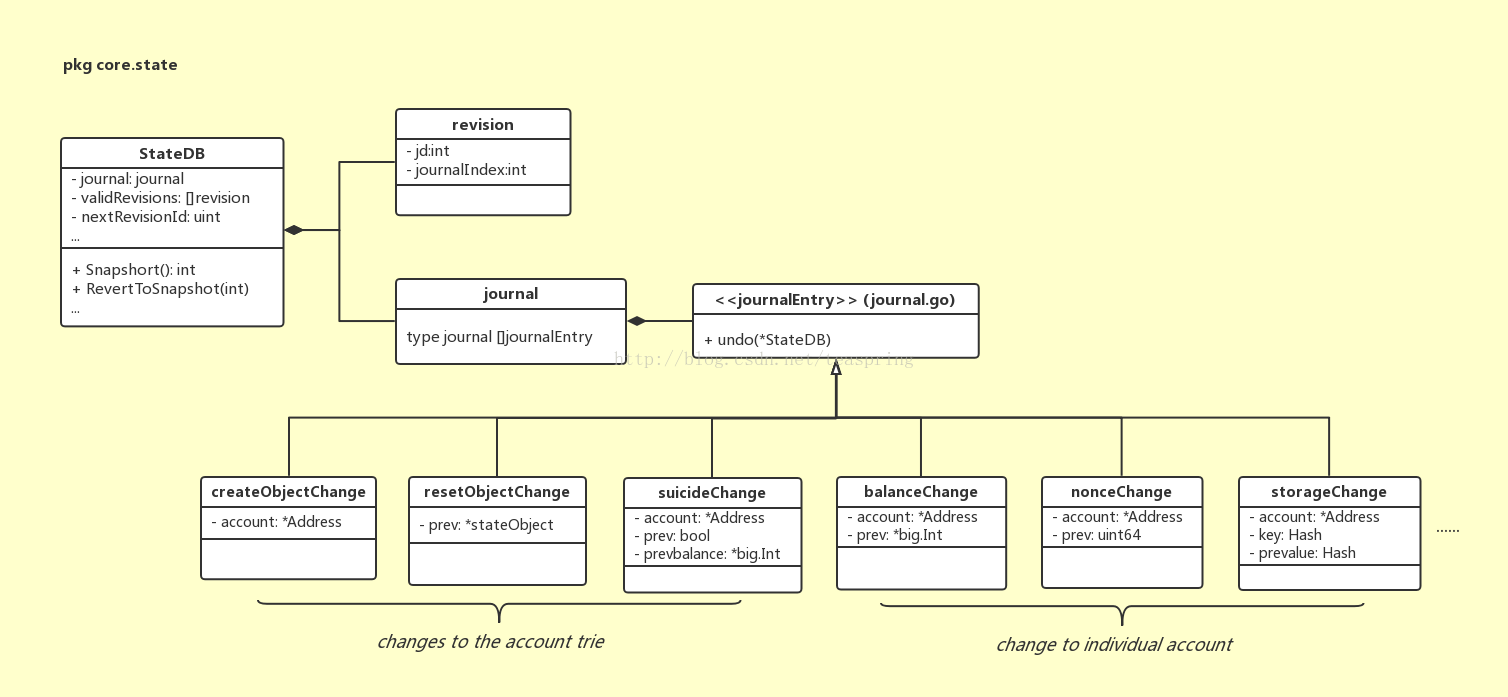
其中journal物件是journalEntry的雜湊,長度不固定,可任意新增元素。介面journalEntry存在若干種實現體,描述了從單個賬戶操作(賬戶餘額,發起合約次數等),到account trie變化(建立新賬戶物件,賬戶消亡)等各種最小事件。revision結構體,用來描述一個‘版本’,它的兩個整型成員jd和journalIndex,都是基於journal雜湊進行操作的。

上圖簡述了StateDB中賬戶狀態的版本是如何管理的。首先journal雜湊會隨著系統執行不斷的增長,記錄所有發生過的單位事件;當某個時刻需要產生一個賬戶狀態版本時,程式碼中相應的是Snapshop()呼叫,會產生一個新revision物件,記錄下當前journal雜湊的長度,和一個自增1的版本號。
基於以上的設計,當發生回退要求時,只要根據相應的revision中的journalIndex,在journal雜湊上,根據所記錄的所有journalEntry,即可使所有賬戶回退到那個狀態。
Ethereum裡的賬戶 - stateObject
每個stateObject物件管理著Ethereum世界裡的一個“賬戶”。stateObject有一個成員變數data,型別是Accunt結構體,裡面存有賬戶Ether餘額,合約發起次數,最新發起合約指令集的雜湊值,以及一個MPT結構的頂點雜湊值。
stateObject內部也有一個Trie型別的成員trie,被稱為storage trie,它裡面存放的是一種被稱為State的資料。State跟每個賬戶相關,格式是[Hash, Hash]鍵值對。有意思的是,stateObject內部也有類似StateDB一樣的二級資料快取機制,用來快取和更新這些State。
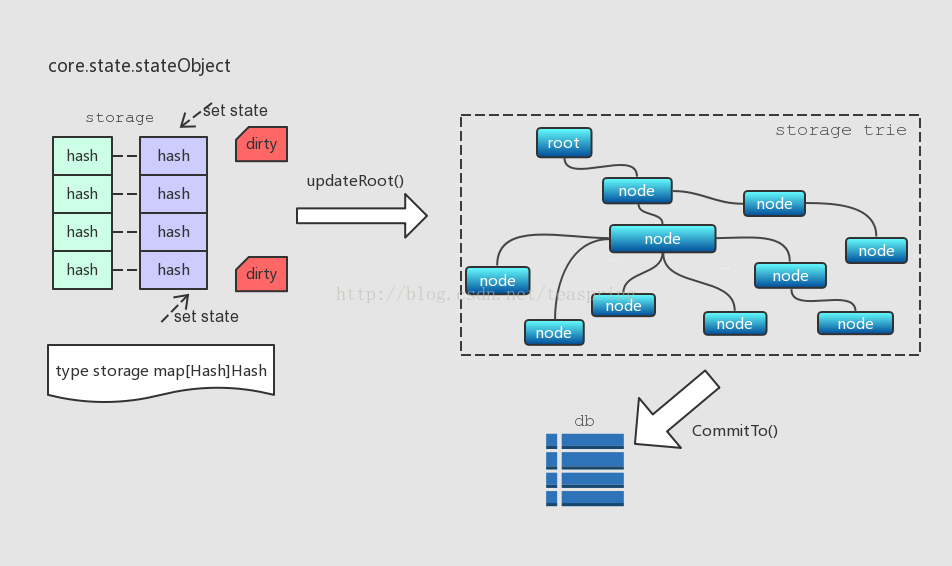
stateObject定義了一種型別名為storage的map結構,用來存放[]Hash,Hash]型別的資料對,也就是State資料。當SetState()呼叫發生時,storage內部State資料被更新,相應標示為"dirty"。之後,待有需要時(比如updateRoot()呼叫),那些標為"dirty"的State資料被一起寫入storage trie,而storage trie中的所有內容在CommitTo()呼叫時再一起提交到底層資料庫。
State資料略顯神祕,目前筆者尚未完全理解它的含義,在程式碼裡,僅僅查到某些合約指令中會呼叫SetState(),來更新某個stateObject中的State資料。
小結
任何一個系統中,資料部分的佔用空間,執行效率當然會影響到整體效能。如何簡潔完整的呈現資料,並涵蓋業務模型下的大大小小各種需求;如何高效的管理資料,使得插入、刪除、查詢資料更快速;如何在業務模組和底層資料庫之間安排面向業務的、介面友好的本地儲存模組,使得記憶體佔用更緊湊,提交和回退資料更加安全等等,都是值得全面思考的。從本文中,可以看到整個Ethereum系統的架構設計、程式碼實現上,對於以上各個話題都進行了諸多考量,值得同業者學習參考。
- Block結構體主要分為Header和Body,Header相對輕量,涵蓋了Block的所有屬性,包括特徵標示,前向指標,和內部資料集的驗證雜湊值等;Body相對重量,持有內部資料集。每個Block的Header部分,Body部分,以及一些特徵屬性,都以[k,v]形式單獨儲存在底層資料庫中。
- BlockChain管理Block組成的一個單向連結串列,HeaderChain管理Header組成的單向連結串列,並且BlockChain持有HeaderChain。在做插入/刪除/查詢時,要注意回溯,以及資料庫中相應的增刪。
- Merkle-PatriciaTrie(MPT)資料結構用來組織管理[k,v]型資料,它設計了靈活多變的節點體系和編碼格式,既融合了多種原型結構的優點,又兼顧了業務需求和執行效率。
- StateDB作為本地儲存模組,它面向業務模型,又連線底層資