
斯坦福cs231n課程記錄——assignment1 KNN
目錄
- KNN原理
- 某些API解釋
- KNN實現
- 作業問題記錄
- 行業運用
- 演算法改進
- 參考文獻
一、KNN原理
KNN是一種投票機制,依賴少數服從多數的原則,根據最近樣本的標籤進行分類的方法,屬於區域性近似。
優點:
1.簡單(原因在於幾乎不存在訓練,測試時直接計算);
2.適用於樣本無法一次性拿到的情況;
3.KNN是根據周圍鄰近樣本的標籤進行分類的,所以適合於樣本類別交叉或重疊較多的情況;
缺點:
1.測試時間太長,需要計算所有樣本與測試樣本的距離,因此需要提前去除對分類結果影響不大的樣本;
2.不存在概率評分,僅根據樣本標籤判別;
3.當不同類別的樣本數目差異較大時,數目較大的那一類別對KNN判別結果影響較大,因此可能產生誤判;
4.無法解決高維問題
二 .某些API解釋
1. plt.rcParams
作用:設定matplotlib的配置引數
例子:
%matplotlib inline plt.rcParams['figure.figsize'] = (10.0, 8.0) # set default size of plots plt.rcParams['image.interpolation'] = 'nearest' plt.rcParams['image.cmap'] = 'gray'
2. auto_reload
作用:在除錯的過程中,如果程式碼發生更新,實現ipython中引用的模組也能自動更新。
例子:
%load_ext autoreload
%autoreload 2詳情:
3. np.flatnonzero()
作用:矩陣扁平化後返回非零元素的位置
例子:
import numpy as np
x = np.arange(-2,3)
print x
y = np.flatnonzero(x)
print y結果:
[-2 -1 0 1 2]
[0 1 3 4]
np.flatnonzero(y_train == y)
作用:找出標籤中y類的位置
例子:
z = np.flatnonzero(x == -1)
print z結果:
[1]4. np.random.choice
原型:numpy.random.choice(a, size=None, replace=True, p=None)作用:隨機選取a中的值
詳解:
| 引數 | 引數意義 |
|---|---|
| a | 為一維陣列或者int資料; |
| size | 為生成的陣列維度; |
| replace | 是否原地替換; |
| p | 為樣本出現的概率; |
例子:
print(np.random.choice(7,4)) #[0 6 4 6]解釋:在0-7之間隨機選取4個數。等同於np.random.randint(0,7,4)
print(np.random.choice(7,4,p=[0,0.1,0.3,0.2,0,0.2,0.2])) 解釋:p中的值對應a中每個值的概率。
5.reshape中-1
作用:自動計算陣列列數或行數
# Reshape the image data into rows
X_train = np.reshape(X_train, (X_train.shape[0], -1))
X_test = np.reshape(X_test, (X_test.shape[0], -1))
print(X_train.shape, X_test.shape)輸出:
(5000, 3072) (500, 3072)
6. np.linalg.norm
原型:
x_norm=np.linalg.norm(x, ord=None, axis=None, keepdims=False)作用:求範數(詳見參考連線)
例子:
difference = np.linalg.norm(dists - dists_two, ord='fro')
print('Difference was: %f' % (difference, ))
if difference < 0.001:
print('Good! The distance matrices are the same')
else:
print('Uh-oh! The distance matrices are different')輸出:
Difference was: 0.000000
Good! The distance matrices are the same
說明:為了保證向量化的程式碼執行正確,將執行結果與之前的結果對比。對比兩個矩陣是否相等有很多方法,其中較簡單的一種就是使用Frobenius範數。其表示的是兩個矩陣所有元素的差值的均方根。或者將兩個矩陣reshape成向量後,計算其歐式距離。
7. *args, **kwargs
*args表示任何多個無名引數,它是一個tuple
**kwargs表示關鍵字引數,它是一個dict
例子:
def foo(*args,**kwargs):
print('args=',args)
print('kwargs=',kwargs)
print('************')
foo(1,2,3)
foo(a=1,b=2,c=3)
foo(1,2,a=3)輸出:
args= (1, 2, 3)
kwargs= {}
************
args= ()
kwargs= {'a': 1, 'c': 3, 'b': 2}
************
args= (1, 2)
kwargs= {'a': 3}
************
例子:
# Let's compare how fast the implementations are
def time_function(f, *args):
"""
Call a function f with args and return the time (in seconds) that it took to execute.
"""
import time
tic = time.time()
f(*args)
toc = time.time()
return toc - tic
two_loop_time = time_function(classifier.compute_distances_two_loops, X_test)
print('Two loop version took %f seconds' % two_loop_time)8. np.vstack() / np.hstack()
作用:
np.vstack(): 沿著豎直方向將矩陣堆疊起來
np.hstack(): 沿著水平方向將陣列堆疊起來
9. np.argsort(dist[i])
作用:將dist[i]中的元素從小到大排列,提取其對應的index(索引),然後輸出。
10. np.bincount
作用:統計次數
numpy.bincount(x, weights=None, minlength=None)舉例:
y_pred[i] = np.argmax(np.bincount(closest_y))解釋:統計closest_y中每一項標籤出現的次數,再輸出最大次數的closest_y標籤。
三.KNN原理
1. compute_distances_two_loops
原理:雙迴圈就是分別計算每個訓練資料和每個測試資料之間的距離,第一層迴圈是對所有測試資料的迴圈,第二層迴圈是對所有訓練資料的迴圈,使用np.linalg.norm()函式。

def compute_distances_two_loops(self, X):
num_test = X.shape[0]
num_train = self.X_train.shape[0]
dists = np.zeros((num_test, num_train))
for i in range(num_test):
for j in range(num_train):
#####################################################################
# TODO: #
# Compute the l2 distance between the ith test point and the jth #
# training point, and store the result in dists[i, j]. You should #
# not use a loop over dimension. #
#####################################################################
dists[i,j] = np.sqrt(np.dot(X[i] - self.X_train[j],X[i] - self.X_train[j]))
#dists[i,j] = np.linalg.norm(X[i] - self.X_train[j])
#####################################################################
# END OF YOUR CODE #
#####################################################################
return dists2. compute_distances_one_loop
原理:單次迴圈是將每個測試資料通過一次計算就得到和所有訓練資料的距離,其利用了broadcast原理。注意引數axis的設定,axis=1是行相減。

def compute_distances_one_loop(self, X):
num_test = X.shape[0]
num_train = self.X_train.shape[0]
dists = np.zeros((num_test, num_train))
for i in range(num_test):
#######################################################################
# TODO: #
# Compute the l2 distance between the ith test point and all training #
# points, and store the result in dists[i, :]. #
#######################################################################
dists[i,:] = np.linalg.norm(X[i,:] - self.X_train[:], axis = 1)
#######################################################################
# END OF YOUR CODE #
#######################################################################
return dists
3. compute_distances_no_loops
原理:假設測試集是P(m*d),訓練集是C(n*d),其中m是測試資料數量,n是訓練資料數量,d是維度。計算兩者公式如下:
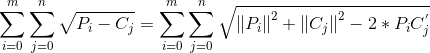
其中,P的形狀為m*1,C的形狀為1*n。
def compute_distances_no_loops(self, X):
num_test = X.shape[0]
num_train = self.X_train.shape[0]
dists = np.zeros((num_test, num_train))
#########################################################################
# TODO: #
# Compute the l2 distance between all test points and all training #
# points without using any explicit loops, and store the result in #
# dists. #
# #
# You should implement this function using only basic array operations; #
# in particular you should not use functions from scipy. #
# #
# HINT: Try to formulate the l2 distance using matrix multiplication #
# and two broadcast sums. #
#########################################################################
dists += np.sum(np.multiply(X, X), axis = 1, keepdims = True).reshape(num_test, 1)
dists += np.sum(np.multiply(self.X_train, self.X_train), axis = 1, keepdims = True).reshape(1, num_train)
dists += -2 * np.dot(X, self.X_train.T)
dists = np.sqrt(dists)
#########################################################################
# END OF YOUR CODE #
#########################################################################
return dists4. 交叉驗證
for k in k_choices:
accuracies = []
for fold in xrange(num_folds):
#X_v = X_train_folds[j]
#y_v = y_train_folds[j]
#X_tr = np.vstack(X_train_folds[0:j] + X_train_folds[j+1:])
#y_tr = np.hstack(y_train_folds[0:j] + y_train_folds[j+1:])
X_tr = X_train_folds[:]
y_tr = y_train_folds[:]
X_v = X_tr.pop(fold)
y_v = y_tr.pop(fold)
X_tr = np.array([y for x in X_tr for y in x])
y_tr = np.array([y for x in y_tr for y in x])
classifier.train(X_tr, y_tr)
dists = classifier.compute_distances_no_loops(X_v)
y_test_pred = classifier.predict_labels(dists, k)
num_correct = np.sum(y_test_pred == y_v)
accuracies.append(float(num_correct) * num_folds / num_training)
k_to_accuracies[k] = accuracies該部分程式碼解釋:
import numpy as np
num_folds = 3
X_train =[1,2,3,4,5,6,7,8,9]
y_train = [10,20,30,40,50,60,70,80,90]
X_train_folds = np.array_split(X_train, num_folds)
y_train_folds = np.array_split(y_train, num_folds)
print(X_train_folds)
print(y_train_folds)
print ('******************')
for fold in xrange(num_folds):
X_tr = X_train_folds[:]
y_tr = y_train_folds[:]
X_v = X_tr.pop(fold)
y_v = y_tr.pop(fold)
X_tr = np.array([y for x in X_tr for y in x]) #將剩餘部分組合成一個數組
y_tr = np.array([y for x in y_tr for y in x])
print(X_tr,y_tr)
print(X_v,y_v)
print ('***')結果:
[array([1, 2, 3]), array([4, 5, 6]), array([7, 8, 9])] [array([10, 20, 30]), array([40, 50, 60]), array([70, 80, 90])] ****************** (array([4, 5, 6, 7, 8, 9]), array([40, 50, 60, 70, 80, 90])) (array([1, 2, 3]), array([10, 20, 30])) *** (array([1, 2, 3, 7, 8, 9]), array([10, 20, 30, 70, 80, 90])) (array([4, 5, 6]), array([40, 50, 60])) *** (array([1, 2, 3, 4, 5, 6]), array([10, 20, 30, 40, 50, 60])) (array([7, 8, 9]), array([70, 80, 90])) ***
四.作業問題記錄
1.
Inline Question #1: Notice the structured patterns in the distance matrix, where some rows or columns are visible brighter. (Note that with the default color scheme black indicates low distances while white indicates high distances.)
- What in the data is the cause behind the distinctly bright rows?
- What causes the columns?

Answer: 某些行顏色偏淺,說明該測試樣本和所有訓練樣本的差異較大,該測試樣本可能明顯過亮或過暗或有色差,或者訓練資料可能有壞點。 某些列顏色偏淺,說明所有測試樣本和該訓練樣本的差異較大,該訓練樣本可能明顯過亮或過暗或有色差。
2.
Inline Question 2 We can also other distance metrics such as L1 distance. The performance of a Nearest Neighbor classifier that uses L1 distance will not change if (Select all that apply.):
- The data is preprocessed by subtracting the mean.
- The data is preprocessed by subtracting the mean and dividing by the standard deviation.
- The coordinate axes for the data are rotated.
- None of the above.
Your Answer:1,2
Your explanation:1和2對座標值的變換都是線性的,如果變換前(x+y+z+...)最小,則變換後(kx+ky+kz+...)也是最小,因此使用L1距離結果不會改變。3是座標軸旋轉,L1距離會變化,L2距離不會。L2距離是[x1,y1]=[[cosβ,sinβ],[-sinβ cosβ]][x,y]T ,即x1=xcosβ+ysinβ,y1=-xsinβ+ycosβ,L2距離不變。L1各向量有具體含義,L2沒有。在面對兩個向量之間的差異時,L2比L1更加不能容忍這些差異。相對於1個巨大差異,L2距離更傾向於多箇中等程度的差異。
3.
Inline Question 3 Which of the following statements about kk-Nearest Neighbor (kk-NN) are true in a classification setting, and for all kk? Select all that apply.
- The training error of a 1-NN will always be better than that of 5-NN.
- The test error of a 1-NN will always be better than that of a 5-NN.
- The decision boundary of the k-NN classifier is linear.
- The time needed to classify a test example with the k-NN classifier grows with the size of the training set.
- None of the above.
Your Answer: Statements 1,4 are true
Your explanation:
Inline Question 3 Which of the following statements about kk-Nearest Neighbor (kk-NN) are true in a classification setting, and for all kk? Select all that apply.
- The training error of a 1-NN will always be better than that of 5-NN.
- The test error of a 1-NN will always be better than that of a 5-NN.
- The decision boundary of the k-NN classifier is linear.
- The time needed to classify a test example with the k-NN classifier grows with the size of the training set.
- None of the above.
Your Answer: Statements 1,4 are true
Your explanation:
1: 當k=1時表示只有最近的點做判斷的依據,因此訓練沒有誤差,k=5的時候,根據vote的規則不同,會有不一樣的訓練誤差。
2: k越小,如果某些資料存在噪聲,過擬合,則泛化能力就差,因此k=1不一定優於k=5;
3: 首先,Knn不是線性分類器,因為輸入和輸出沒有線性關係,其次,knn的分介面是由很多小的線性空間組成,分介面區域性是線性的;
4: 搜尋的量增大。
4. 結果討論
Two loop version took 24.132196 seconds
One loop version took 45.021950 seconds
No loop version took 0.465832 seconds原因:
一次迴圈是每次開記憶體空間導致時間比二次迴圈長。具體來說,一層迴圈會做很多broadcast,該機制開闢空間的耗時很高,因此是該結果。
五、行業運用
待補充
六、演算法改進
待補充
參考文獻:
- https://github.com/sharedeeply/cs231n-camp/blob/master/resource/assignment/assignment1/knn.md
- https://stackoverflow.com/questions/1907993/autoreload-of-modules-in-ipython
- https://blog.csdn.net/hqh131360239/article/details/79061535
- https://blog.csdn.net/zhyh1435589631/article/details/54236643