
BOW 原理及程式碼解析
引言
最初的Bag of words,也叫做“詞袋”,在資訊檢索中,Bag of words model假定對於一個文字,忽略其詞序和語法,句法,將其僅僅看做是一個詞集合,或者說是詞的一個組合,文字中每個詞的出現都是獨立的,不依賴於其他詞
是否出現,或者說當這篇文章的作者在任意一個位置選擇一個詞彙都不受前面句子的影響而獨立選擇的。
Bag-of-words模型是資訊檢索領域常用的文件表示方法。在資訊檢索中,BOW模型假定對於一個文件,忽略它的單詞順序和語法、句法等要素,將其僅僅看作是若干個詞彙的集合,文件中每個單詞的出現都是獨立的,不依賴於其它單詞是否出現。也就是說,文件中任意一個位置出現的任何單詞,都不受該文件語意影響而獨立選擇的。例如有如下兩個文件:
1:Bob likes to play basketball, Jim likes too.
2:Bob also likes to play football games.
基於這兩個文字文件,構造一個詞典:
Dictionary = {1:”Bob”, 2. “like”, 3. “to”, 4. “play”, 5. “basketball”, 6. “also”, 7. “football”, 8. “games”, 9. “Jim”, 10. “too”}。
這個詞典一共包含10個不同的單詞,利用詞典的索引號,上面兩個文件每一個都可以用一個10維向量表示(用整數數字0~n(n為正整數)表示某個單詞在文件中出現的次數)
1:[1, 2, 1, 1, 1, 0, 0, 0, 1, 1]
2:[1, 1, 1, 1 ,0, 1, 1, 1, 0, 0]
向量中每個元素表示詞典中相關元素在文件中出現的次數(下文中,將用單詞的直方圖表示)。不過,在構造文件向量的過程中可以看到,我們並沒有表達單詞在原來句子中出現的次序(這是本Bag-of-words模型的缺點之一,不過瑕不掩瑜甚至在此處無關緊要)。
一、原理
考慮將Bag-of-words模型應用於影象表示。為了表示一幅影象,我們可以將影象看作文件,即若干個“視覺詞彙”的集合,同樣的,視覺詞彙相互之間沒有順序。
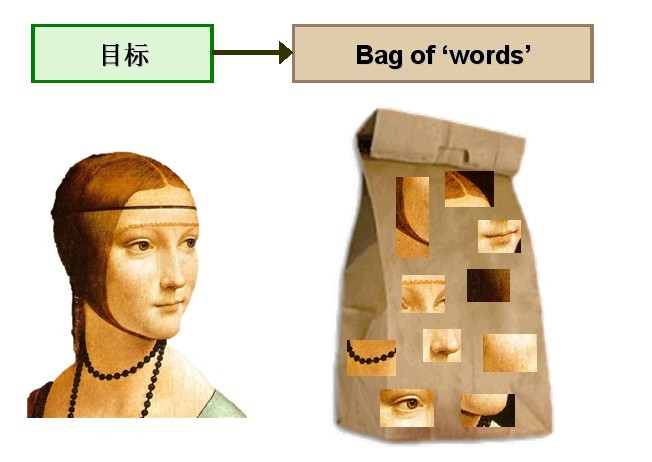
圖1 將Bag-of-words模型應用於影象表示
由於影象中的詞彙不像文字文件中的那樣是現成的,我們需要首先從影象中提取出相互獨立的視覺詞彙,這通常需要經過三個步驟:
(1)特徵檢測
(2)特徵表示
(3)單詞本的生成,

圖2 從影象中提取出相互獨立的視覺詞彙
通過觀察會發現,同一類目標的不同例項之間雖然存在差異,但我們仍然可以找到它們之間的一些共同的地方,比如說人臉,雖然說不同人的臉差別比較大,但眼睛,嘴,鼻子等一些比較細小的部位,卻觀察不到太大差別,我們可以把這些不同例項之間共同的部位提取出來,作為識別這一類目標的視覺詞彙。
而SIFT演算法是提取影象中區域性不變特徵的應用最廣泛的演算法,因此我們可以用SIFT演算法從影象中提取不變特徵點,作為視覺詞彙,並構造單詞表,用單詞表中的單詞表示一幅影象。
接下來,我們通過上述影象展示如何通過Bag-of-words模型,將影象表示成數值向量。現在有三個目標類,分別是人臉、自行車和吉他。
第一步:利用SIFT演算法,從每類影象中提取視覺詞彙,將所有的視覺詞彙集合在一起,如下圖3所示:

圖3 從每類影象中提取視覺詞彙
第二步:利用K-Means演算法構造單詞表。K-Means演算法是一種基於樣本間相似性度量的間接聚類方法,此演算法以K為引數,把N個物件分為K個簇,以使簇內具有較高的相似度,而簇間相似度較低。SIFT提取的視覺詞彙向量之間根據距離的遠近,可以利用K-Means演算法將詞義相近的詞彙合併,作為單詞表中的基礎詞彙,假定我們將K設為4,那麼單詞表的構造過程如下圖4所示:

圖4 利用K-Means演算法構造單詞表
第三步:利用單詞表的中詞彙表示影象。利用SIFT演算法,可以從每幅影象中提取很多個特徵點,這些特徵點都可以用單詞表中的單詞近似代替,通過統計單詞表中每個單詞在影象中出現的次數,可以將影象表示成為一個K=4維數值向量。
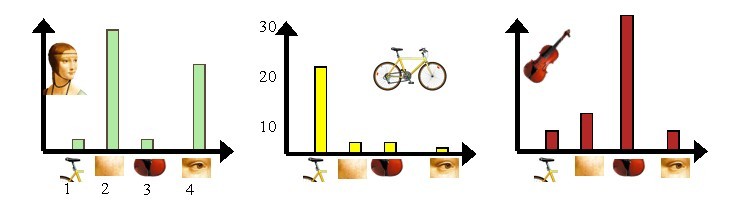
圖5 每幅影象的直方圖表示
上圖5中,我們從人臉、自行車和吉他三個目標類影象中提取出的不同視覺詞彙,而構造的詞彙表中,會把詞義相近的視覺詞彙合併為同一類,經過合併,詞彙表中只包含了四個視覺單詞,分別按索引值標記為1,2,3,4。通過觀察可以看到,它們分別屬於自行車、人臉、吉他、人臉類。統計這些詞彙在不同目標類中出現的次數可以得到每幅影象的直方圖表示(我們假定存在誤差,實際情況亦不外如此):
人臉: [3,30,3,20]
自行車:[20,3,3,2]
吉他: [8,12,32,7]
其實這個過程非常簡單,就是針對人臉、自行車和吉他這三個文件,抽取出相似的部分(或者詞義相近的視覺詞彙合併為同一類),構造一個詞典,詞典中包含4個視覺單詞,即Dictionary = {1:”自行車”, 2. “人臉”, 3. “吉他”, 4. “人臉類”},最終人臉、自行車和吉他這三個文件皆可以用一個4維向量表示,最後根據三個文件相應部分出現的次數畫成了上面對應的直方圖。
需要說明的是,以上過程只是針對三個目標類非常簡單的一個示例,實際應用中,為了達到較好的效果,單詞表中的詞彙數量K往往非常龐大,並且目標類數目越多,對應的K值也越大,一般情況下,K的取值在幾百到上千,在這裡取K=4僅僅是為了方便說明。
下面,我們再來總結一下如何利用Bag-of-words模型將一幅影象表示成為數值向量:
- 第一步:利用SIFT演算法從不同類別的影象中提取視覺詞彙向量,這些向量代表的是影象中區域性不變的特徵點;
- 第二步:將所有特徵點向量集合到一塊,利用K-Means演算法合併詞義相近的視覺詞彙,構造一個包含K個詞彙的單詞表;
- 第三步:統計單詞表中每個單詞在影象中出現的次數,從而將影象表示成為一個K維數值向量。
接下來就要進行構建Bag of words模型了,假設Dictionary詞典的Size為100,即有100個詞。那麼咱們可以用K-means演算法對所有的patch進行聚類,k=100,我們知道,等k-means收斂時,我們也得到了每一個cluster最後的質心,那麼這100個質心(維數128)就是詞典裡德100個詞了,詞典構建完畢。
詞典構建完了怎麼用呢?是這樣的,先初始化一個100個bin的初始值為0的直方圖h。每一幅影象不是有很多patch麼?我們就再次計算這些patch和和每一個質心的距離,看看每一個patch離哪一個質心最近,那麼直方圖h中相對應的bin就加1,然後計算完這幅影象所有的patches之後,就得到了一個bin=100的直方圖,然後進行歸一化,用這個100維德向量來表示這幅影象。對所有影象計算完成之後,就可以進行分類聚類訓練預測之類的了。
影象的特徵用到了Dense Sift,通過Bag of Words詞袋模型進行描述,當然一般來說是用訓練集的來構建詞典,因為我們還沒有測試集呢。雖然測試集是你拿來測試的,但是實際應用中誰知道測試的圖片是啥,所以構建BoW詞典我這裡也只用訓練集。
用BoW描述完影象之後,指的是將訓練集以及測試集的影象都用BoW模型描述了,就可以用SVM訓練分類模型進行分類了。
在這裡除了用SVM的RBF核,還自己定義了一種核: histogram intersection kernel,直方圖正交核。因為很多論文說這個核好,並且實驗結果很顯然。能從理論上證明一下麼?通過自定義核也可以瞭解怎麼使用自定義核來用SVM進行分類。
影響效率的一個方面是構建詞典時的K-means聚類,我在用的時候遇到了兩個問題:
1、記憶體溢位。這是由於一般的K-means函式的輸入是待聚類的完整的矩陣,在這裡就是所有patches的特徵向量f合成的一個大矩陣,由於這個矩陣太大,記憶體不頂了。我記憶體為4G。
2、效率低。因為需要計算每一個patch和每一個質心的尤拉距離,還有比較大小,那麼要是迴圈下來這個效率是很低的。
為了解決這個問題,我採用一下策略,不使用整一個數據矩陣X作為輸入的k-means,而是自己寫迴圈,每次處理一幅影象的所有patches,對於效率的問題,因為matlab強大的矩陣處理能力,可以有效避免耗時費力的自己編寫的迴圈迭代。
三、程式碼
Demo中的影象是我自己研究中用到的一些Action的影象,我都採集的簡單的一共6類,每一類60幅,40訓練20測試。請注意影象的版權問題,自己研究即可,不能商用。分類器用的是libsvm,最好自己mex重新編譯一下。
如果libsvm版本不合適或者沒有編譯成適合你的平臺的,會報錯,例如:
Classification using BOW rbf_svm
??? Error using ==> svmtrain at 172
Group must be a vector.
下面是預設的demo結果:
Classification using BOW rbf_svm
Accuracy = 75.8333% (91/120) (classification)Classification using histogram intersection kernel svm
Accuracy = 82.5% (99/120) (classification)Classification using Pyramid BOW rbf_svm
Accuracy = 82.5% (99/120) (classification)Classification using Pyramid BOW histogram intersection kernel svm
Accuracy = 90% (108/120) (classification)
當然結果這個樣子是因為我已經把6類影象提前弄成一樣大了,而且每一類都截取了最關鍵的子圖,不太符合實際,但是為了demo方便,當然影象大小可以是任意的。
下圖就是最好結果的混淆矩陣,最好結果就是Pyramid BoW+hik-SVM:

圖6 分類混淆矩陣
這是在另一個數據集上的結果(7類分類問題):
Classification using BOW rbf_svm
Accuracy = 34.5714% (242/700) (classification)Classification using histogram intersection kernel svm
Accuracy = 36% (252/700) (classification)Classification using Pyramid BOW rbf_svm
Accuracy = 43.7143% (306/700) (classification)Classification using Pyramid BOW histogram intersection kernel svm
Accuracy = 55.8571% (391/700) (classification)