
CSDN檢視關注人的所有部落格方法(改版後Bug解決)
在CSDN覺得某些大牛文章寫得很好,點了一波關注,某一天,突然想回頭看一下自己看過的某篇文章,點開,我關注的人,卻發現關注的人裡的部落格只顯示了最近幾篇的文章,想要找之前的文章卻找不到了,如下圖:


這時,我們需要將頁面網址進行修改:
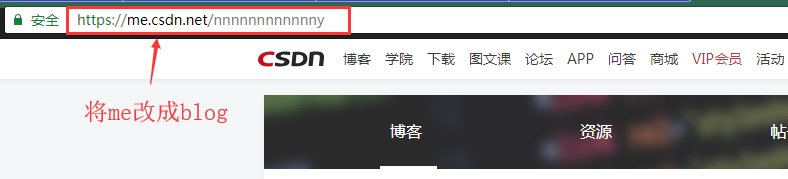

找到老版本的翻頁鈕了,可以檢視之前看過的部落格了
相關推薦
CSDN檢視關注人的所有部落格方法(改版後Bug解決)
在CSDN覺得某些大牛文章寫得很好,點了一波關注,某一天,突然想回頭看一下自己看過的某篇文章,點開,我關注的人,卻發現關注的人裡的部落格只顯示了最近幾篇的文章,想要找之前的文章卻找不到了,如下圖: 這時,我們需要將頁面網址進行修改: 找到老版本的翻頁
CSDN怎麼轉載別人的部落格方法 很好用
自己是新手用了以下方法,感覺很好用 參考部落格原址:http://blog.csdn.net/bolu1234/article/details/51867099 參考部落格原址:https://blog.csdn.net/zh
從csdn搬家到部落格園(無盡的藍黃)
用csdn寫部落格已經有兩年多了,可以說csdn記錄了我作為IOer兩年來的經歷。 但是用久了也覺得csdn似乎有些差強人意, 1、介面太單調了,也不能改改背景之類的,為了給讀者更好的觀博體驗,我覺
反向傳播算法(過程及公式推導)
不能 簡化 會有 geo 之前 代碼 求和 不同 eof 一、反向傳播的由來 在我們開始DL的研究之前,需要把ANN—人工神經元網絡以及bp算法做一個簡單解釋。關於ANN的結構,我不再多說,網上有大量的學習資料,主要就是搞清一些名詞:輸入層/輸入神經元,輸出層/輸出神經元,
字符串哈希算法(以ELFHash詳解)
不為 查詢 查看 i++ 結果 amp 直接 ble 散列函數 更多字符串哈希算法請參考:http://blog.csdn.net/AlburtHoffman/article/details/19641123 先來了解一下何為哈希: 哈希表是根據設定的哈希函數H(key)和
縱裏尋她千百度,暮然回首,那人卻在燈火闌珊處(微信三方登陸)
判斷 esp sage 邏輯判斷 平臺 hat 小技巧 開放平臺 註意 小插曲就是app做微信三方登陸是很久之前,後面又添加了PC的微信三方登陸,而文檔上說unionid是同一個賬號下不同應用統一的,但是app拿的是uid,導致pc拿的unionid始終對不上,導致浪費了一
【算法】Gh0st配置加密算法(異或、Base64)
異或 urn byte break down unsigned ltib else lower 1、前言 分析木馬程序常常遇到很多配置信息被加密的情況,雖然現在都不直接分析而是通過Wireshark之類的直接讀記錄。 2017年Gh0st樣本大量新增,通過對木馬源碼的分析還
哈希表及其常用算法(代碼實例)
div 意義 imp ini insert HR 哈希函數 技術分享 sun <hash表的特性> Hash 表是使用 O(1) 時間進行數據的插入刪除和查找,但是 hash 表不保證表中數據的有序性,這樣在 hash 表中查找最大數據或者最小數據的時間
BFS算法(——模板習題與總結)
pos ref 數據 OS 三種 容器 模板 意思 ++ 首先需要說明的是BFS算法(廣度優先算法)本質上也是枚舉思想的一種體現,本身效率不是很高,當數據規模很小的時候還是可以一試的。其次很多人可能有這樣的疑問,使用搜索算法的時候,到底選用DFS還是BFS,博主覺得對於
最簡單的排序算法(C和C++實現)
最簡單的排序算法(C和C++實現)1、算法思想如下圖:把待排序的數都存在對應的數組的下標中,如果待排序的數有重復的,就用對應的數組加一,最後把數組的下標打印出來即可。2、源碼(C)如下:#include <stdio.h>int main (void){ int a[100], i, j,
有關素數判斷的一些算法(總結&&對比)
stat names 最小 csdn fread AR 目前 ike new 素性測試是數論題中比較常用的一個技巧。它可以很基礎,也可以很高級(哲學)。這次主要要介紹一下有關素數判斷的奇技淫巧 素數的判斷主要分為兩種:範圍篩選型&&單個判斷型 我們先從範圍篩
歐幾裏得算法(求最大公約數)
include spa end IV ios sin int 計算 name 1 //求兩個數的最大公約數 2 #include<iostream> 3 using namespace std; 4 int f(int m,int n) 5 { 6
KMP算法(查找子序列)
算法 c代碼 ott 假設 filter 匹配 起點 同時 abd KMP類似暴力,但是不會和暴力完全一樣,回溯到起點。 簡單的說 假如 模板鏈字符串是: abcabcabcabd 尋找abcabd 在模板鏈出現的次數,並且輸出該次數。
求兩個數的最大公約數,輾轉相除法與更相減損法(遞歸叠代)
叠代 div 余數 公約數 穩定 log test 算法 復雜度 問題:給出兩個數a和b,求出他們的最大公約數(greatest common divisor)。 解法一:輾轉相除法,又叫歐幾裏得算法。兩個正整數a和b(a>b),他們的最大公約數等於a除以b的余數和b
如何得到一個接口所有的實現類(及子接口)?例如:Eclipse IDE
name 解析 例如 圖片 沒有 選中 java 叠代 interface (一)Eclipse IDE的做法 它會解析所有的Java文件、Class文件。技巧:在Eclipse中,選中Interface,按下F4,就可以查看到所有的實現類及子接口。 例如: (二)自己怎麽
移動平均法,滑動平均模型法(Moving average,MA)
什麼是移動平均法 移動平均法是用一組最近的實際資料值來預測未來一期或幾期內產品的需求量的一種常用方法。移動平均法適用於即期預測。當產品需求既不快速增長也不快速下降,且不存在季節性因素時,移動平均法能有效地消除預測中的隨機波動,是非常有用的。移動平均法根據預測時使用的各元素的權重不同,可以變為加權
c++分塊算法(暴力數據結構)
復雜度 spl nlogn 部分 基本 拓展 多說 操作 數據結構 快要noip了,該寫些題解攢攢rp了(逃) 看到題解裏那麽多線段樹啊,樹狀數組啊,本蒟蒻表示:這都是什麽鬼東西? 在所有高級數據結構中,樹狀數組是碼量最小的,跑的也基本是最快的,但理解很難,並且支持的操作很
哨兵查詢法(明解c語言)
//哨兵法,就是將待查詢的元素加入待查詢的陣列的後面,這樣可以提高效能(在資料量很龐大的時候體現出來) #include <stdio.h> #define FAILURE -1 //使用for迴圈的 int searching1(int v[],int key,int n) {
堆排序法(Java & C/C++ 實現)
一、前言 堆排序是利用堆這種資料結構而設計的一種排序演算法。時間複雜度為 O(n * lg n)。 介紹堆排序前,我們先介紹一下堆的相關概念,如果你對堆的概念還不熟悉的話可以看看。 二、堆 1. 示意圖 2. 性質 除最底層外,該樹是完全充滿的,且是從左到右填充。 樹的根結點是 A[
拉格朗日乘子法(有約束優化問題)
拉格朗日乘子法(Lagrange Multiplier)和KKT(Karush-Kuhn-Tucker)條件是求解約束優化問題的重要方法,在有等式約束時使用拉格朗日乘子法,在有不等約束時使用KKT條件。前提是:只有當目標函式為凸函式時,使用這兩種方法才保證求得的是最優