
SiamRPN---High Performance Visual Tracking with Siamese Region Proposal Network
阿新 • • 發佈:2019-01-06
1. Introduction
- 目前的跟蹤器可以分為兩大類:
1.第一類是基於相關濾波:通過利用迴圈特性在傅立葉域訓練一個迴歸器,能夠線上跟蹤並更新濾波器引數。近來一些相關濾波演算法通過使用深度特徵來提高精度,但在濾波器更新是嚴重降低了速度。
2.另一類方法是使用非常強大的深度特徵,此類方法不更新模型,所以效能沒有相關濾波好。 - 本文提出的SiamRPN是離線訓練好的基於深度特徵的跟蹤器,並取得了比目前最先進相關濾波方法更優的效能。SiamRPN由模板分支和檢測分支組成,用端到端的方法在大規模的影象對上進行離線訓練。不同於標準的RPN,本文使用兩個分支的相關特徵圖來提取候選區域。由於跟蹤任務不區分類別,所以作者將模板分支上的目標外觀資訊編碼到RPN特徵中來判別前景和背景。
- 貢獻可總結為以下三點:
1.提出了孿生區域建議網路,能夠利用ILSVRC和Youtube-BB大量的資料進行離線端到端訓練。
2.線上跟蹤時,將proposed framwork視為單目標的檢測任務,這使得可以不用高耗時的多尺度測試就能精確的候選區域。
3.在VOT2015, VOT2016 and VOT2017的實時比賽中達到了最優效能,並且可達到160FPS,同時具有精度的效率的優勢。
2. Related Works
2.1 RPN in detection
- RPN是在Faster R-CNN提出來的,後來Faster R-CNN的變種如FPN利用特徵金字塔來提高小目標檢測的效能。
2.2 One-shot learning
- 最常見的例子就是人臉檢測,只知道一張圖片上的資訊,用這些資訊來匹配出要檢測的圖片,這就是單樣本檢測,也可以稱之為一次學習。
3. Siamese-RPN framework
- Siamese-RPN由提取特徵的Siamese子網路和區域生成的候選區域子網路組成。
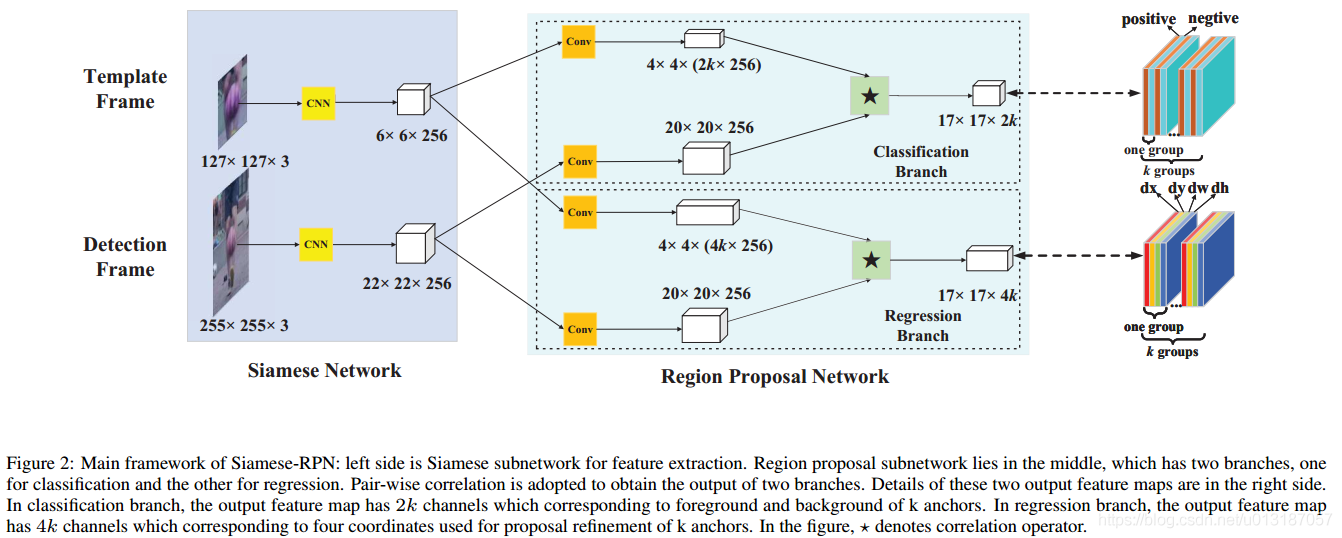
3.1 Siamese feature extraction subnetwork
- 網路基於AlexNet
- 該子網路由模板分支和檢測分支組成:模板分支將歷史幀的目標塊作為輸入,用 表示;檢測分支用當前幀的目標塊作為輸入,用 表示。兩個網路共享CNN引數,用 和 表示網路輸出。
3.2 Region proposal subnetwork
- 該子網路由分類分支和迴歸分支組成,分類分支輸出有 個channels(前景和背景),迴歸分支有 個channels( ),其中 表示anchors,即每個位置預測框的個數。
- 分類分支使用cross-entropy損失,迴歸分支使用Faster R-CNN中的smooth 損失。
3.3 Training phase:End-to-end train Siamese-RPN
- sample pairs:從ILSVRC隨機間隔幀和Youtube-BB連續幀提取
- Siamese子網路首先在ImageNet上進行預訓練,然後用SGD對Siamese-RPN進行端到端訓練
- 由於在跟蹤任務中相鄰幀間的變化不會太大,所以選用的anchors個數比檢測任務要少。只選用了一個尺度的5種不同寬高比
- 正樣本:IOU ,負樣本:IOU
- 對每個樣本對限制最多16個正樣本和總共64個樣本
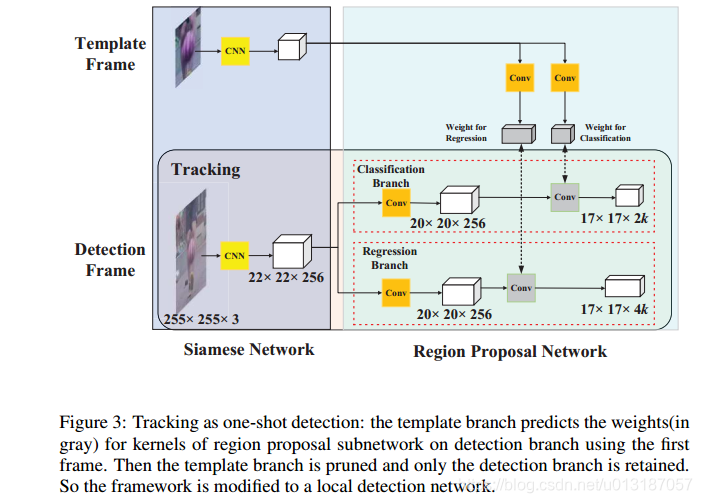
4. Tracking as one-shot detection
4.1 Formulation
- 平均損失
1.
訓練的網路權重
2. 表示Siamese子網路
3. 表示 RPN子網路
4. 表示樣本對數
5. 表示樣本標籤
4.2 Inference phase:Perform one-shot detection
- 模板分支在初始幀得到的輸出作為檢測分支的卷積核,然後在整個跟蹤過程中固定不變。
4.3 Proposal selection
- 直接丟棄距中心太遠的BB,如下圖所示,丟棄大於7的BB
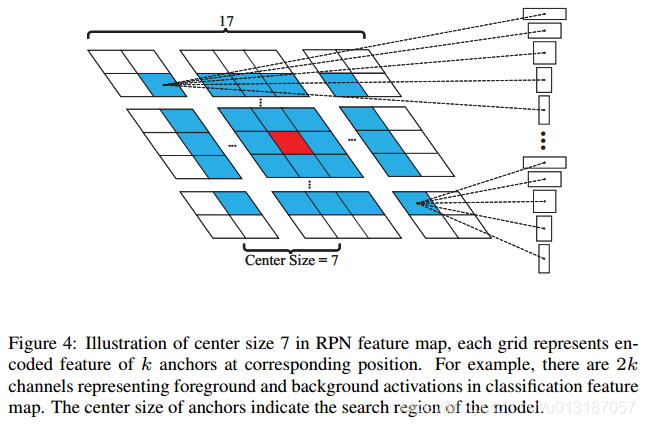
- 用餘弦窗和尺度變化懲罰來對proposal進行排序,選最好的。餘弦窗是為了抑制距離過大的,尺度懲罰是為了抑制尺度大的變化。
- 非極大值抑制(NMS)
5. Experiments
5.1 Implementation details
5.2 Result on VOT2015
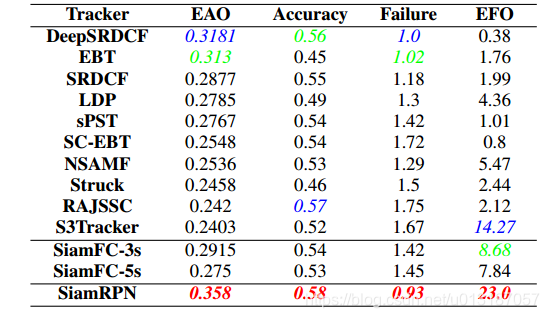
5.2 Result on VOT2016
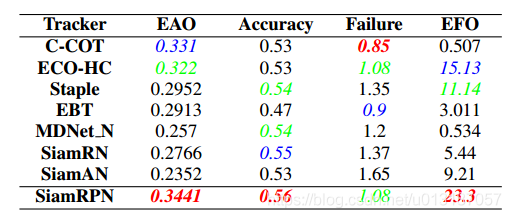
5.4 Result on VOT2017
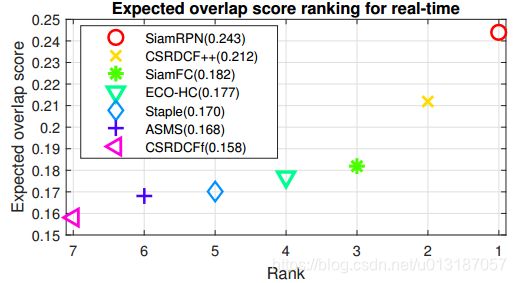
6. 與baseline–SiamFC對比
- 視覺跟蹤領域主流的實時跟蹤方法是以SiameseFC為代表的孿生網路結構,Siamese FC網路非常簡單,通過相同的網路提取出影象的特徵,通過類似卷積的相關操作方法,可以快速的實現模板與搜尋區域中的17x17個小影象進行比對,輸出的17x17的響應圖,相當於每個位置和模板幀的相似度。但SiameseFC有以下缺陷:首先由於沒有迴歸,網路無法預測尺度上的變化,所以只能通過多尺度測試來預測尺度的變化,這裡會降低速度。其次,輸出的相應圖的解析度比較低,為了得到更高精度的位置,Siamese FC採用插值的方法,把解析度放大16倍,達到與輸入尺寸相近的大小。
- SiameseRPN通過引入物體檢測領域的區域推薦網路(RPN),通過網路迴歸避免多尺度測試,一方面提升了速度,另一方面可以得到更為精準的目標框,更進一步,通過RPN的迴歸可以直接得到更精確地目標位置,不需要通過插值得到最終的結果。在訓練過程中,我們引入了大規模的視訊資料集Youtube-BB進行訓練,相比較SiameseFC使用的VID資料集,Youtube-BB在視訊數量上有大約50倍的提升,這保證了網路能夠得到更為充分的訓練。