
神經網路解決推薦系統問題(NCF)
前一篇雖然是整理的AFM,但有提到過並行的DeepFM,也自然是還有序列的NFM,本來是想整理這兩部分,但是想來它們其實都是利用FM和DNN進行各種各樣的組合以提升模型的效果。所以不管是由共享embedding層的左邊FM和右邊DNN部分組成,而且可以同時學習到高維和低維的特徵的DeepFM;還是序列結合的NFM使用部分非線性點乘以提升多階互動資訊的能力等,他們確實是利用了神經網路DNN結合,在一定程度上解決了普通FM由於計算複雜度往往只用到二階而且只是線性組合的問題,而AFM也是利用了注意力機制給不同的特徵組合加以權重來體現它不同的重要程度。都是基於了FM,而FM某種程度上也是將傳統的

MF模型是使用者和專案的潛在因素的雙向互動,它假設潛在空間的每一維都是相互獨立的並且用相同的權重將它們線性結合。因此,MF可視為潛在因素(latent factor)的線性模型。所謂潛在因素就是雖然使用者與專案間有互動,但不一定使用者就喜歡了,而沒互動也不代表不喜歡,這就對隱形學習帶來了噪音。
上圖展示了的內積函式如何限制MF的表現力。簡單來說就是通過計算相似度(如Jaccard相似係數)產生對映時,原本應該與u3更相似的u4將會被排在與u1接近的地方。(如前三個
,而對於u4來說
,便產生了誤差)
而NCF直接使用DNN從資料中學習互動函式,從而突破了由於MF表達時的限制。它的通用框架為:
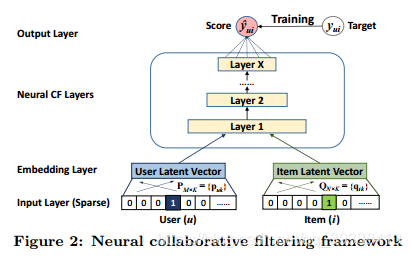
同樣是利用Embedding Layer將輸入層的稀疏表示對映為一個新的潛在向量。然後分別將使用者嵌入和專案嵌入送入多層神經網路結構,它將潛在向量對映為預測分數。
得到損失函式後同樣用SGD來訓練。通用模型的具體體現在於:
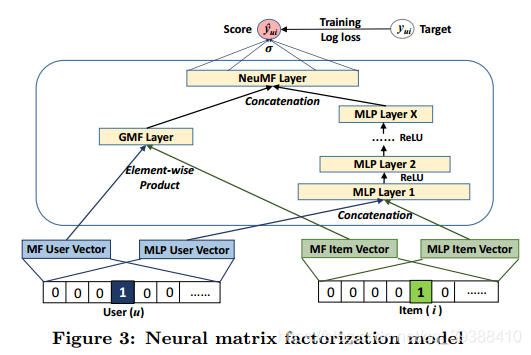
左邊是一個GMF。其中 aout 和 h分別表示輸出層的啟用函式和連線權重。
而右邊是MLP模型。其中 Wx, bx 和 ax 分別表示 x 層的感知機中的的權重矩陣,偏置向量(神經網路的神經元閾值)和啟用函式。
最後使兩者能夠做到相互嵌入,使得融合模型具有更大的靈活性。
def get_model(num_users, num_items, latent_dim, regs=[0,0]):#GMF部分程式碼
#輸入變數
user_input = Input(shape=(1,), dtype='int32', name = 'user_input')
item_input = Input(shape=(1,), dtype='int32', name = 'item_input')
#embedding層
MF_Embedding_User = Embedding(input_dim = num_users, output_dim = latent_dim, name = 'user_embedding',
init = init_normal, W_regularizer = l2(regs[0]), input_length=1)
MF_Embedding_Item = Embedding(input_dim = num_items, output_dim = latent_dim, name = 'item_embedding',
init = init_normal, W_regularizer = l2(regs[1]), input_length=1)
# flatten處理,便於後面操作
user_latent = Flatten()(MF_Embedding_User(user_input))
item_latent = Flatten()(MF_Embedding_Item(item_input))
#合併embedding層
predict_vector = merge([user_latent, item_latent], mode = 'mul')
#得到預測值
#prediction = Lambda(lambda x: K.sigmoid(K.sum(x)), output_shape=(1,))(predict_vector)
prediction = Dense(1, activation='sigmoid', init='lecun_uniform', name = 'prediction')(predict_vector)
model = Model(input=[user_input, item_input],
output=prediction)
return model
def get_model(num_users, num_items, layers = [20,10], reg_layers=[0,0]):#MLP部分程式碼
assert len(layers) == len(reg_layers)
num_layer = len(layers) #MLP層數
#輸入變數
user_input = Input(shape=(1,), dtype='int32', name = 'user_input')
item_input = Input(shape=(1,), dtype='int32', name = 'item_input')
#embedding層
MLP_Embedding_User = Embedding(input_dim = num_users, output_dim = layers[0]/2, name = 'user_embedding',
init = init_normal, W_regularizer = l2(reg_layers[0]), input_length=1)
MLP_Embedding_Item = Embedding(input_dim = num_items, output_dim = layers[0]/2, name = 'item_embedding',
init = init_normal, W_regularizer = l2(reg_layers[0]), input_length=1)
# flatten處理,便於後面操作
user_latent = Flatten()(MLP_Embedding_User(user_input))
item_latent = Flatten()(MLP_Embedding_Item(item_input))
#合併embedding層
vector = merge([user_latent, item_latent], mode = 'concat')
#構