
人工智慧-遺傳演算法
這是一類智慧的演算法,沒有什麼固定的模式,就是一個演算法思想,可以給我們一些有價值的指導,當我們想要做一些相關工作的時候,可以擴寬我們的視野,開啟我們的腦洞,借鑑其中的原理。我不想多說裡面的什麼數學和公式,只要你懂裡面的思想會遷移到實際的應用中就很不錯,更好的則是在其基礎上形成自己的思維,需要用的話,就像什麼神經網路一樣,最好使用現成的框架。
簡介
遺傳演算法(Genetic Algorithm)是模擬達爾文生物進化論的自然選擇和遺傳學機理的生物進化過程的計算模型,是一種通過模擬自然進化過程搜尋最優解的方法。實際上它是這樣一種演算法,就類似於自然界種群中的生物繁衍一樣,通過不斷的進化和變異不斷產生更加適應環境的個體,這對比與我們的演算法,種群就是我們的樣本集合,個體則是我們單獨的每個樣本,樣本中的每個資料則表示一個基因,進化和變異則是對樣本之間的資料進行處理,更加適應環境的說法則類似於一個評價的標準,類似於神經網路中的損失函式,用於衡量進化和變異得到的新樣本的,用演算法流程圖來形容就是如下所示(文中圖都是引自其他部落格,已在末尾標準引用來源)

那麼通俗的講它的基本原理
第一個基因和染色體的概念
我們知道在生物中,染色體是一個人的性狀集合,其上的基因表示一個人的某個特徵。這類似於數學建模,一個數學方程存在多個可能的解
例如:
x+y+z<10
我們可以輕鬆地知道[1,1,1],[1,2,3],[2,1,1]這些都是方程的解,每個解就是對應著一個染色體也就是一個樣本或者可以說是個體,而解向量中的每個數就表示一個基因。
第二個概念 群體
在進行遺傳演算法初始,我們是需要一個群體的,這就像進化一樣,不可能是一個個體就能繁衍生息。我們需要從一個群體開始,而後進行遺傳和變異等。
上一個例子中,我們有三個個體,它們就可以稱作是一個初始的群體,群體的來源好像可以通過隨機生成,也可以使用一些滿足初始條件的現成的樣本,但是本人自己感覺還是隨意的更改一些,可以覆蓋的範圍更廣一些,但是肯定還是有弊端的。
第三個 交叉和變異
在生物中變異是基因突變等情況,導致生物的某些性狀發生變化,可能是不好的,也可能是對其生存有利的。遺傳演算法中亦是如此,我們對當前存在的基因和樣本進行組合,然和即便通過交叉能保證每次進化留下優良的基因,但它僅僅是對原有的結果集進行選擇,基因還是那麼幾個,只不過交換了他們的組合順序。
為了進一步的得到更加“適應環境”的樣本,我們需要引入變異,這樣通過多次的變異和進化後才能得到
下圖為交叉的示意,通過隨機選擇樣本將二者的對應資料進行交叉,圖所示為將樣本1,2進行位置2之前的交叉,而樣本3,4進行位置4之前的交叉,從交叉結果我們可以看出,樣本之間的資料發生了互換。
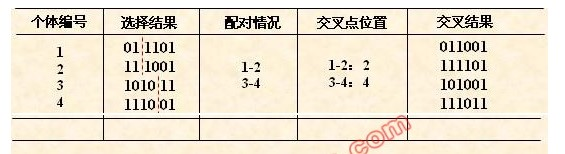
下圖為變異的示意圖,四個樣本在各自的位置發生了變異,導致資料發生變化

第四 適應度
自然界中多數的變異都是導致適應環境的能力更差,我們遺傳演算法中的變異可能也是如此吧,這種情況下如果我們以較差樣本為基礎來進化和變異很大概率會導致得到更差的結果。為此引入了適應度的概念,依舊是類似於自然選擇,使得較差的個體只有較小的概率可以有進化和變異的機會,而優質的個體則會更大可能的繁衍下一代。
這對應到我們演算法中,則是一個函式,用於計算得到樣本的優劣,從而決定其可遺傳的可能性。該函式通過對樣本打分,判定樣本的優劣程度。
第五 選擇運算
前面我們已經有了種群為基礎,並且他們的遺傳概念也已經明確,評判樣本優劣的適應度也定義了,關鍵的一個步驟就是選擇樣本來進行遺傳了。一般要求適應度較高的個體將有更多的機會遺傳到下一代群體中,大概的意思就以其他大佬的圖做例子
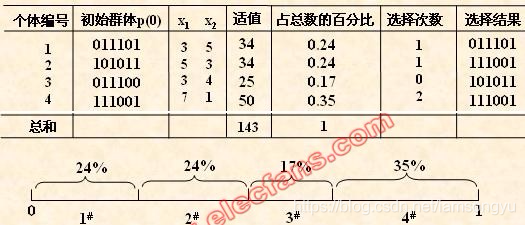
我們可以看到在原始樣本集中存在四個樣本,對於我們要求解的函式而言,四個樣本距離我們想要的最優結果都有一定的距離,根據這個準則我們可以得到他們的適應度,根據適應度大的有更大的機率可以繁衍後代,我們計算四個樣本的佔比,即可遺傳的概率。而後我們使用選擇運算選擇某一個樣本進行遺傳,根據概率第四個樣本的可能性最大,從結果上我們也可以看到在四次的遺傳中,第四個樣本被選擇了兩次,第一二則是一次,這是符合我們概率的可能性的。
第六 個體編碼
這個按照道理應該是最先說的,進行時生物的基因一樣,每個基因是由很多的鹼基序列構成,在計算幾種我們可以這麼理解,一個個體(樣本),他有很多基因(資料點),每個基因是由很多鹼基序列(0,1)構成
上文中樣本【3,5】被表示為【011101】,模仿基因突變是在鹼基的層次上改變的,我們資料的變異也是在對資料編碼後的01序列上。這種操作是否有意義?我們是否可以直接在樣本資料上進行更改,而不是將資料編碼為01之後?
經過我的思考,我覺得這樣操作是有好處的,如果要對一個數據進行變化如何設定變化的範圍,我想這是很難界定的,而如果編碼為01序列之後,我們只需要改變0或者1就可以,沒有其他的情況需要考慮,我們只需要找隨機找個位置然後處理就可以。
附錄 相關的術語 便於理解演算法
基因型(genotype):性狀染色體的內部表現;
表現型(phenotype):染色體決定的性狀的外部表現,或者說,根據基因型形成的個體的外部表現;
進化(evolution):種群逐漸適應生存環境,品質不斷得到改良。生物的進化是以種群的形式進行的。
適應度(fitness):度量某個物種對於生存環境的適應程度。
選擇(selection):以一定的概率從種群中選擇若干個個體。一般,選擇過程是一種基於適應度的優勝劣汰的過程。
複製(reproduction):細胞分裂時,遺傳物質DNA通過複製而轉移到新產生的細胞中,新細胞就繼承了舊細胞的基因。
交叉(crossover):兩個染色體的某一相同位置處DNA被切斷,前後兩串分別交叉組合形成兩個新的染色體。也稱基因重組或雜交;
變異(mutation):複製時可能(很小的概率)產生某些複製差錯,變異產生新的染色體,表現出新的性狀。
編碼(coding):DNA中遺傳資訊在一個長鏈上按一定的模式排列。遺傳編碼可看作從表現型到基因型的對映。
解碼(decoding):基因型到表現型的對映。
個體(individual):指染色體帶有特徵的實體;
種群(population):個體的集合,該集合內個體數稱為種群的大小。
參考文章:
https://blog.csdn.net/qq_31805821/article/details/79763326
https://baike.baidu.com/item/%E9%81%97%E4%BC%A0%E7%AE%97%E6%B3%95/838140?fr=aladdin
https://www.jianshu.com/p/ae5157c26af9
https://blog.csdn.net/u010425776/article/details/79155480
https://blog.csdn.net/u012422446/article/details/68061932