
Autoencoder(自編碼器)
自編碼器原理:
在神經網路中是監督學習下的操作,那麼它又如何應用到無監督學習中呢?一個直觀的想法就是讓經過了神經網路的輸入等於元輸入,或者儘量相差不大。這樣做不就可以學習到輸入資料中隱含著某些特定的結構,甚至通過設計神經元數目來完成資料壓縮嗎?自編碼器由一個編碼器(encoder)函式和一個解碼器(decoder)函式組合而成。編碼器函式將輸入資料轉換為一種不同的表示,而解碼器函式則將這個新的表示轉換到原來的形式,儘可能復現輸入訊號的神經網路,而為了實現這種復現,自動編碼器就必須自動捕捉可以代表輸入資料的最重要的因素。
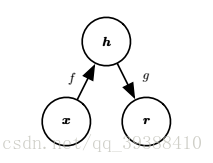
編碼器 將 對映到 ,解碼器 將 對映到 。 和 應儘可能的相似。當然了,度量這個相似度,需要一個損失函式,根據解碼器的不同,損失函式可以有多種取法,比如如果是恆等函式可取平方誤差: 如果是為Sigmoid函式則取交叉熵
最小化這個函式即可得到相似的 了,但是它目前只是學到了一個好的特徵,能在最大程度上代替原資料。如果是為了實現分類,那麼可以在自動編碼器的最頂層新增一個分類器(邏輯迴歸,SVM等),然後通過標準的多層神經網路的監督訓練(梯度下降)去訓練。這樣做能使分類效果得到很大的提升。
如果編碼器直接就學習到r=x怎麼辦?自編碼器的變體們
稀疏自動編碼器(Sparse AutoEncoder):SA是在自動編碼器的基礎上,加入了L1正則化的限制,這樣可以讓每次得到的code儘量稀疏,至於為什麼…因為稀疏的表達往往比其他的表達要有效(人腦也是這樣,某個輸入只會刺激某些神經元(1%~4%),其他大部分的神經元是收到抑制的)。所以此時的損失函式J為:
降噪自動編碼器(Denoising AutoEncoders):DA是在自動編碼器的基礎上,在訓練的資料中加入了噪聲,這樣做可以讓自動編碼器必須學習去如何去除這種噪聲來獲得真正的沒有被噪音汙染過的輸入,使得到的結果泛化能力強。
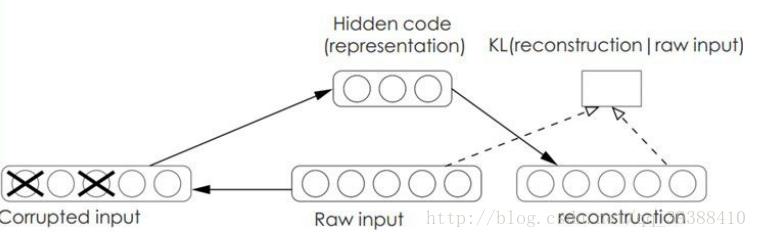
稀疏編碼(Sparse Coding):自編碼器的目的是有效的找出隱含的資料內部的結構和模式,參考人大腦的神經元其實只對某些“重點”感興趣,比如在影象中的邊緣,所以“稀疏”是很必要的手段。首先如果把輸出必須和輸入必須相等的限制放鬆,同時利用線性代數中基的概念,使:
其中a係數表示的是輸入樣本的特徵。那麼問題就變成了尋找一組最好的基。而一般情況下要求基的個數k非常大,甚至一般情況下要比n大很多,所以將導致a係數不能唯一確定。所以需要對係數a作稀疏性約束,此時系統對應的損失函式為:
同時還對基也進行限制,讓 小於等於C,這樣才能使矩陣更加的稀疏。再優化這個損失函式,由於有a和 兩個變數,可以運用EM的思想,即先固定 ,調整a,是損失函式最小(由於加了正則化,即解LASSO問題);然後固定a,調整 ,使損失函式最小(凸優化問題),不斷迭代,最後能得到一組很好的基了。
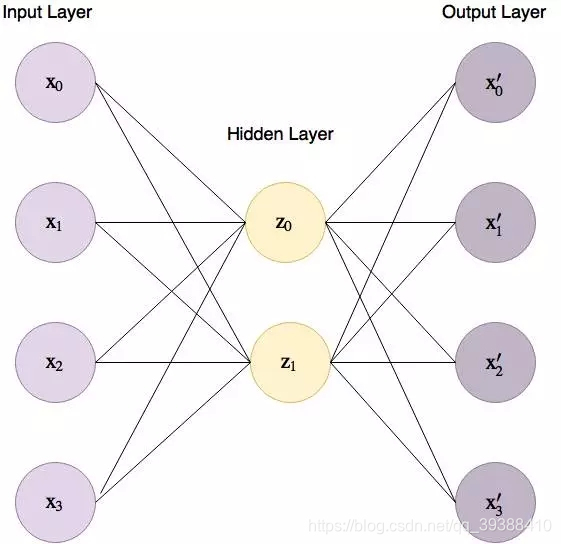
這張圖會更加的清晰,而且中間層是可以任由我們自己設計與控制的。
def fit(self, n_dimensions):
graph = tf.Graph()
with graph.as_default():
# 輸入X
X = tf.placeholder(self.dtype, shape=(None, self.features.shape[1]))
#初始化權重
encoder_weights = tf.Variable(tf.random_normal(shape=(self.features.shape[1], n_dimensions)))
encoder_bias = tf.Variable(tf.zeros(shape=[n_dimensions]))
decoder_weights = tf.Variable(tf.random_normal(shape=(n_dimensions, self.features.shape[1])))
decoder_bias = tf.Variable(tf.zeros(shape=[self.features.shape[1]]))
# Encoder
encoding = tf.nn.sigmoid(tf.add(tf.matmul(X, encoder_weights), encoder_bias))
# Decoder
predicted_x = tf.nn.sigmoid(tf.add(tf.matmul(encoding, decoder_weights), decoder_bias))
#損失函式
cost = tf.reduce_mean(tf.pow(tf.subtract(predicted_x, X), 2))
optimizer = tf.train.AdamOptimizer().minimize(cost)
with tf.Session(graph=graph) as session:
# Initialize global variables
session.run(tf.global_variables_initializer())
for batch_x in batch_generator(self.features):
self.encoder['weights'], self.encoder['bias'], _ = session.run([encoder_weights, encoder_bias, optimizer],
feed_dict={X: batch_x})
def reduce(self):
return np.add(np.matmul(self.features, self.encoder['weights']), self.encoder['bias'])