
以太坊資料儲存原始碼分析
上一篇主要講解了MPT的基本原理,這篇分析一下以太坊資料儲存相關的流程。
首先介紹一下MPT的儲存流程,然後依次分析StateDB、Transactions、Receipts的儲存,這3棵樹的Merkle Root最終會儲存到區塊Header中的Root、TxHash、ReceiptHash欄位。
1.MPT儲存流程
從圖中可以看出,MPT的儲存涉及3種編碼方式:
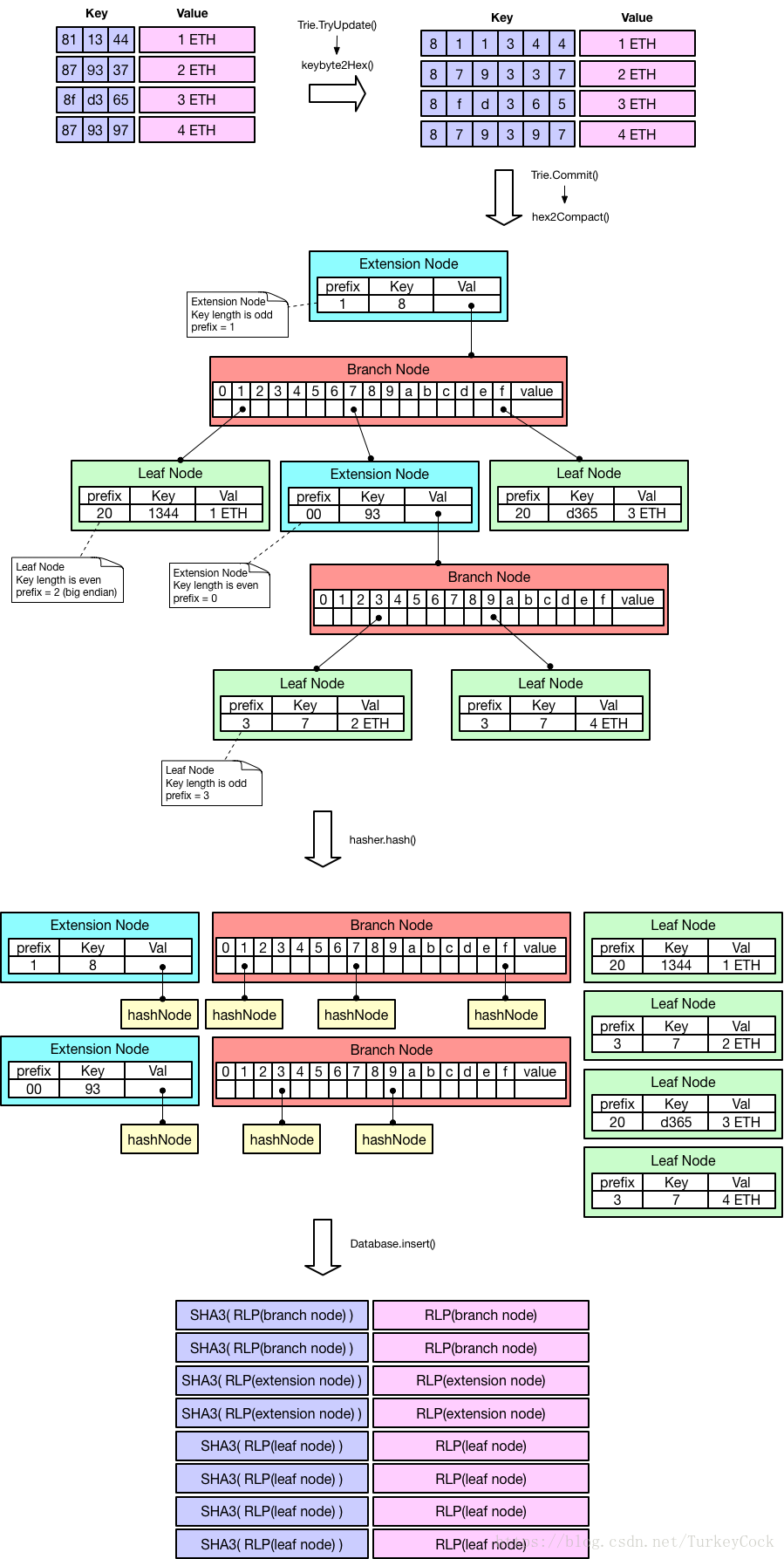
- KeyBytes編碼
- Hex編碼
- Compact編碼
在完成Compact編碼後,會通過摺疊操作把子結點替換成子結點的hash值,然後以鍵值對的形式將所有結點儲存到資料庫中。下面詳細介紹上面3中編碼方式。
1.1 KeyBytes編碼
即原始關鍵字,比如圖中的0x811344、0x879337等。每個位元組中包含2個nibble(半位元組,4 bits),每個nibble的數值範圍時0x0~0xF。
1.2 Hex編碼
由於我們需要以nibble為單位進行編碼並插入MPT,因此需要把一個位元組拆分成兩個,轉換為Hex編碼。
編碼轉換是在Trie.TryUpdate()中觸發的,具體轉換程式碼參見trie/encoding.go:
func keybytesToHex(str []byte) []byte { l := len(str)*2 + 1 var nibbles = make([]byte, l) for i, b := range str { nibbles[i*2] = b / 16 nibbles[i*2+1] = b % 16 } nibbles[l-1] = 16 return nibbles }
1.3 Compact編碼
當我們需要把記憶體中MPT儲存到資料庫中時,還需要再把兩個位元組合併為一個位元組進行儲存,這時候會碰到2個問題:
- 關鍵字長度為奇數,有一個位元組無法合併
- 需要區分結點是擴充套件結點還是葉子結點
為了解決這個問題,以太坊設計了一種Compact編碼方式,具體規則如下:
- 擴充套件結點,關鍵字長度為偶數,前面加00字首
- 擴充套件結點,關鍵字長度為奇數,前面加1字首(字首和第1個位元組合併為一個位元組)
- 葉子結點,關鍵字長度為偶數,前面加20字首(因為是Big Endian)
- 葉子結點,關鍵字長度為奇數,前面加3字首(字首和第1個位元組合併為一個位元組)
編碼轉換是在Trie.Commit()時觸發的,具體呼叫在hasher.hashChildren()函式中,轉換程式碼參見trie/encoding.go:
func hexToCompact(hex []byte) []byte {
terminator := byte(0)
if hasTerm(hex) {
terminator = 1
hex = hex[:len(hex)-1]
}
buf := make([]byte, len(hex)/2+1)
buf[0] = terminator << 5 // the flag byte
if len(hex)&1 == 1 {
buf[0] |= 1 << 4 // odd flag
buf[0] |= hex[0] // first nibble is contained in the first byte
hex = hex[1:]
}
decodeNibbles(hex, buf[1:])
return buf
}
2. StateDB的儲存
StateDB中儲存了很多stateObject,而每一個stateObject則代表了一個以太坊賬戶,包含了賬戶的地址、餘額、nonce、合約程式碼hash等狀態資訊。所有賬戶的當前狀態在以太坊中被稱為“世界狀態”,在每次挖出或者接收到新區塊時需要更新世界狀態。
為了能夠快速檢索和更新賬戶狀態,StateDB採用了兩級快取機制,參見下圖:
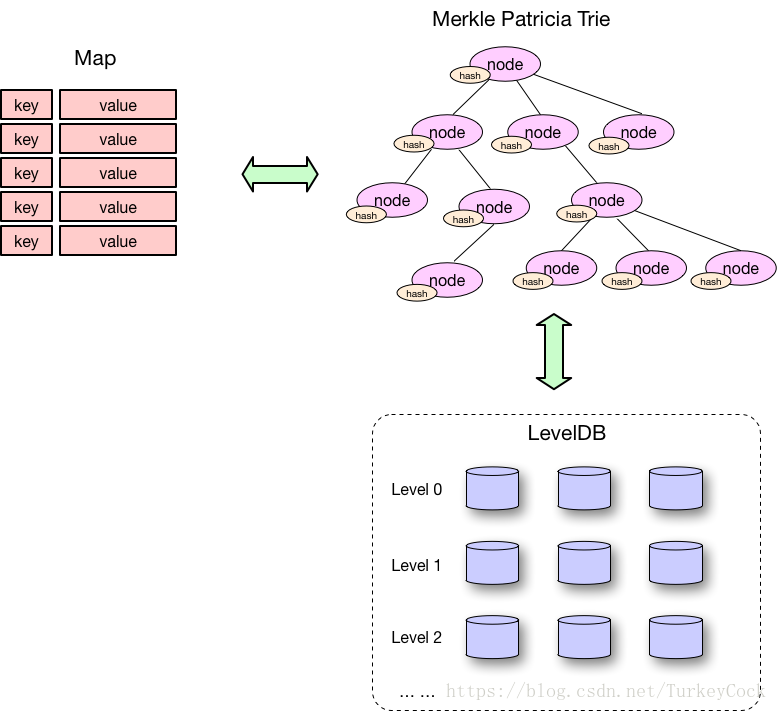
- 第一級快取以map的形式儲存stateObject
- 第二級快取以MPT的形式儲存
- 第三級就是LevelDB上的持久化儲存
當上一級快取中沒有所需的資料時,會從下一級快取或者資料庫中進行載入。
我們可以看一下StateDB具體實現的UML圖:
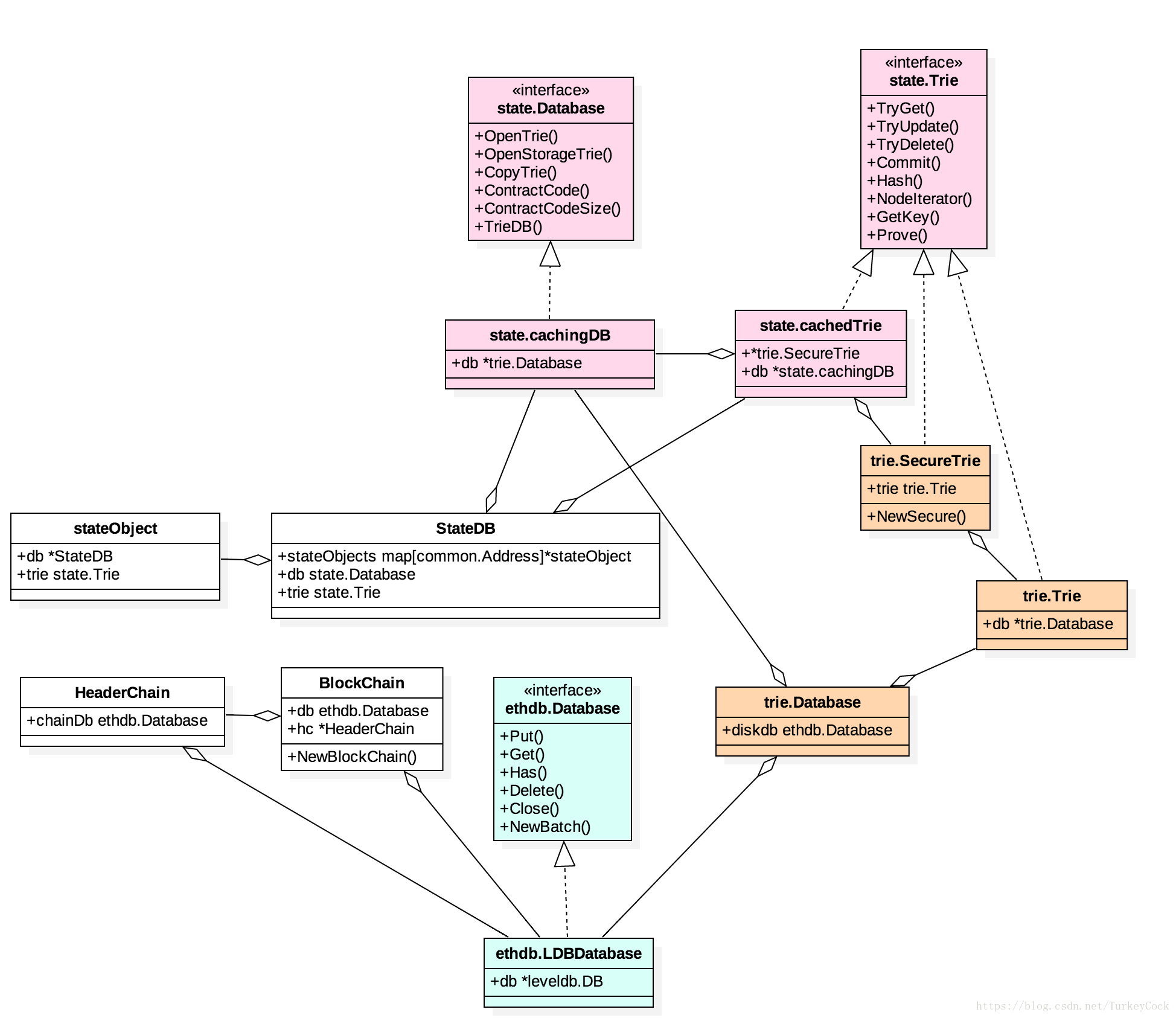
可以看到,一共封裝了3個包:state,trie,ethdb。如果按介面型別來分,主要分為Trie和Database兩種介面。Trie介面主要用於操作記憶體中的MPT,而Database介面主要用於操作LevelDB,做持久化儲存。StateDB中同時包含了這兩種介面。
檢視StateDB和stateObject的定義可以發現,這兩種型別內部各有一個Trie,那麼這兩個Trie裡儲存的什麼內容呢?請看下圖:
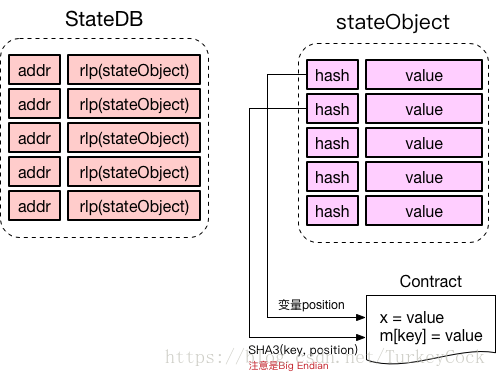
StateDB裡的Trie以賬戶地址為key,儲存經過RLP編碼後的stateObject。
stateObject裡的Trie也被稱為storage trie,儲存的是智慧合約執行後修改的變數值,細節可以參見之前的一篇文章:以太坊stateObject中Storage儲存內容的探究
這兩個Trie是怎麼關聯起來的呢?實際上stateObject內部有一個Account型別的欄位,我們看一下它的型別定義:
type Account struct {
Nonce uint64
Balance *big.Int
Root common.Hash // merkle root of the storage trie
CodeHash []byte
}
看到了吧,Account型別內部有一個Root欄位,記錄的正是對應的storage trie的merkle root。
3. Transactions的儲存
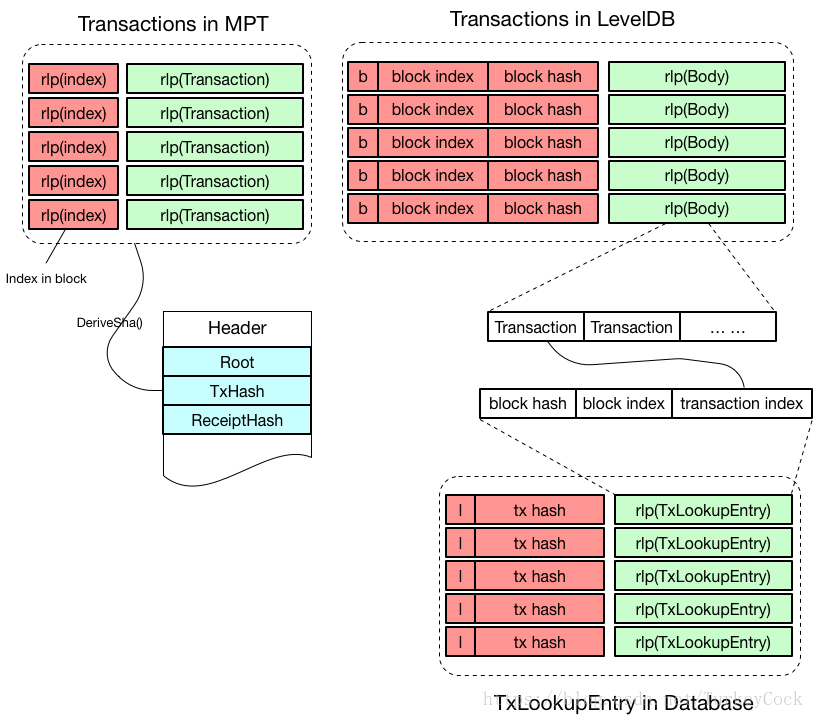
從圖中可以看出,MPT中是以交易在區塊中的索引的RLP編碼作為key,儲存交易資料的RLP編碼。
事實上交易在LeveDB中並不是單獨儲存的,而是儲存在區塊的Body中。在往LeveDB中儲存不同型別的鍵值對時,會在關鍵字中新增不同的字首予以區分,這些字首的定義在core/rawdb/schema.go中:
// Data item prefixes (use single byte to avoid mixing data types, avoid `i`, used for indexes).
headerPrefix = []byte("h") // headerPrefix + num (uint64 big endian) + hash -> header
headerTDSuffix = []byte("t") // headerPrefix + num (uint64 big endian) + hash + headerTDSuffix -> td
headerHashSuffix = []byte("n") // headerPrefix + num (uint64 big endian) + headerHashSuffix -> hash
headerNumberPrefix = []byte("H") // headerNumberPrefix + hash -> num (uint64 big endian)
blockBodyPrefix = []byte("b") // blockBodyPrefix + num (uint64 big endian) + hash -> block body
blockReceiptsPrefix = []byte("r") // blockReceiptsPrefix + num (uint64 big endian) + hash -> block receipts
txLookupPrefix = []byte("l") // txLookupPrefix + hash -> transaction/receipt lookup metadata
bloomBitsPrefix = []byte("B") // bloomBitsPrefix + bit (uint16 big endian) + section (uint64 big endian) + hash -> bloom bits
preimagePrefix = []byte("secure-key-") // preimagePrefix + hash -> preimage
configPrefix = []byte("ethereum-config-") // config prefix for the db
因此,以b + block index + block hash作為關鍵字就可以唯一確定某個區塊的Body所在的位置。
另外,為了能夠快速查詢某筆交易的資料,在資料庫中還儲存了每筆交易的索引資訊,稱為TxLookupEntry。TxLookupEntry中包含了block index和block hash用於定位區塊Body,同時還包含了該筆交易在區塊Body中的索引位置。
4. Receipts的儲存
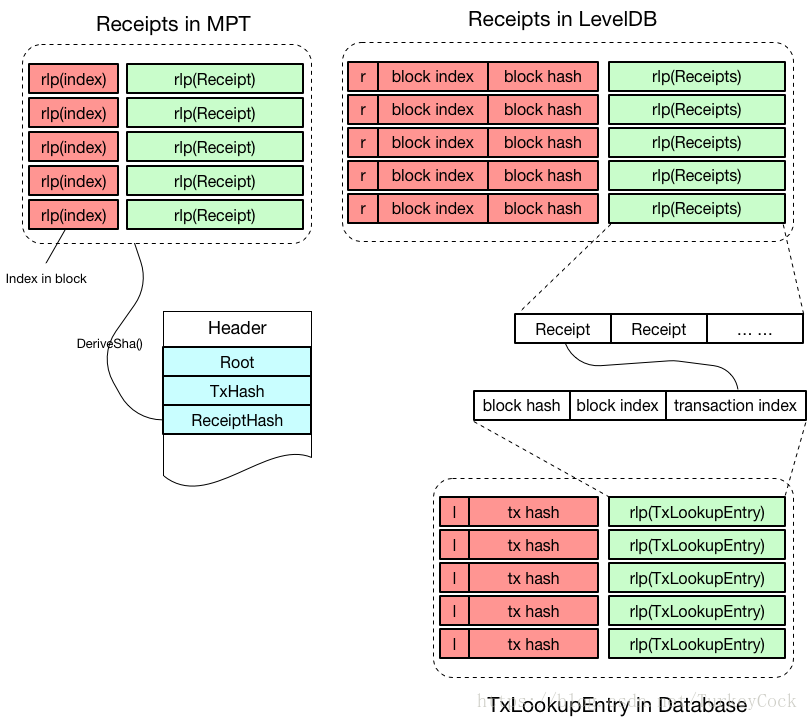
交易回執的儲存和交易類似,區別是交易回執是單獨儲存到LevelDB中的,以r為字首。
另外,由於交易回執和交易是一一對應的,因此也可以通過TxLookupEntry快速定位交易回執所在的位置,加速交易回執的查詢。