
google機器學習框架tensorflow學習筆記(九)
阿新 • • 發佈:2019-01-06
泛化 (Generalization):過擬合的風險
本單元將重點介紹泛化。為了讓您直觀地理解這一概念,我們將展示 3 張圖。假設這些圖中的每個點代表一棵樹在森林中的位置。圖中的兩種顏色分別代表以下含義:- 藍點代表生病的樹。
- 橙點代表健康的樹。
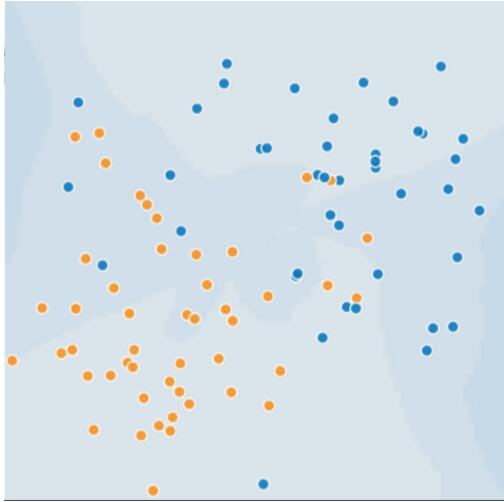 圖 1. 生病(藍色)和健康(橙色)的樹。
圖 1. 生病(藍色)和健康(橙色)的樹。
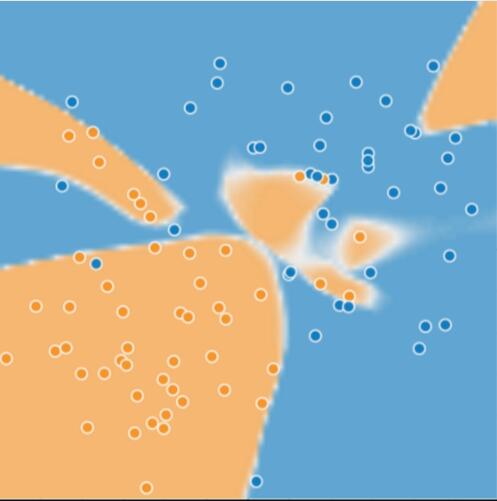 圖2.用於區分生病的樹與健康的樹的複雜模型。
乍一看,圖2所示的模型在將健康的樹與生病的樹區分開方面似乎表現得非常出色,但真的是這樣的嗎?
圖2.用於區分生病的樹與健康的樹的複雜模型。
乍一看,圖2所示的模型在將健康的樹與生病的樹區分開方面似乎表現得非常出色,但真的是這樣的嗎?
損失很低,但仍然是糟糕的模型?
圖 3 顯示我們向該模型中添加了新資料後所發生的情況。結果表明,該模型在處理新資料方面表現非常糟糕。請注意,該模型對大部分新資料的分類都不正確。
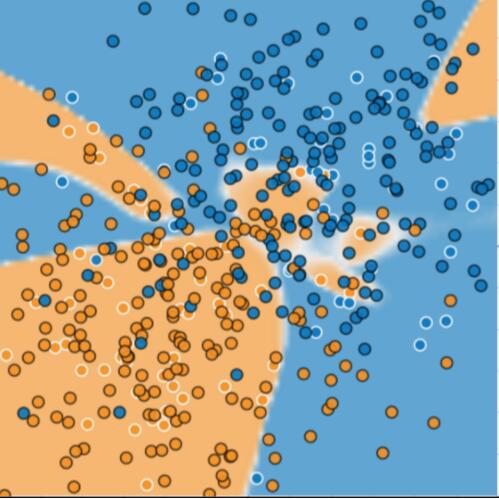 圖 3. 該模型在預測新資料方面表現非常糟糕。
圖 2 和圖 3 所示的模型
過擬合
了訓練資料的特性。過擬合模型在訓練過程中產生的損失很低,但在預測新資料方面的表現卻非常糟糕。如果某個模型在擬合當前樣本方面表現良好,那麼我們如何相信該模型會對新資料做出良好的預測呢?
過擬合是由於模型的複雜程度超出所需程度而造成的。機器學習的基本衝突是適當擬合我們的資料,但也要儘可能簡單地擬合數據。
機器學習的目標是對從真實概率分佈(已隱藏)中抽取的新資料做出良好預測。遺憾的是,模型無法檢視整體情況;模型只能從訓練資料集中取樣。如果某個模型在擬合當前樣本方面表現良好,那麼您如何相信該模型也會對從未見過的樣本做出良好預測呢?
圖 3. 該模型在預測新資料方面表現非常糟糕。
圖 2 和圖 3 所示的模型
過擬合
了訓練資料的特性。過擬合模型在訓練過程中產生的損失很低,但在預測新資料方面的表現卻非常糟糕。如果某個模型在擬合當前樣本方面表現良好,那麼我們如何相信該模型會對新資料做出良好的預測呢?
過擬合是由於模型的複雜程度超出所需程度而造成的。機器學習的基本衝突是適當擬合我們的資料,但也要儘可能簡單地擬合數據。
機器學習的目標是對從真實概率分佈(已隱藏)中抽取的新資料做出良好預測。遺憾的是,模型無法檢視整體情況;模型只能從訓練資料集中取樣。如果某個模型在擬合當前樣本方面表現良好,那麼您如何相信該模型也會對從未見過的樣本做出良好預測呢?機器學習模型越簡單,良好的實證結果就越有可能不僅僅基於樣本的特性。
機器學習模型旨在根據以前未見過的新資料做出良好預測。但是,如果您要根據資料集構建模型,如何獲得以前未見過的資料呢?一種方法是將您的資料集分成兩個子集:
- 訓練集 - 用於訓練模型的子集。
- 測試集 - 用於測試模型的子集。
一般來說,在測試集上表現是否良好是衡量能否在新資料上表現良好的有用指標,前提是:
- 測試集足夠大。
- 您不會反覆使用相同的測試集來作假。
機器學習細則
以下三項基本假設闡明瞭泛化:
- 我們從分佈中隨機抽取獨立同分布 (i.i.d) 的樣本。換言之,樣本之間不會互相影響。(另一種解釋:i.i.d. 是表示變數隨機性的一種方式)。
- 分佈是平穩的;即分佈在資料集內不會發生變化。
- 我們從同一分佈的資料劃分中抽取樣本。
在實踐中,我們有時會違背這些假設。例如:
- 想象有一個選擇要展示的廣告的模型。如果該模型在某種程度上根據使用者以前看過的廣告選擇廣告,則會違背 i.i.d. 假設。
- 想象有一個包含一年零售資訊的資料集。使用者的購買行為會出現季節性變化,這會違反平穩性。
- 如果某個模型嘗試緊密擬合訓練資料,但卻不能很好地泛化到新資料,就會發生過擬合。
- 如果不符合監督式機器學習的關鍵假設,那麼我們將失去對新資料進行預測這項能力的重要理論保證。