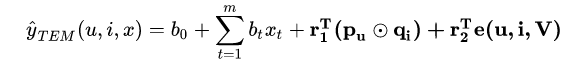神經網路解決推薦系統問題(可解釋性與TEM)
阿新 • • 發佈:2019-01-06

在綜述中紛紛云云一言以蔽之就是各種技術的排列組合和效能優化。但神經網路很讓人詬病的是它的“黑匣子”特性,在應用於推薦系統中時我們往往無法理解,即沒有有效的可解釋性。
比如CF 是很好的個性化推薦主流技術,但它只對使用者–專案互動進行建模,不能為推薦提供具體的理由(僅僅是你的朋友喜歡那麼你就會喜歡,這樣的理由往往太過粗糙)。技術上更是因為在基於embedding的方法後,如Wide&Deep和FM等,雖然有很好的推薦效能,但是它們就像黑匣子一樣工作,無法解釋embedding後的隱變數究竟是什麼,也無法明確說明預測的理由。而基於樹的方法,如決策樹,只是通過從資料中推斷決策規則來進行預測的,而忽視了互動特性,因此它具有在協作性、擴充套件性的場景效果不佳。於是乎:
Tree-enhanced Embedding Method (樹增強嵌入方法,TEM)
比如上面的GBDT樹,具體分類標準如下:
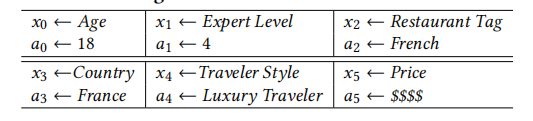
從根結點到葉結點的路徑可以看作形成了一個決策規則,這就形成了天然的自解釋的性質。但是由於單純的tree在面對未知特徵,比如使用者和商品的ID時樹模型的泛化能力很差。於是再採用embedding:

即該模型先使用GBDT來構造各種交叉特徵(構造完畢後),然後利用交叉特徵,僅僅使用embedding和attention機制來代替全連線層(全連線層的高抽象能力產生的非線性,也沒有了模型的可解釋性)。其中模型中的attention net具體為:
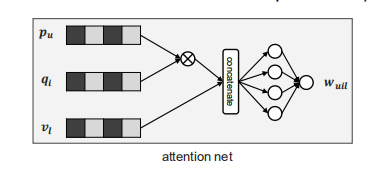
是(u,i)的第 l 個交叉向量的權重,但是對於沒記錄即(u,i)不存在的情況下無法估計這個權重,所以作者將它看作是一個獨立函式,然後用MLP來估計它。最後再用max或者avg來聚合特徵。