
R語言中向量&矩陣&陣列&資料框&列表的區別與聯絡
向量:
包含一個元素或多個元素

矩陣:
由向量構成,是一個特殊的陣列,即維數等於2的陣列

陣列:
與只能有二維的矩陣不同的是,陣列的維數不限,但元素的資料型別必須一致,即數值型都是數值型,字串都是字串

資料框:
與陣列不同的是,資料框裡面的資料型別可以不一致,但向量維數必須相等,即各列資料長度相等

列表:
最寬泛的一個集合,它的資料型別可以不一致,長度也可以不一致,可以由向量,矩陣,陣列,資料框,函式,甚至是列表組成


總結:
向量|矩陣|陣列|資料框|列表 是一個逐步包含的關係,
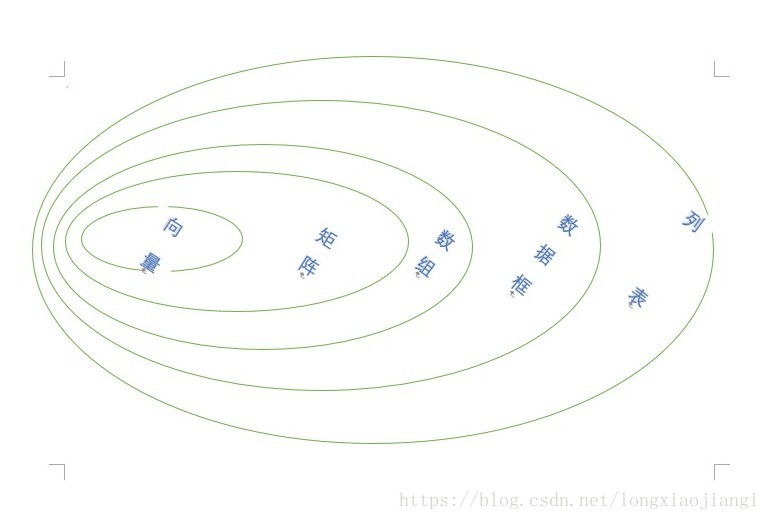
相關推薦
R語言中向量&矩陣&陣列&資料框&列表的區別與聯絡
向量: 包含一個元素或多個元素 矩陣: 由向量構成,是一個特殊的陣列,即維數等於2的陣列 陣列: 與只能有二維的矩陣不同的是,陣列的維數不限,但元素的資料型別必須一致,即數值型都是數值型,字串都是字串 資料框: 與陣列不同的
在R語言中建立、使用資料框
《R語言實戰》筆記 —— 建立資料集之資料框 資料框是R中最常處理的資料結構,資料框不同的列可以包含不同模式(數值型、字元型等)的資料。 1. 建立資料框 mydata <- data.frame( col1, col2, col3,...)
R語言中兩個陣列(或向量)的外積如何計算
所謂陣列(或向量)a和b的外積,指的是a的每一個元素和b的每一個元素搭配在一起相乘得到的新元素.當然運算規則也可自定義.外積運算子為 %o%(注意:百分號中間的字母是小寫的字母o).例如:> a <- 1:2 > b <- 3:5 > d <
R語言使用tibble實現簡單資料框
library(tidyverse) ####建立tibble as_tibble(iris) #將資料框轉換為tibble tibble( x = 1:5, y = 1, z = x ^ 2 + y ) #使用tibble()將一個向
R語言中刪除重複的資料行
duplicated() determines which elements of a vector or data frame are duplicates of elements with smaller subscripts, and returns a logical vector indic
R語言中向量的加法和乘法
在R語言中,不同長度的向量也是可以相加和相乘的,乘法的規則和加法類似 1,相同長度的向量相加 > x<- 1:4 > y<- 1:4 > z<- x+y > z [1] 2 4 6 8 規則就是 x[1]+y[1],x[2]+y[
golang中陣列和切片的區別與聯絡
golang中陣列和切片的區別: 切片時指標型別,陣列是值型別 陣列的長度是固定的,而切片不是(切片是動態的陣列) 切片比陣列多一個屬性:容量(cap) 切片的底層是陣列 既然一個是指標型別,一個是
Haddoop中的hdfs、hbase、 hive區別與聯絡
Hive: Hive不支援更改資料的操作,Hive基於資料倉庫,提供靜態資料的動態查詢。其使用類SQL語言,底層經過編譯轉為MapReduce程式,在Hadoop上執行,資料儲存在HDFS上。 HDFS: HDFS是GFS的一種實現
python3 中的 urllib模組和python2的區別與聯絡
3.0版本中已經將urllib2、urlparse、和robotparser併入了urllib中,並且修改urllib模組,其中包含5個子模組,即是help()中看到的那五個名字。 為了今後使用方便,在此將每個包中包含的方法列舉如下: urllib.error:
Qt/C++工作筆記-對vector與QVector中erase操作的進一步認識(區別與聯絡)
VS程式碼如下:#include <iostream> #include <vector> using namespace std; void main(){ vector<int> intVec; for (int i = 0;
詳解Linux系統中軟連線和硬連結的區別與聯絡
Linux 系統中有軟連線和硬連結兩種特殊的“檔案”。 其中軟連線實際上可以看作是Windows中的快捷方式,而硬連結則可以看作類似於一個檔案的 “指標”(也不完全相同) 。 建立方法都很簡單: 1. 軟連線(符號連結) ln -s source target 2
資料庫與資料倉庫的區別與聯絡
資料庫是面向事務的設計,資料倉庫是面向主題設計的。資料庫一般儲存線上交易資料,資料倉庫儲存的一般是歷史資料。 資料庫是面向事務的設計,資料倉庫是面向主題設計的。資料庫一般儲存線上交易資料,資料倉庫儲存的一般是歷史資料。資料庫設計是儘量避免冗餘,一般採用符合正規化的規則來設計
R中陣列、矩陣、資料框有什麼區別
翻譯R in aNutshell的句子 (詳見書中p22-p24): 一個數組是一個多維的向量 (我想 一維陣列==向量) > a <- array(c(1,2,3,4,5,6,7,8,9,10,11,12),dim=c(3,4)) #二維陣列 一個矩陣只是一
【R語言資料型別】深入瞭解 向量、矩陣、資料框、列表
R語言資料型別有向量、矩陣、資料框、列表。下面我們來深入瞭解下: vector 的劃分 R中的vector分為兩類,atomic和list,二者的區別在於,前者元素型別必須相同,後者可以不同。前者的代表是向量和矩陣,後者的代表是list和資料框。 建立
R語言中的資料框合併
#兩個資料框有相同和不同列----合併 ID<-c(1,2,3,4) name<-c("A","B","C","D") score<-c(60,70,80,90) student1<-data.frame(ID,name) student2<-
R語言中的列表和資料框
一、列表# --列表 #列表是一種特殊的物件集合,跟陣列一樣,他的元素也有序號確定,但是不同點在於可以存在不同型別的元素。 Lst<-list(name="Fred",no.children=3,wife="Lucy",children.ages=c(4,7,9))
R語言中矩陣、向量在記憶體上的區別
向量 在初始建立時,系統就給分配了足夠的空間,沒有賦值的下標對應的值都用NA代替了,所以向量不存在下標超出的限制比如: > x [1] 1 2 > length(x) [1] 2 > x[100] [1] NA > length(x)
R語言中的資料結構
R語言中的資料結構 文字中對R語言中的資料結構進行總結,以說明和舉例的方式展現出來! 主要包含:向量,陣列,列表,資料框,因子,矩陣,和一些常用函式。 注:以下程式碼均可直接執行! 1、向量 向量,用於儲存數值型,字元型,邏輯型資料的一維陣列 同一向量中無法混雜不同模式的資料
R語言中的資料探勘演算法
R是用於統計分析、繪圖的語言和操作環境。R是屬於GNU系統的一個自由、免費、原始碼開放的軟體,它是一個用於統計計算和統計製圖的優秀工具。
R語言中的資料篩選索引
data_select Xiaojia Zhang R中資料篩選方法綜述 利用整數下標形式索引 x=c(1:10) x ## [1] 1 2 3 4 5 6 7 8 9 10 x[4] ## [1] 4 x[1:3] ## [1] 1 2 3 x[-3] ##