
大資料教程(8.2)wordcount程式原理及程式碼實現/執行
阿新 • • 發佈:2018-11-25
上一篇部落格分享了mapreduce的程式設計思想,本節博主將帶小夥伴們瞭解wordcount程式的原理和程式碼實現/執行細節。通過本節可以對mapreduce程式有一個大概的認識,其實hadoop中的map、reduce程式只是其中的兩個元件,其餘的元件(如input/output)也是可以重寫的,預設情況下是使用預設元件。
一、wordcount統計程式實現:
WordcountMapper (map task業務實現)
package com.empire.hadoop.mr.wcdemo; import java.io.IOException; import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.LongWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Mapper; /** * KEYIN: 預設情況下,是mr框架所讀到的一行文字的起始偏移量,Long, * 但是在hadoop中有自己的更精簡的序列化介面,所以不直接用Long,而用LongWritable * VALUEIN:預設情況下,是mr框架所讀到的一行文字的內容,String,同上,用Text * KEYOUT:是使用者自定義邏輯處理完成之後輸出資料中的key,在此處是單詞,String,同上,用Text * VALUEOUT:是使用者自定義邏輯處理完成之後輸出資料中的value,在此處是單詞次數,Integer,同上,用IntWritable * * @author */ public class WordcountMapper extends Mapper<LongWritable, Text, Text, IntWritable> { /** * map階段的業務邏輯就寫在自定義的map()方法中 maptask會對每一行輸入資料呼叫一次我們自定義的map()方法 */ @Override protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException { //將maptask傳給我們的文字內容先轉換成String String line = value.toString(); //根據空格將這一行切分成單詞 String[] words = line.split(" "); //將單詞輸出為<單詞,1> for (String word : words) { //將單詞作為key,將次數1作為value,以便於後續的資料分發,可以根據單詞分發,以便於相同單詞會到相同的reduce task context.write(new Text(word), new IntWritable(1)); } } }
WordcountReducer(reduce業務程式碼實現)
package com.empire.hadoop.mr.wcdemo; import java.io.IOException; import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Reducer; /** * KEYIN, VALUEIN 對應 mapper輸出的KEYOUT,VALUEOUT型別對應 KEYOUT, VALUEOUT * 是自定義reduce邏輯處理結果的輸出資料型別 KEYOUT是單詞 VLAUEOUT是總次數 * * @author */ public class WordcountReducer extends Reducer<Text, IntWritable, Text, IntWritable> { /** * <angelababy,1><angelababy,1><angelababy,1><angelababy,1><angelababy,1> * <hello,1><hello,1><hello,1><hello,1><hello,1><hello,1> * <banana,1><banana,1><banana,1><banana,1><banana,1><banana,1> * 入參key,是一組相同單詞kv對的key */ @Override protected void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException { int count = 0; /* * Iterator<IntWritable> iterator = values.iterator(); * while(iterator.hasNext()){ count += iterator.next().get(); } */ for (IntWritable value : values) { count += value.get(); } context.write(key, new IntWritable(count)); } }
WordcountDriver (提交yarn的程式)
package com.empire.hadoop.mr.wcdemo;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
/**
* 相當於一個yarn叢集的客戶端 需要在此封裝我們的mr程式的相關執行引數,指定jar包 最後提交給yarn
*
* @author
*/
public class WordcountDriver {
public static void main(String[] args) throws Exception {
if (args == null || args.length == 0) {
args = new String[2];
args[0] = "hdfs://master:9000/wordcount/input/wordcount.txt";
args[1] = "hdfs://master:9000/wordcount/output8";
}
Configuration conf = new Configuration();
//設定的沒有用! ??????
// conf.set("HADOOP_USER_NAME", "hadoop");
// conf.set("dfs.permissions.enabled", "false");
/*
* conf.set("mapreduce.framework.name", "yarn");
* conf.set("yarn.resoucemanager.hostname", "mini1");
*/
Job job = Job.getInstance(conf);
/* job.setJar("/home/hadoop/wc.jar"); */
//指定本程式的jar包所在的本地路徑
job.setJarByClass(WordcountDriver.class);
//指定本業務job要使用的mapper/Reducer業務類
job.setMapperClass(WordcountMapper.class);
job.setReducerClass(WordcountReducer.class);
//指定mapper輸出資料的kv型別
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class);
//指定最終輸出的資料的kv型別
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
//指定job的輸入原始檔案所在目錄
FileInputFormat.setInputPaths(job, new Path(args[0]));
//指定job的輸出結果所在目錄
FileOutputFormat.setOutputPath(job, new Path(args[1]));
//將job中配置的相關引數,以及job所用的java類所在的jar包,提交給yarn去執行
/* job.submit(); */
boolean res = job.waitForCompletion(true);
//linux shell指令碼中,上一條命令返回0表示成功,其它表示失敗
System.exit(res ? 0 : 1);
}
}
二、執行mapreduce
(1)jar打包
(2)上傳到hadoop叢集上,並執行
#上傳jar
Alt+p
lcd d:/
put wordcount_aaron.jar
#準備hadoop處理的資料檔案
cd /home/hadoop/apps/hadoop-2.9.1
hadoop fs -mkdir -p /wordcount/input
hadoop fs -put LICENSE.txt NOTICE.txt /wordcount/input
#執行wordcount程式
hadoop jar wordcount_aaron.jar com.empire.hadoop.mr.wcdemo.WordcountDriver /wordcount/input /wordcount/outputs執行效果圖:
[[email protected] ~]$ hadoop jar wordcount_aaron.jar com.empire.hadoop.mr.wcdemo.WordcountDriver /wordcount/input /wordcount/output
18/11/19 22:48:54 INFO client.RMProxy: Connecting to ResourceManager at centos-aaron-h1/192.168.29.144:8032
18/11/19 22:48:55 WARN mapreduce.JobResourceUploader: Hadoop command-line option parsing not performed. Implement the Tool interface and execute your application with ToolRunner to remedy this.
18/11/19 22:48:55 INFO input.FileInputFormat: Total input files to process : 2
18/11/19 22:48:55 WARN hdfs.DataStreamer: Caught exception
java.lang.InterruptedException
at java.lang.Object.wait(Native Method)
at java.lang.Thread.join(Thread.java:1280)
at java.lang.Thread.join(Thread.java:1354)
at org.apache.hadoop.hdfs.DataStreamer.closeResponder(DataStreamer.java:980)
at org.apache.hadoop.hdfs.DataStreamer.endBlock(DataStreamer.java:630)
at org.apache.hadoop.hdfs.DataStreamer.run(DataStreamer.java:807)
18/11/19 22:48:55 WARN hdfs.DataStreamer: Caught exception
java.lang.InterruptedException
at java.lang.Object.wait(Native Method)
at java.lang.Thread.join(Thread.java:1280)
at java.lang.Thread.join(Thread.java:1354)
at org.apache.hadoop.hdfs.DataStreamer.closeResponder(DataStreamer.java:980)
at org.apache.hadoop.hdfs.DataStreamer.endBlock(DataStreamer.java:630)
at org.apache.hadoop.hdfs.DataStreamer.run(DataStreamer.java:807)
18/11/19 22:48:55 INFO mapreduce.JobSubmitter: number of splits:2
18/11/19 22:48:55 INFO Configuration.deprecation: yarn.resourcemanager.system-metrics-publisher.enabled is deprecated. Instead, use yarn.system-metrics-publisher.enabled
18/11/19 22:48:55 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_1542637441480_0002
18/11/19 22:48:56 INFO impl.YarnClientImpl: Submitted application application_1542637441480_0002
18/11/19 22:48:56 INFO mapreduce.Job: The url to track the job: http://centos-aaron-h1:8088/proxy/application_1542637441480_0002/
18/11/19 22:48:56 INFO mapreduce.Job: Running job: job_1542637441480_0002
18/11/19 22:49:03 INFO mapreduce.Job: Job job_1542637441480_0002 running in uber mode : false
18/11/19 22:49:03 INFO mapreduce.Job: map 0% reduce 0%
18/11/19 22:49:09 INFO mapreduce.Job: map 100% reduce 0%
18/11/19 22:49:14 INFO mapreduce.Job: map 100% reduce 100%
18/11/19 22:49:15 INFO mapreduce.Job: Job job_1542637441480_0002 completed successfully
18/11/19 22:49:15 INFO mapreduce.Job: Counters: 49
File System Counters
FILE: Number of bytes read=241219
FILE: Number of bytes written=1074952
FILE: Number of read operations=0
FILE: Number of large read operations=0
FILE: Number of write operations=0
HDFS: Number of bytes read=122364
HDFS: Number of bytes written=35348
HDFS: Number of read operations=9
HDFS: Number of large read operations=0
HDFS: Number of write operations=2
Job Counters
Launched map tasks=2
Launched reduce tasks=1
Data-local map tasks=2
Total time spent by all maps in occupied slots (ms)=7588
Total time spent by all reduces in occupied slots (ms)=3742
Total time spent by all map tasks (ms)=7588
Total time spent by all reduce tasks (ms)=3742
Total vcore-milliseconds taken by all map tasks=7588
Total vcore-milliseconds taken by all reduce tasks=3742
Total megabyte-milliseconds taken by all map tasks=7770112
Total megabyte-milliseconds taken by all reduce tasks=3831808
Map-Reduce Framework
Map input records=2430
Map output records=19848
Map output bytes=201516
Map output materialized bytes=241225
Input split bytes=239
Combine input records=0
Combine output records=0
Reduce input groups=2794
Reduce shuffle bytes=241225
Reduce input records=19848
Reduce output records=2794
Spilled Records=39696
Shuffled Maps =2
Failed Shuffles=0
Merged Map outputs=2
GC time elapsed (ms)=332
CPU time spent (ms)=2830
Physical memory (bytes) snapshot=557314048
Virtual memory (bytes) snapshot=2538102784
Total committed heap usage (bytes)=259411968
Shuffle Errors
BAD_ID=0
CONNECTION=0
IO_ERROR=0
WRONG_LENGTH=0
WRONG_MAP=0
WRONG_REDUCE=0
File Input Format Counters
Bytes Read=122125
File Output Format Counters
Bytes Written=35348執行結果:
#檢視處理結果檔案
hadoop fs -ls /wordcount/output
hadoop fs -cat /wordcount/output/part-r-00000|more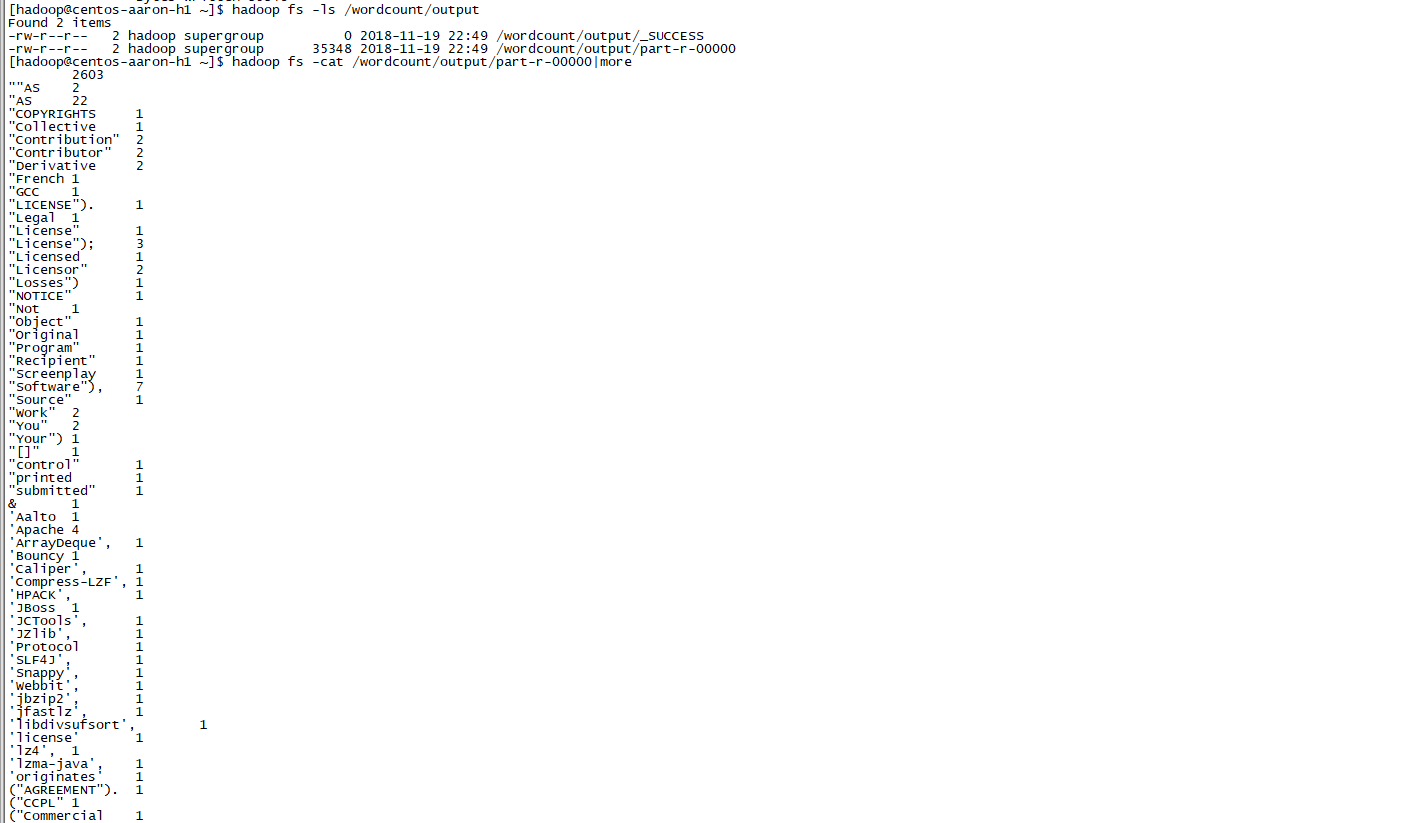
問題處理:
18/11/19 22:48:55 WARN hdfs.DataStreamer: Caught exception
java.lang.InterruptedException
at java.lang.Object.wait(Native Method)
at java.lang.Thread.join(Thread.java:1280)
at java.lang.Thread.join(Thread.java:1354)
at org.apache.hadoop.hdfs.DataStreamer.closeResponder(DataStreamer.java:980)
at org.apache.hadoop.hdfs.DataStreamer.endBlock(DataStreamer.java:630)
at org.apache.hadoop.hdfs.DataStreamer.run(DataStreamer.java:807)發生上面錯誤是因為我們新建hdfs目錄時未按照官方文件新建造成,問題不大;博主這邊沒影響正常使用;
解決方法:
#建立目錄
hdfs dfs -mkdir -p /user/hadoop
hdfs dfs -put NOTICE.txt LICENSE.txt /user/hadoop總結:使用以下兩種方式來執行並沒有區別,hadoop jar,底層就是呼叫的java -cp命令來執行。
hadoop jar wordcount_aaron.jar com.empire.hadoop.mr.wcdemo.WordcountDriver /wordcount/input /wordcount/outputs
java -cp .:/home/hadoop/wordcount_aaron.jar:/home/hadoop/apps/hadoop-2.9.1....jar com.empire.hadoop.mr.wcdemo.WordcountDriver /user/hadoop/ /wordcount/outputs最後寄語,以上是博主本次文章的全部內容,如果大家覺得博主的文章還不錯,請點贊;如果您對博主其它伺服器大資料技術或者博主本人感興趣,請關注博主部落格,並且歡迎隨時跟博主溝通交流。