
Top K演算法問題的實現
前奏
在上一篇文章,程式設計師面試題狂想曲:第三章、尋找最小的k個數中,後來為了論證類似快速排序中partition的方法在最壞情況下,能在O(N)的時間複雜度內找到最小的k個數,而前前後後updated了10餘次。所謂功夫不負苦心人,終於得到了一個想要的結果。
簡單總結如下(詳情,請參考原文第三章):
1、RANDOMIZED-SELECT,以序列中隨機選取一個元素作為主元,可達到線性期望時間O(N)的複雜度。
2、SELECT,快速選擇演算法,以序列中“五分化中項的中項”,或“中位數的中位數”作為主元(樞紐元),則不容置疑的可保證在最壞情況下亦為O(N)的複雜度。
本章,咱們來闡述尋找最小的k個數的反面,即尋找最大的k個數,但此刻可能就有讀者質疑了,尋找最大的k個數和尋找最小的k個數,原理不是一樣的麼?
是的,的確是一樣,但這個尋找最大的k個數的問題的實用範圍更廣,因為它牽扯到了一個Top K演算法問題,以及有關搜尋引擎,海量資料處理等廣泛的問題,所以本文特意對這個Top K演算法問題,進行闡述以及實現(側重實現,因為那樣看起來,會更令人激動人心),算是第三章的續。ok,有任何問題,歡迎隨時不吝指正。謝謝。
說明
關於尋找最小K個數能做到最壞情況下為O(N)的演算法及證明,請參考原第三章,尋找最小的k個數,本文的程式碼不保證O(N)的平均時間複雜度,只是根據第三章有辦法可以做到而已(如上面總結的,2、SELECT,快速選擇演算法,以序列中“五分化中項的中項”,或“中位數的中位數”作為主元或樞紐元
第一節、尋找最小的第k個數
在進入尋找最大的k個數的主題之前,先補充下關於尋找最k小的數的三種簡單實現。由於堆的完整實現,第三章:第五節,堆結構實現,處理海量資料中已經給出,下面主要給出類似快速排序中partition過程的程式碼實現:
尋找最小的k個數,實現一(下段程式碼經本文評論下多位讀者指出有問題:當a [ i ]=a [ j
]=pivot時,則會產生一個無限迴圈,在Mark Allen Weiss的資料結構與演算法分析C++描述中文版的P209-P210有描述,讀者可參看之。特此說明,因本文程式碼存在問題的地方還有幾處,故請待後續統一修正.2012.08.21
- //[email protected] mark allen weiss && July && yansha
- //July,yansha、updated,2011.05.08.
- //本程式,後經飛羽找出錯誤,已經修正。
- //隨機選取樞紐元,尋找最小的第k個數
- #include <iostream>
- #include <stdlib.h>
- usingnamespace std;
- int my_rand(int low, int high)
- {
- int size = high - low + 1;
- return low + rand() % size;
- }
- //q_select places the kth smallest element in a[k]
- int q_select(int a[], int k, int left, int right)
- {
- if(k > right || k < left)
- {
- // cout<<"---------"<<endl; //為了處理當k大於陣列中元素個數的異常情況
- returnfalse;
- }
- //真正的三數中值作為樞紐元方法,關鍵程式碼就是下述六行
- int midIndex = (left + right) / 2;
- if(a[left] < a[midIndex])
- swap(a[left], a[midIndex]);
- if(a[right] < a[midIndex])
- swap(a[right], a[midIndex]);
- if(a[right] < a[left])
- swap(a[right], a[left]);
- swap(a[left], a[right]);
- int pivot = a[right]; //之前是int pivot = right,特此,修正。
- // 申請兩個移動指標並初始化
- int i = left;
- int j = right-1;
- // 根據樞紐元素的值對陣列進行一次劃分
- for (;;)
- {
- while(a[i] < pivot)
- i++;
- while(a[j] > pivot)
- j--;
- //a[i] >= pivot, a[j] <= pivot
- if (i < j)
- swap(a[i], a[j]); //a[i] <= a[j]
- else
- break;
- }
- swap(a[i], a[right]);
- /* 對三種情況進行處理
- 1、如果i=k,即返回的主元即為我們要找的第k小的元素,那麼直接返回主元a[i]即可;
- 2、如果i>k,那麼接下來要到低區間A[0....m-1]中尋找,丟掉高區間;
- 3、如果i<k,那麼接下來要到高區間A[m+1...n-1]中尋找,丟掉低區間。
- */
- if (i == k)
- returntrue;
- elseif (i > k)
- return q_select(a, k, left, i-1);
- elsereturn q_select(a, k, i+1, right);
- }
- int main()
- {
- int i;
- int a[] = {7, 8, 9, 54, 6, 4, 11, 1, 2, 33};
- q_select(a, 4, 0, sizeof(a) / sizeof(int) - 1);
- return 0;
- }
尋找最小的第k個數,實現二:
- //[email protected] July
- //yansha、updated,2011.05.08。
- // 陣列中尋找第k小元素,實現二
- #include <iostream>
- usingnamespace std;
- constint numOfArray = 10;
- // 這裡並非真正隨機
- int my_rand(int low, int high)
- {
- int size = high - low + 1;
- return low + rand() % size;
- }
- // 以最末元素作為主元對陣列進行一次劃分
- int partition(int array[], int left, int right)
- {
- int pos = right;
- for(int index = right - 1; index >= left; index--)
- {
- if(array[index] > array[right])
- swap(array[--pos], array[index]);
- }
- swap(array[pos], array[right]);
- return pos;
- }
- // 隨機快排的partition過程
- int random_partition(int array[], int left, int right)
- {
- // 隨機從範圍left到right中取一個值作為主元
- int index = my_rand(left, right);
- swap(array[right], array[index]);
- // 對陣列進行劃分,並返回主元在陣列中的位置
- return partition(array, left, right);
- }
- // 以線性時間返回陣列array[left...right]中第k小的元素
- int random_select(int array[], int left, int right, int k)
- {
- // 處理異常情況
- if (k < 1 || k > (right - left + 1))
- return -1;
- // 主元在陣列中的位置
- int pos = random_partition(array, left, right);
- /* 對三種情況進行處理:(m = i - left + 1)
- 1、如果m=k,即返回的主元即為我們要找的第k小的元素,那麼直接返回主元array[i]即可;
- 2、如果m>k,那麼接下來要到低區間array[left....pos-1]中尋找,丟掉高區間;
- 3、如果m<k,那麼接下來要到高區間array[pos+1...right]中尋找,丟掉低區間。
- */
- int m = pos - left + 1;
- if(m == k)
- return array[pos];
- elseif (m > k)
- return random_select(array, left, pos - 1, k);
- else
- return random_select(array, pos + 1, right, k - m);
- }
- int main()
- {
- int array[numOfArray] = {7, 8, 9, 54, 6, 4, 2, 1, 12, 33};
- cout << random_select(array, 0, numOfArray - 1, 4) << endl;
- return 0;
- }
尋找最小的第k個數,實現三:
- //求取無序陣列中第K個數,本程式樞紐元的選取有問題,不作推薦。
- //[email protected] 飛羽
- //July、yansha,updated,2011.05.18。
- #include <iostream>
- #include <time.h>
- usingnamespace std;
- int kth_elem(int a[], int low, int high, int k)
- {
- int pivot = a[low];
- //這個程式之所以做不到O(N)的最最重要的原因,就在於這個樞紐元的選取。
- //而這個程式直接選取陣列中第一個元素作為樞紐元,是做不到平均時間複雜度為 O(N)的。
- //要 做到,就必須 把上面選取樞紐元的 程式碼改掉,要麼是隨機選擇陣列中某一元素作為樞紐元,能達到線性期望的時間
- //要麼是選取陣列中中位數的中位數作為樞紐元,保證最壞情況下,依然為線性O(N)的平均時間複雜度。
- int low_temp = low;
- int high_temp = high;
- while(low < high)
- {
- while(low < high && a[high] >= pivot)
- --high;
- a[low] = a[high];
- while(low < high && a[low] < pivot)
- ++low;
- a[high] = a[low];
- }
- a[low] = pivot;
- //以下就是主要思想中所述的內容
- if(low == k - 1)
- return a[low];
- elseif(low > k - 1)
- return kth_elem(a, low_temp, low - 1, k);
- else
- return kth_elem(a, low + 1, high_temp, k);
- }
- int main() //以後儘量不再用隨機產生的陣列進行測試,沒多大必要。
- {
- for (int num = 5000; num < 50000001; num *= 10)
- {
- int *array = newint[num];
- int j = num / 10;
- int acc = 0;
- for (int k = 1; k <= num; k += j)
- {
- // 隨機生成資料
- srand(unsigned(time(0)));
- for(int i = 0; i < num; i++)
- array[i] = rand() * RAND_MAX + rand();
- //”如果陣列本身就是利用隨機化產生的話,那麼選擇其中任何一個元素作為樞軸都可以看作等價於隨機選擇樞軸,
- //(雖然這不叫隨機選擇樞紐)”,這句話,是完全不成立的,是錯誤的。
- //“因為你總是選擇 隨機陣列中第一個元素 作為樞紐元,不是 隨機選擇樞紐元”
- //相當於把上面這句話中前面的 “隨機” 兩字去掉,就是:
- //因為 你總是選擇陣列中第一個元素作為樞紐元,不是 隨機選擇樞紐元。
- //所以,這個程式,始終做不到平均時間複雜度為O(N)。
- //隨機陣列和給定一個非有序而隨機手動輸入的陣列,是一個道理。稍後,還將就程式的執行結果繼續解釋這個問題。
- //July、updated,2011.05.18。
- // 計算一次查詢所需的時鐘週期數
- clock_t start = clock();
- int data = kth_elem(array, 0, num - 1, k);
- clock_t end = clock();
- acc += (end - start);
- }
- cout << "The average time of searching a date in the array size of " << num << " is " << acc / 10 << endl;
- }
- return 0;
- }
The average time of searching a date in the array size of 5000 is 0
The average time of searching a date in the array size of 50000 is 1
The average time of searching a date in the array size of 500000 is 12
The average time of searching a date in the array size of 5000000 is 114
The average time of searching a date in the array size of 50000000 is 1159
Press any key to continue
通過測試這個程式,我們竟發現這個程式的執行時間是線性的?
或許,你還沒有意識到這個問題,ok,聽我慢慢道來。
我們之前說,要保證這個演算法是線性的,就一定要在樞紐元的選取上下足功夫:
1、要麼是隨機選取樞紐元作為劃分元素
2、要麼是取中位數的中位數作為樞紐元劃分元素
現在,這程式直接選取了陣列中第一個元素作為樞紐元
竟然,也能做到線性O(N)的複雜度,這不是自相矛盾麼?
你覺得這個程式的執行時間是線性O(N),是巧合還是確定會是如此?哈哈,且看1、@well:根據上面的執行結果不能判斷線性,如果人家是O(n^1.1) 也有可能啊,而且部分資料始終是擬合,還是要數學證明才可靠。2、@July:同時,隨機陣列中選取一個元素作為樞紐元!=> 隨機陣列中隨機選取一個元素作為樞紐元(如果是隨機選取隨機陣列中的一個元素作為主元,那就不同了,跟隨機選取陣列中一個元素作為樞紐元一樣了)。3、@飛羽:正是因為陣列本身是隨機的,所以選擇第一個元素和隨機選擇其它的數是等價的(由等概率產生保證),這第3點,我與飛羽有分歧,至於誰對誰錯,待時間讓我考證。
關於上面第3點我和飛羽的分歧,在我們進一步討論之後,一致認定(不過,相信,你看到了上面程式更新的註釋之後,你應該有幾分領會了):
- 我們說輸入一個數組的元素,不按其順序輸入:如,1,2,3,4,5,6,7,而是這樣輸入:5,7,6,4,3,1,2,這就叫隨機輸入,而這種情況就相當於上述程式主函式中所產生的隨機陣列。然而選取隨機輸入的陣列或隨機陣列中第一個元素作為主元,我們不能稱之為說是隨機選取樞紐元。
- 因為,隨機數產生器產生的資料是隨機的,沒錯,但你要知道,你總是選取隨機陣列的第一個元素作為樞紐元,這不叫隨機選取樞紐元。
- 所以,上述程式的主函式中隨機產生的陣列對這個程式的演算法而言,沒有任何意義,就是幫忙產生了一個隨機陣列,幫助我們完成了測試,且方便我們測試大資料量而已,就這麼簡單。
- 且一般來說,我們看一個程式的 時間複雜度,是不考慮 其輸入情況的,即不考慮主函式,正如這個 kth number 的程式所見,你每次都是隨機選取陣列中第一個元素作為樞紐元,而並不是隨機選擇樞紐元,所以,做不到平均時間複雜度為O(N)。
所以:想要保證此快速選擇演算法為O(N)的複雜度,只有兩種途徑,那就是保證劃分的樞紐元元素的選取是:
1、隨機的(注,此樞紐元隨機不等同於陣列隨機)
2、五分化中項的中項,或中位數的中位數。所以,雖然咱們對於一切心知肚明,但上面程式的執行結果說明不了任何問題,這也從側面再次佐證了咱們第三章中觀點的正確無誤性。
updated:
非常感謝飛羽等人的工作,將上述三個版本綜合到了一起(待進一步測試):
- ///下面的程式碼對July部落格中的三個版本程式碼進行重新改寫。歡迎指出錯誤。
- ///先把它們貼在這裡,還要進行隨機化資料測試。待發...
- //modified by 飛羽 at 2011.5.11
- /////Top_K_test
- //修改了下命名規範,July、updated,2011.05.12。
- #include <iostream>
- #include <stdlib.h>
- usingnamespace std;
- inlineint my_rand(int low, int high)
- {
- int size = high - low + 1;
- return low + rand() % size;
- }
- int partition(int array[], int left, int right)
- {
- int pivot = array[right];
- int pos = left-1;
- for(int index = left; index < right; index++)
- {
- if(array[index] <= pivot)
- swap(array[++pos], array[index]);
- }
- swap(array[++pos], array[right]);
- return pos;//返回pivot所在位置
- }
- bool median_select(int array[], int left, int right, int k)
- {
- //第k小元素,實際上應該在陣列中下標為k-1
- if (k-1 > right || k-1 < left)
- returnfalse;
- //真正的三數中值作為樞紐元方法,關鍵程式碼就是下述六行
- int midIndex=(left+right)/2;
- if(array[left]<array[midIndex])
- swap(array[left],array[midIndex]);
- if(array[right]<array[midIndex])
- swap(array[right],array[midIndex]);
- if(array[right]<array[left])
- swap(array[right],array[left]);
- swap(array[left], array[right]);
- int pos = partition(array, left, right);
- if (pos == k-1)
- returntrue;
- elseif (pos > k-1)
- return median_select(array, left, pos-1, k);
- elsereturn median_select(array, pos+1, right, k);
- }
- bool rand_select(int array[], int left, int right, int k)
- {
- //第k小元素,實際上應該在陣列中下標為k-1
- if (k-1 > right || k-1 < left)
- returnfalse;
- //隨機從陣列中選取樞紐元元素
- int Index = my_rand(left, right);
- swap(array[Index], array[right]);
- int pos = partition(array, left, right);
- if (pos == k-1)
- returntrue;
- elseif (pos > k-1)
- return rand_select(array, left, pos-1, k);
- elsereturn rand_select(array, pos+1, right, k);
- }
- bool kth_select(int array[], int left, int right, int k)
- {
- //直接取最原始的劃分操作
- if (k-1 > right || k-1 < left)
- returnfalse;
- int pos = partition(array, left, right);
- if(pos == k-1)
- returntrue;
- elseif(pos > k-1)
- return kth_select(array, left, pos-1, k);
- elsereturn kth_select(array, pos+1, right, k);
- }
- int main()
- {
- int array1[] = {7, 8, 9, 54, 6, 4, 11, 1, 2, 33};
- int array2[] = {7, 8, 9, 54, 6, 4, 11, 1, 2, 33};
- int array3[] = {7, 8, 9, 54, 6, 4, 11, 1, 2, 33};
- int numOfArray = sizeof(array1) / sizeof(int);
- for(int i=0; i<numOfArray; i++)
- printf("%d/t",array1[i]);
- int K = 9;
- bool flag1 = median_select(array1, 0, numOfArray-1, K);
- bool flag2 = rand_select(array2, 0, numOfArray-1, K);
- bool flag3 = kth_select(array3, 0, numOfArray-1, K);
- if(!flag1)
- return 1;
- for(i=0; i<K; i++)
- printf("%d/t",array1[i]);
- printf("/n");
- if(!flag2)
- return 1;
- for(i=0; i<K; i++)
- printf("%d/t",array2[i]);
- printf("/n");
- if(!flag3)
- return 1;
- for(i=0; i<K; i++)
- printf("%d/t",array3[i]);
- printf("/n");
- return 0;
- }
說明:@飛羽:因為預先設定了K,經過分割演算法後,陣列肯定被劃分為array[0...k-1]和array[k...length-1],注意到經過Select_K_Version操作後,陣列是被不斷地分割的,使得比array[k-1]的元素小的全在左邊,題目要求的是最小的K個元素,當然也就是array[0...k-1],所以輸出的結果就是前k個最小的數:
7 8 9 54 6 4 11 1 2 33
4 1 2 6 7 8 9 11 33
7 6 4 1 2 8 9 11 33
7 8 9 6 4 11 1 2 33
Press any key to continue
第二節、尋找最大的k個數
把之前第三章的問題,改幾個字,即成為尋找最大的k個數的問題了,如下所述:
查詢最大的k個元素
題目描述:輸入n個整數,輸出其中最大的k個。
例如輸入1,2,3,4,5,6,7和8這8個數字,則最大的4個數字為8,7,6和5。
分析:由於尋找最大的k個數的問題與之前的尋找最小的k個數的問題,本質是一樣的,所以,這裡就簡單闡述下思路,ok,考驗你舉一反三能力的時間到了:
1、排序,快速排序。我們知道,快速排序平均所費時間為n*logn,從小到大排序這n個數,然後再遍歷序列中後k個元素輸出,即可,總的時間複雜度為O(n*logn+k)=O(n*logn)。
2、排序,選擇排序。用選擇或交換排序,即遍歷n個數,先把最先遍歷到得k個數存入大小為k的陣列之中,對這k個數,利用選擇或交換排序,找到k個數中的最小數kmin(kmin設為k個元素的陣列中最小元素),用時O(k)(你應該知道,插入或選擇排序查詢操作需要O(k)的時間),後再繼續遍歷後n-k個數,x與kmin比較:如果x>kmin,則x代替kmin,並再次重新找出k個元素的陣列中最大元素kmin‘(多謝jiyeyuran 提醒修正);如果x<kmin,則不更新陣列。這樣,每次更新或不更新陣列的所用的時間為O(k)或O(0),整趟下來,總的時間複雜度平均下來為:n*O(k)=O(n*k)。
3、維護k個元素的最小堆,原理與上述第2個方案一致,即用容量為k的最小堆儲存最先遍歷到的k個數,並假設它們即是最大的k個數,建堆費時O(k),並調整堆(費時O(logk))後,有k1>k2>...kmin(kmin設為小頂堆中最大元素)。繼續遍歷數列,每次遍歷一個元素x,與堆頂元素比較,若x>kmin,則更新堆(用時logk),否則不更新堆。這樣下來,總費時O(k*logk+(n-k)*logk)=O(n*logk)。此方法得益於在堆中,查詢等各項操作時間複雜度均為logk(不然,就如上述思路2所述:直接用陣列也可以找出最大的k個元素,用時O(n*k))。
4、按程式設計之美第141頁上解法二的所述,類似快速排序的劃分方法,N個數儲存在陣列S中,再從陣列中隨機選取一個數X,把陣列劃分為Sa和Sb倆部分,Sa>=X>=Sb,如果要查詢的k個元素小於Sa的元素個數,則返回Sa中較大的k個元素,否則返回Sa中所有的元素+Sb中最大的k-|Sa|個元素。不斷遞迴下去,把問題分解成更小的問題,平均時間複雜度為O(N)(程式設計之美所述的n*logk的複雜度有誤,應為O(N),特此訂正。其嚴格證明,請參考第三章:程式設計師面試題狂想曲:第三章、尋找最小的k個數、updated 10次)。
.........
其它的方法,在此不再重複了,同時,尋找最小的k個數藉助堆的實現,程式碼在上一篇文章第三章已有給出,更多,可參考第三章,只要把最大堆改成最小堆,即可。
第三節、Top K 演算法問題
3.1、搜尋引擎熱門查詢統計
題目描述:
搜尋引擎會通過日誌檔案把使用者每次檢索使用的所有檢索串都記錄下來,每個查詢串的長度為1-255位元組。
假設目前有一千萬個記錄(這些查詢串的重複度比較高,雖然總數是1千萬,但如果除去重複後,不超過3百萬個。一個查詢串的重複度越高,說明查詢它的使用者越多,也就是越熱門。),請你統計最熱門的10個查詢串,要求使用的記憶體不能超過1G。
分析:這個問題在之前的這篇文章十一、從頭到尾徹底解析Hash表演算法裡,已經有所解答。方法是:
第一步、先對這批海量資料預處理,在O(N)的時間內用Hash表完成統計(之前寫成了排序,特此訂正。July、2011.04.27);
第二步、藉助堆這個資料結構,找出Top K,時間複雜度為N‘logK。
即,藉助堆結構,我們可以在log量級的時間內查詢和調整/移動。因此,維護一個K(該題目中是10)大小的小根堆(K1>K2>....Kmin,Kmin設為堆頂元素),然後遍歷300萬的Query,分別和根元素Kmin進行對比比較(如上第2節思路3所述,若X>Kmin,則更新並調整堆,否則,不更新),我們最終的時間複雜度是:O(N) + N'*O(logK),(N為1000萬,N’為300萬)。ok,更多,詳情,請參考原文。
或者:採用trie樹,關鍵字域存該查詢串出現的次數,沒有出現為0。最後用10個元素的最小推來對出現頻率進行排序。
ok,本章裡,咱們來實現這個問題,為了降低實現上的難度,假設這些記錄全部是一些英文單詞,即使用者在搜尋框裡敲入一個英文單詞,然後查詢搜尋結果,最後,要你統計輸入單詞中頻率最大的前K個單詞。ok,複雜問題簡單化了之後,編寫程式碼實現也相對輕鬆多了,畫的簡單示意圖(繪製者,yansha),如下:
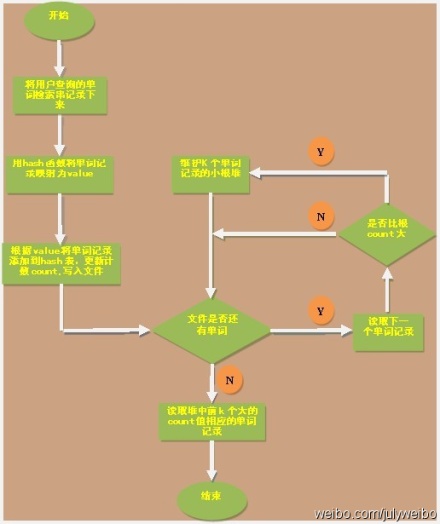
完整原始碼:
- //[email protected] &&July
- //July、updated,2011.05.08
- //題目描述:
- //搜尋引擎會通過日誌檔案把使用者每次檢索使用的所有檢索串都記錄下來,每個查詢串的
- //長度為1-255位元組。假設目前有一千萬個記錄(這些查詢串的重複度比較高,雖然總數是1千萬,但如果
- //除去重複後,不超過3百萬個。一個查詢串的重複度越高,說明查詢它的使用者越多,也就是越熱門),
- //請你統計最熱門的10個查詢串,要求使用的記憶體不能超過1G。
- #include <iostream>
- #include <string>
- #include <assert.h>
- usingnamespace std;
- #define HASHLEN 2807303
- #define WORDLEN 30
- // 結點指標
- typedefstruct node_no_space *ptr_no_space;
- typedefstruct node_has_space *ptr_has_space;
- ptr_no_space head[HASHLEN];
- struct node_no_space
- {
- char *word;
- int count;
- ptr_no_space next;
- };
- struct node_has_space
- {
- char word[WORDLEN];
- int count;
- ptr_has_space next;
- };
- // 最簡單hash函式
- int hash_function(charconst *p)
- {
- int value = 0;
- while (*p != '/0')
- {
- value = value * 31 + *p++;
- if (value > HASHLEN)
- value = value % HASHLEN;
- }
- return value;
- }
- // 新增單詞到hash表
- void append_word(charconst *str)
- {
- int index = hash_function(str);
- ptr_no_space p = head[index];
- while (p != NULL)
- {
- if (strcmp(str, p->word) == 0)
- {
- (p->count)++;
- return;
- }
- p = p->next;
- }
- // 新建一個結點
- ptr_no_space q = new node_no_space;
- q->count = 1;
- q->word = newchar [strlen(str)+1];
- strcpy(q->word, str);
- q->next = head[index];
- head[index] = q;
- }
- // 將單詞處理結果寫入檔案
- void write_to_file()
- {
- FILE *fp = fopen("result.txt", "w");
- assert(fp);
- int i = 0;
- while (i < HASHLEN)
- {
- for (ptr_no_space p = head[i]; p != NULL; p = p->next)
- fprintf(fp, "%s %d/n", p->word, p->count);
- i++;
- }
- fclose(fp);
- }
- // 從上往下篩選,保持小根堆
- void sift_down(node_has_space heap[], int i, int len)
- {
- int min_index = -1;
- int left = 2 * i;
- int right = 2 * i + 1;
- if (left <= len && heap[left].count < heap[i].count)
- min_index = left;
- else
- min_index = i;
- if (right <= len && heap[right].count < heap[min_index].count)
- min_index = right;
- if (min_index != i)
- {
- // 交換結點元素
- swap(heap[i].count, heap[min_index].count);
- char buffer[WORDLEN];
- strcpy(buffer, heap[i].word);
- strcpy(heap[i].word, heap[min_index].word);
- strcpy(heap[min_index].word, buffer);
- sift_down(heap, min_index, len);
- }
- }
- // 建立小根堆
- void build_min_heap(node_has_space heap[], int len)
- {
- if (heap == NULL)
- return;
- int index = len / 2;
- for (int i = index; i >= 1; i--)
- sift_down(heap, i, len);
- }
- // 去除字串前後符號
- void handle_symbol(char *str, int n)
- {
- while (str[n] < '0' || (str[n] > '9' && str[n] < 'A') || (str[n] > 'Z' && str[n] < 'a') || str[n] > 'z')
- {
- str[n] = '/0';
- n--;
- }
- while (str[0] < '0' || (str[0] > '9' && str[0] < 'A') || (str[0] > 'Z' && str[0] < 'a') || str[0] > 'z')
- {
- int i = 0;
- while (i < n)
- {
- str[i] = str[i+1];
- i++;
- }
- str[i] = '/0';
- n--;
- }
- }
- int main()
- {
- char str[WORDLEN];
- for (int i = 0; i < HASHLEN; i++)
- head[i] = NULL;
- // 將字串用hash函式轉換成一個整數並統計出現頻率
- FILE *fp_passage = fopen("string.txt", "r");
- assert(fp_passage);
- while (fscanf(fp_passage, "%s", str) != EOF)
- {
- int n = strlen(str) - 1;
- if (n > 0)
- handle_symbol(str, n);
- append_word(str);
- }
- fclose(fp_passage);
- // 將統計結果輸入檔案
- write_to_file();
- int n = 10;
- ptr_has_space heap = new node_has_space [n+1];
- int c;
- FILE *fp_word = fopen("result.txt", "r");
- assert(fp_word);
- for (int j = 1; j <= n; j++)
- {
- fscanf(fp_word, "%s %d", &str, &c);
- heap[j].count = c;
- strcpy(heap[j].word, str);
- }
- //